两种常见的缓存淘汰算法LFU&LRU
1. LFU
1.1. 原理
LFU(Least Frequently Used)算法根据数据的历史访问频率来淘汰数据,其核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。
1.2. 实现
LFU的每个数据块都有一个引用计数,所有数据块按照引用计数排序,具有相同引用计数的数据块则按照时间排序。
具体实现如下:
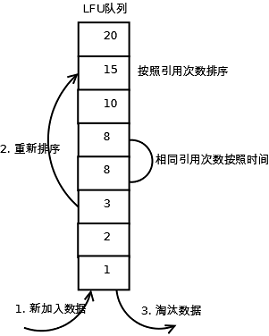
1. 新加入数据插入到队列尾部(因为引用计数为1);
2. 队列中的数据被访问后,引用计数增加,队列重新排序;
3. 当需要淘汰数据时,将已经排序的列表最后的数据块删除。
1.3. 分析
l 命中率
一般情况下,LFU效率要优于LRU,且能够避免周期性或者偶发性的操作导致缓存命中率下降的问题。但LFU需要记录数据的历史访问记录,一旦数据访问模式改变,LFU需要更长时间来适用新的访问模式,即:LFU存在历史数据影响将来数据的“缓存污染”效用。
l 复杂度
需要维护一个队列记录所有数据的访问记录,每个数据都需要维护引用计数。
l 代价
需要记录所有数据的访问记录,内存消耗较高;需要基于引用计数排序,性能消耗较高。
2. LRU
2.1. 原理
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
2.2. 实现
最常见的实现是使用一个链表保存缓存数据,详细算法实现如下:
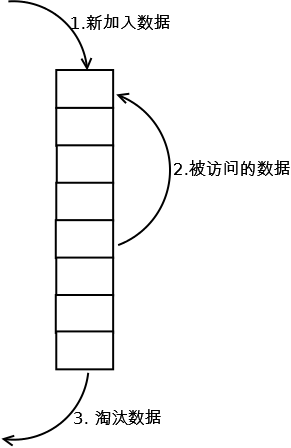
1. 新数据插入到链表头部;
2. 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
3. 当链表满的时候,将链表尾部的数据丢弃。
2.3. 分析
【命中率】
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
【复杂度】
实现简单。
【代价】
命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部。
3. LRU-K
3.1. 原理
LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
3.2. 实现
相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。只有当数据的访问次数达到K次的时候,才将数据放入缓存。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。详细实现如下:
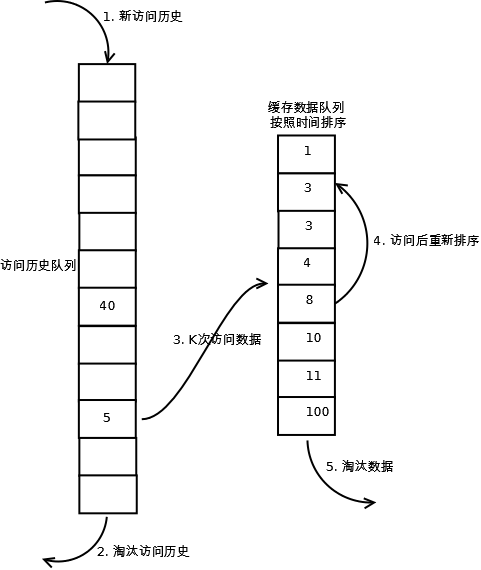
1. 数据第一次被访问,加入到访问历史列表;
2. 如果数据在访问历史列表里后没有达到K次访问,则按照一定规则(FIFO,LRU)淘汰;
3. 当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;
4. 缓存数据队列中被再次访问后,重新排序;
5. 需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
LRU-K具有LRU的优点,同时能够避免LRU的缺点,实际应用中LRU-2是综合各种因素后最优的选择,LRU-3或者更大的K值命中率会高,但适应性差,需要大量的数据访问才能将历史访问记录清除掉。
3.3. 分析
【命中率】
LRU-K降低了“缓存污染”带来的问题,命中率比LRU要高。
【复杂度】
LRU-K队列是一个优先级队列,算法复杂度和代价比较高。
【代价】
由于LRU-K还需要记录那些被访问过、但还没有放入缓存的对象,因此内存消耗会比LRU要多;当数据量很大的时候,内存消耗会比较可观。
LRU-K需要基于时间进行排序(可以需要淘汰时再排序,也可以即时排序),CPU消耗比LRU要高。
两种常见的缓存淘汰算法LFU&LRU的更多相关文章
- 两种缓存淘汰算法LFU&LRU
LRU全称是Least Recently Used,即最近最久未使用的意思. LRU算法的设计原则是:如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小.也就是说,当限定的空间已 ...
- 缓存淘汰算法之LRU
1. LRU1.1. 原理 LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”. ...
- 缓存淘汰算法之LRU实现
Java中最简单的LRU算法实现,就是利用 LinkedHashMap,覆写其中的removeEldestEntry(Map.Entry)方法即可 如果你去看LinkedHashMap的源码可知,LR ...
- 图解缓存淘汰算法二之LFU
1.概念分析 LFU(Least Frequently Used)即最近最不常用.从名字上来分析,这是一个基于访问频率的算法.与LRU不同,LRU是基于时间的,会将时间上最不常访问的数据淘汰;LFU为 ...
- 昨天面试被问到的 缓存淘汰算法FIFO、LRU、LFU及Java实现
缓存淘汰算法 在高并发.高性能的质量要求不断提高时,我们首先会想到的就是利用缓存予以应对. 第一次请求时把计算好的结果存放在缓存中,下次遇到同样的请求时,把之前保存在缓存中的数据直接拿来使用. 但是, ...
- 04 | 链表(上):如何实现LRU缓存淘汰算法?
今天我们来聊聊“链表(Linked list)”这个数据结构.学习链表有什么用呢?为了回答这个问题,我们先来讨论一个经典的链表应用场景,那就是+LRU+缓存淘汰算法. 缓存是一种提高数据读取性能的技术 ...
- 数据结构与算法之美 06 | 链表(上)-如何实现LRU缓存淘汰算法
常见的缓存淘汰策略: 先进先出 FIFO 最少使用LFU(Least Frequently Used) 最近最少使用 LRU(Least Recently Used) 链表定义: 链表也是线性表的一种 ...
- 链表:如何实现LRU缓存淘汰算法?
缓存淘汰策略: FIFO:先入先出策略 LFU:最少使用策略 LRU:最近最少使用策略 链表的数据结构: 可以看到,数组需要连续的内存空间,当内存空间充足但不连续时,也会申请失败触发GC,链表则可 ...
- 《数据结构与算法之美》 <04>链表(上):如何实现LRU缓存淘汰算法?
今天我们来聊聊“链表(Linked list)”这个数据结构.学习链表有什么用呢?为了回答这个问题,我们先来讨论一个经典的链表应用场景,那就是 LRU 缓存淘汰算法. 缓存是一种提高数据读取性能的技术 ...
随机推荐
- 洛谷P2051 中国象棋
题目描述 这次小可可想解决的难题和中国象棋有关,在一个N行M列的棋盘上,让你放若干个炮(可以是0个),使得没有一个炮可以攻击到另一个炮,请问有多少种放置方法.大家肯定很清楚,在中国象棋中炮的行走方式是 ...
- Servlet身份验证过滤器
文件:index.html 文件:MyFilter.java 文件:MyServlet.java 文件:web.xml
- hdu1403 后缀数组
比较简单的应用. #include <stdio.h> #include <string.h> #define maxn 200002 int wa[maxn],wb[maxn ...
- 2019-6-23-WPF-网络-request-的-read-方法不会返回
title author date CreateTime categories WPF 网络 request 的 read 方法不会返回 lindexi 2019-06-23 11:26:26 +08 ...
- Tcp之双向通信
TestServer.java package com.sxt.tcp; /* * 服务端 */ import java.io.DataInputStream; import java.io.Data ...
- qt开发ROS gui界面环境配置过程总结
这段时间花了点时间配置了在qtcreator5.9.1上开发ros gui界面的环境,终于可以实现导入工程,插断点调试了.总结起来需要注意以下几点: 1.安装插件ros_qtc_plugin,ROS与 ...
- 『PyTorch』第十一弹_torch.optim优化器 每层定制参数
一.简化前馈网络LeNet 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 im ...
- hadoop2.6.0 + hbase-1.0.0 伪分布配置
1 基本配置 主机名: 192.168.145.154 hadoop2 ======= 2 etc/hadoop下文件配置 1)core-site.xml <configuration> ...
- SuperSocket AppServer 的两个事件: NewSessionConnected 和 SessionClosed
订阅事件: appServer.NewSessionConnected += new SessionHandler<AppSession>(appServer_NewSessionConn ...
- js保存图片到手机相册
/保存到相册 function savePic(){ var picurl= $("#picurl").attr("src"); //alert(picurl) ...