OCR2:tesseract字库训练
由于tesseract的中文语言包“chi_sim”对中文字体或者环境比较复杂的图片,识别正确率不高,因此需要针对特定情况用自己的样本进行训练,提高识别率,通过训练,也可以形成自己的语言库。
工具:
Java虚拟机,由于jTessBoxEditor的运行依赖Java运行时环境,所以需要安装Java虚拟机。下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
jTessBoxEditor2.0工具,用于调整图片上文字的内容和位置,下载地址:https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
- 安装包解压后双击里边的“jTessBoxEditor.jar”,或者双击该目录下的“train.bat”脚本文件,就可以打开该工具了
第一步:合成图片集
- 打开jTessBoxEditor,选择 Tools->Merge TIFF,进入训练样本所在文件夹,选中要参与训练的样本图片:进行训练的样本图片数量越多越好
点击 “打开” 后弹出保存对话框,选择保存在当前路径下,文件命名为: “demo.test.exp0.tif” ,格式只有一种 “TIFF” 可选。
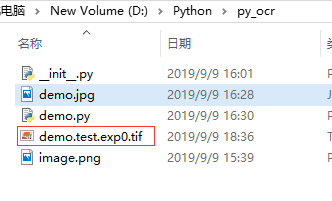
- tif文面命名格式:[lang].[fontname].exp[num].tif
- lang:是语言,fontname:是字体,num:为自定义数字。
- 比如我们要训练自定义字库 demo,字体名 test,那么我们把图片文件命名为 demo.test.exp0.tif
第二步:生成box文件
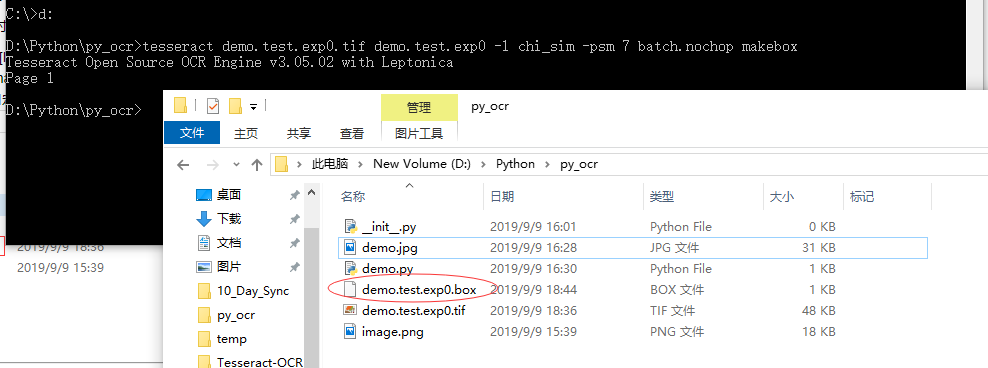
- 在上一步骤生成的 .tif 文件所在目录下打开命令行程序,执行下面命令,执行完之后会生成 .box文件, .BOX文件为Tessercat识别出的文字和其坐标。
- 命令:tesseract demo.test.exp0.tif demo.test.exp0 -l chi_sim -psm 7 batch.nochop makebox
第三步:矫正.box文件的错误
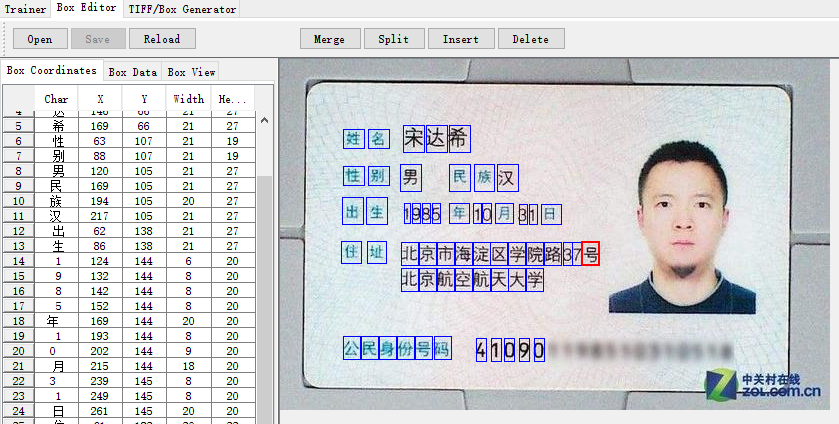
- .box文件记录了每个字符在图片上的位置和识别出的内容,训练前需要使用jTessBoxEditor调整字符的位置和内容。(注:图片dpi > 300 时效果更好)
- 打开jTessBoxEditor点击Box Editor ->Open,打开步骤2中生成的 .tif,会自动关联到 .box 文件,这两文件要求在同一目录下。调整完点击“save”保存修改。
第四步:生成font_properties文件(该文件没有后缀名)
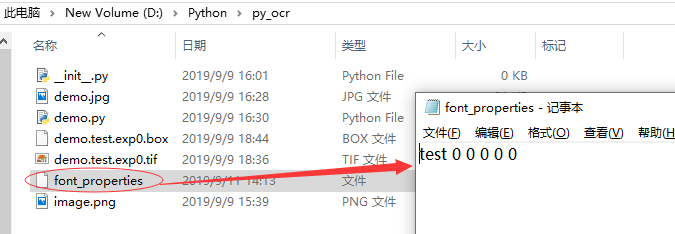
- 执行命令,会在当前目录生成font_properties文件,命令:echo test 0 0 0 0 0 >font_properties
- 执行完成之后,在当前文件夹下生成font_properties文件
也可以手动在该文件夹下建立一个名为 “font_properties” 的文件,这个文件没有后缀名称,输入内容 “font 0 0 0 0 0” , 表示字体 font 的粗体、倾斜等共计5个属性全都设置为0。注意 : 这里输入的 “font” 名称必须与 “demo.test.exp0.box” 中两个点号之间的 “test” 名称保持一致。
第五步:生成.tr训练文件
- 执行生成 demo.test.exp0.tr 文件,命令:tesseract demo.test.exp0.tif demo.test.exp0 nobatch box.train

第六步:生成字符集文件
- 执行命令,生成一个名为“unicharset”的文件;命令:unicharset_extractor demo.test.exp0.box

第七步:生成shape文件
- 执行命令,生成 shapetable 和 demo.unicharset 两个文件。命令:shapeclustering -F font_properties -U unicharset -O demo.unicharset demo.test.exp0.tr

第八步:生成聚字符特征文件
- 执行命令,会生成 inttemp、pffmtable、shapetable和demo.unicharset四个文件。命令:mftraining -F font_properties -U unicharset -O demo.unicharset demo.test.exp0.tr

第九步:生成字符正常化特征文件
- 执行命令,生成 normproto 文件。命令:cntraining demo.test.exp0.tr

第十步:文件重命名
- 重新命名inttemp、pffmtable、shapetable和normproto这四个文件的名字为[lang].xxx。这里修改为demo.inttemp、demo.pffmtable、demo.shapetable和demo.normproto
rename normproto demo.normproto
rename inttemp demo.inttemp
rename pffmtable demo.pffmtable
rename shapetable demo.shapetable
rename unicharset demo.unicharset
第十一步:合并训练文件
- 执行下面命令,会生成demo.traineddata文件。命令:combine_tessdata demo.
- 将生成的“demo.traineddata”语言包文件复制到Tesseract-OCR 安装目录下的tessdata文件夹中,就可以使用训练生成的语言包进行图像文字识别了。
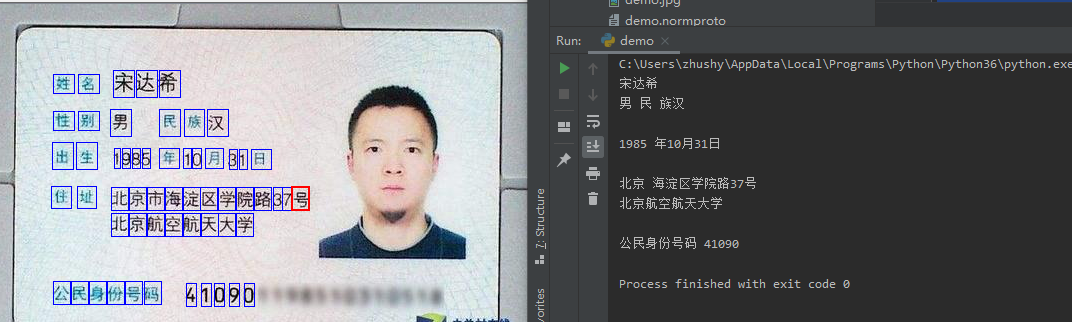
测试
import pytesseract
from PIL import Image as img class Languages:
CHS = 'chi_sim'
CHT = 'chi_tra'
ENG = 'eng'
DM = 'demo' text = pytesseract.image_to_string(img.open('demo.jpg'), lang=Languages.DM)
print(text)
参考资料:
- https://blog.csdn.net/a745233700/article/details/80175883
- https://blog.csdn.net/qq_37674858/article/details/80340914
OCR2:tesseract字库训练的更多相关文章
- tesseract 字体训练资料篇
tesseract 字体训练资料篇 1.制作.box档案文件. tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] ...
- Tesseract识别图片提取文字&字库训练
文中测试了3.0和4.0两个版本.发现3.0识别效率不准确,需要训练词库.4.0识别效率就比较高了,而且支持结果生成pdf.txt等格式.所以推荐使用4.0版本. 这个工具可以用在爬虫的时候获取验证码 ...
- tesseract-ocr字库训练图文讲解
第一步合成图片集 你需要把使用jTessBoxEditor工具把你的训练素材及多张图片合并成一张tif格式的图片集 第二步 生成box文件 运行tesseract命令,tesseract mjorc ...
- 【Tesseract】Tesseract 的训练流程
在泰迪杯A题中,我刚刚接触了Tesseact,其中训练字库中遇到了较多的问题.所以在此记录一下,也当做一个笔记,省得以后忘记. 为了方便 ,将tif命名格式设为[lang].[fontname].ex ...
- tesseract ocr训练 pt验证码
识别率有问题A大概率识别为n,因此需要训练,这里讲一下 如何训练 参考 java代码里边直接使用tess4j,是对tesseract的封装,但是如果要训练,还是需要在进行安装tesseract-ocr ...
- Tesseract训练
最近在用Tesseract做一个图片识别的小应用,目标图像只有数字和英文字母,在实际使用过程中发现个别数识别错误,因此不得不研究学习Tesseract的训练. http://www.cnblogs.c ...
- tesseract-ocr如何训练Tesseract 4.0
引自:https://blog.csdn.net/huobanjishijian/article/details/76212214 原文:https://github.com/tesseract-oc ...
- Tesseract训练中文字体识别
注:目前仅说明windows下的情况 前言 网上已经有大量的tesseract的识别教程,但是主要有两个缺点: 大多数比较老,有部分内容已经不适用. 大部分只是就英文的训练进行探索,很少针对中文的训练 ...
- jTessBoxEditor工具进行Tesseract3.02.02样本训练
1.背景 前文已经简要介绍tesseract ocr引擎的安装及基本使用,其中提到使用-l eng参数来限定语言库,可以提高识别准确率及识别效率. 本文将针对某个网站的验证码进行样本训练,形成自己的语 ...
随机推荐
- Directory traversal
Find the hidden section of the photo galery. 找到相册的隐藏部分. 直接能够目录遍历: 虽然galerie禁止访问,但是密码就在里面----直接爆破或者爬虫 ...
- 【Linux】netstat命令
https://www.cnblogs.com/ftl1012/p/netstat.html这个讲的不错 https://www.linuxprobe.com/netstat-common-metho ...
- B 题解————2019.10.16
相信他说的话,但不要当真 [题目描述]有一个长度为 n 的自然数序列 a,要求将这个序列恰好分成至少 m 个连续子段. 每个子段的价值为该子段的所有数的按位异或.要使所有子段的价值按位与的结果最大,输 ...
- Codeforces Round 564 题解
很抱歉让标题把您骗进来了. 这是一场打得最失败的div1. 作为一个橙名一题都不会…… 旁边紫名的PB怒切3题,div2的也随便玩玩出了div1b/div2d…… 这名字颜色也太有水分了. 也就只会2 ...
- Spring Boot 知识笔记(整合Mybatis)
一.pom.xml中添加相关依赖 <!-- 引入starter--> <dependency> <groupId>org.mybatis.spring.boot&l ...
- GPS和LOAM的pose之间建立edge
基于时间戳一致原理,在与PG的timestamp邻近的的两个LOAM的pose中插值出一个虚拟的LOAM pose PG' ,其timestamp = PG的timestamp. 然后GPS的pose ...
- YYCache 的整体架构类图

- 026 Elastic----全文检索技术01---概述及windows安装
用户访问我们的首页,一般都会直接搜索来寻找自己想要购买的商品.而商品的数量非常多,而且分类繁杂.如何能正确的显示出用户想要的商品,并进行合理的过滤,尽快促成交易,是搜索系统要研究的核心.面对这样复杂的 ...
- Lua table的remove函数
[1]remove函数简介 table.remove(table, pos): 返回table数组中位于pos位置的元素,其后的元素会被前移. pos参数可选, 默认为table长度, 即从最后一个元 ...
- Django框架之DRF 认证组件源码分析、权限组件源码分析、频率组件源码分析
认证组件 权限组件 频率组件