两种常见的缓存淘汰算法LFU&LRU
1. LFU
1.1. 原理
LFU(Least Frequently Used)算法根据数据的历史访问频率来淘汰数据,其核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。
1.2. 实现
LFU的每个数据块都有一个引用计数,所有数据块按照引用计数排序,具有相同引用计数的数据块则按照时间排序。
具体实现如下:
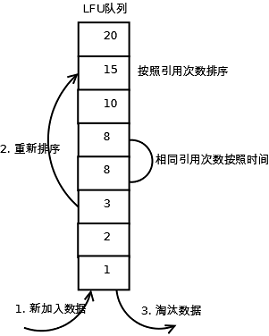
1. 新加入数据插入到队列尾部(因为引用计数为1);
2. 队列中的数据被访问后,引用计数增加,队列重新排序;
3. 当需要淘汰数据时,将已经排序的列表最后的数据块删除。
1.3. 分析
l 命中率
一般情况下,LFU效率要优于LRU,且能够避免周期性或者偶发性的操作导致缓存命中率下降的问题。但LFU需要记录数据的历史访问记录,一旦数据访问模式改变,LFU需要更长时间来适用新的访问模式,即:LFU存在历史数据影响将来数据的“缓存污染”效用。
l 复杂度
需要维护一个队列记录所有数据的访问记录,每个数据都需要维护引用计数。
l 代价
需要记录所有数据的访问记录,内存消耗较高;需要基于引用计数排序,性能消耗较高。
2. LRU
2.1. 原理
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
2.2. 实现
最常见的实现是使用一个链表保存缓存数据,详细算法实现如下:
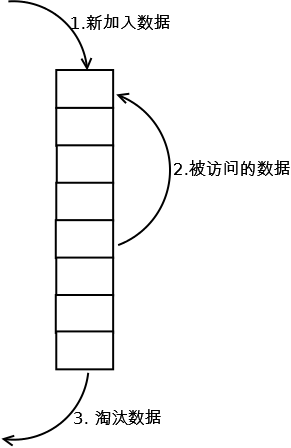
1. 新数据插入到链表头部;
2. 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
3. 当链表满的时候,将链表尾部的数据丢弃。
2.3. 分析
【命中率】
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
【复杂度】
实现简单。
【代价】
命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部。
3. LRU-K
3.1. 原理
LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
3.2. 实现
相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。只有当数据的访问次数达到K次的时候,才将数据放入缓存。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。详细实现如下:
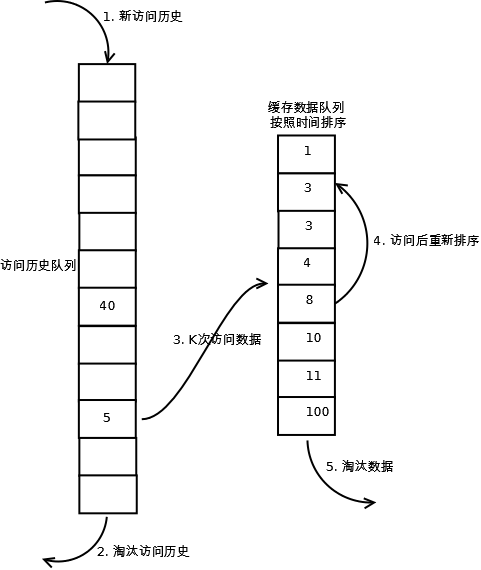
1. 数据第一次被访问,加入到访问历史列表;
2. 如果数据在访问历史列表里后没有达到K次访问,则按照一定规则(FIFO,LRU)淘汰;
3. 当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;
4. 缓存数据队列中被再次访问后,重新排序;
5. 需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
LRU-K具有LRU的优点,同时能够避免LRU的缺点,实际应用中LRU-2是综合各种因素后最优的选择,LRU-3或者更大的K值命中率会高,但适应性差,需要大量的数据访问才能将历史访问记录清除掉。
3.3. 分析
【命中率】
LRU-K降低了“缓存污染”带来的问题,命中率比LRU要高。
【复杂度】
LRU-K队列是一个优先级队列,算法复杂度和代价比较高。
【代价】
由于LRU-K还需要记录那些被访问过、但还没有放入缓存的对象,因此内存消耗会比LRU要多;当数据量很大的时候,内存消耗会比较可观。
LRU-K需要基于时间进行排序(可以需要淘汰时再排序,也可以即时排序),CPU消耗比LRU要高。
两种常见的缓存淘汰算法LFU&LRU的更多相关文章
- 两种缓存淘汰算法LFU&LRU
LRU全称是Least Recently Used,即最近最久未使用的意思. LRU算法的设计原则是:如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小.也就是说,当限定的空间已 ...
- 缓存淘汰算法之LRU
1. LRU1.1. 原理 LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”. ...
- 缓存淘汰算法之LRU实现
Java中最简单的LRU算法实现,就是利用 LinkedHashMap,覆写其中的removeEldestEntry(Map.Entry)方法即可 如果你去看LinkedHashMap的源码可知,LR ...
- 图解缓存淘汰算法二之LFU
1.概念分析 LFU(Least Frequently Used)即最近最不常用.从名字上来分析,这是一个基于访问频率的算法.与LRU不同,LRU是基于时间的,会将时间上最不常访问的数据淘汰;LFU为 ...
- 昨天面试被问到的 缓存淘汰算法FIFO、LRU、LFU及Java实现
缓存淘汰算法 在高并发.高性能的质量要求不断提高时,我们首先会想到的就是利用缓存予以应对. 第一次请求时把计算好的结果存放在缓存中,下次遇到同样的请求时,把之前保存在缓存中的数据直接拿来使用. 但是, ...
- 04 | 链表(上):如何实现LRU缓存淘汰算法?
今天我们来聊聊“链表(Linked list)”这个数据结构.学习链表有什么用呢?为了回答这个问题,我们先来讨论一个经典的链表应用场景,那就是+LRU+缓存淘汰算法. 缓存是一种提高数据读取性能的技术 ...
- 数据结构与算法之美 06 | 链表(上)-如何实现LRU缓存淘汰算法
常见的缓存淘汰策略: 先进先出 FIFO 最少使用LFU(Least Frequently Used) 最近最少使用 LRU(Least Recently Used) 链表定义: 链表也是线性表的一种 ...
- 链表:如何实现LRU缓存淘汰算法?
缓存淘汰策略: FIFO:先入先出策略 LFU:最少使用策略 LRU:最近最少使用策略 链表的数据结构: 可以看到,数组需要连续的内存空间,当内存空间充足但不连续时,也会申请失败触发GC,链表则可 ...
- 《数据结构与算法之美》 <04>链表(上):如何实现LRU缓存淘汰算法?
今天我们来聊聊“链表(Linked list)”这个数据结构.学习链表有什么用呢?为了回答这个问题,我们先来讨论一个经典的链表应用场景,那就是 LRU 缓存淘汰算法. 缓存是一种提高数据读取性能的技术 ...
随机推荐
- 设置onselectstart在ie浏览器下对于input及textarea标签页会生效
设置onselectstart在ie浏览器下对于input及textarea标签页会生效, 可以使用js来控制对于某种标签不生效,代码如下: document.onselectstart = disa ...
- Introduction to 3D Game Programming with DirectX 12 学习笔记之 --- 第一章:向量代数
原文:Introduction to 3D Game Programming with DirectX 12 学习笔记之 --- 第一章:向量代数 学习目标: 学习如何使用几何学和数字描述 Vecto ...
- char和achar互转
#pragma once#include "stdafx.h" #ifndef _Convert_H_#define _Convert_H_ //定义转换类class Conver ...
- SED总结, mac上要加备份文件名,sort命令和对中文的处理
使用sed批量改文件名 Sed批量去拓展名 |- dev.gb.conll06.raw |- test.gb.conll06.raw |- train.gb.conll06.raw 想要去掉其中的后缀 ...
- java对象转化为json字符串并传到前台
package cc.util; import java.util.ArrayList; import java.util.Date; import java.util.HashMap; import ...
- 2018-7-5-dotnet-设计规范-·-抽象定义
title author date CreateTime categories dotnet 设计规范 · 抽象定义 lindexi 2018-07-05 15:48:20 +0800 2018-2- ...
- Android 使用Toolbar+DrawerLayout快速实现仿“知乎APP”侧滑导航效果
在以前,做策划导航的时候,最常用的组件便是SlidingMenu了,当初第一次用它的时候觉得那个惊艳啊,体验可以说是非常棒. 后来,Android自己推出了一个可以实现策划导航的组件DrawerLay ...
- mysql 中 DATE_ADD函数和 DATE_SUB函数用法
mysql 中 DATE_ADD(date,INTERVAL expr type) 和 DATE_SUB(date,INTERVAL expr type) 这些函数执行日期运算. date 是一个 D ...
- oralce函数 next_day(d1[,c1])
[功能]:返回日期d1在下周,星期几(参数c1)的日期 [参数]:d1日期型,c1为字符型(参数),c1默认为j(即当前日期) [参数表]:c1对应:星期一,星期二,星期三……星期日 [返回]:日期 ...
- oracle函数 userenv(parameter)
[功能]返回当前会话上下文属性. [参数]Parameter是参数,可以用以下参数代替: Isdba:若用户具有dba权限,则返回true,否则返回false. Language:返回当前会话对应的语 ...