分布式ID生成总结
1.数据库自增id
新建一个公共库,库里面新建一个序列表,主键id自增,每次请求增加数据都往这个表中插入数据,然后获取到id,然后使用即可。
优点:方便简单
缺点:单库生成自增id,高并发下,会有瓶颈
适用场景:
并发很低,几百/s,不会出现性能瓶颈
2.UUID
优点:本地生成,不基于任何第三方
缺点:
- 太长,作为数据库主键性能太差,不适合作为主键
- 不具有有序性,会导致B+树索引在写的时候有过多的随机写操作(连续的id可以产生部分顺序写)
- 写的时候不能产生有顺序的 append 操作,而需要进行 insert 操作,将会读取整个 B+ 树节点到内存,在插入这条记录后会将整个节点写回磁盘,这种操作在记录占用空间比较大的情况下,性能下降明显
适用场景:
随机生成文件名、编号,生成token等。
3.系统时间+拼接业务字段值
例如:当前时间戳 + 用户id + 业务含义编码,并发高的时候,会有重复,此时就不行了,不建议使用。
4.Redis
Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。
优点:
- 不依赖于数据库,灵活方便,且性能优于数据库。
- 数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
- 由于redis是内存的KV数据库,即使有AOF和RDB,但是依然会存在数据丢失,有可能会造成ID重复。
- 依赖于redis,redis要是不稳定,会影响ID生成。
5.snowflake算法
twitter开源的分布式id生成算法,把一个64位的long型的id,1个bit是不用的,用其中的41 bit作为毫秒数,用10 bit作为工作机器id,12 bit作为序列号,理论上最多支持1024台机器每秒生成4096000个序列号。
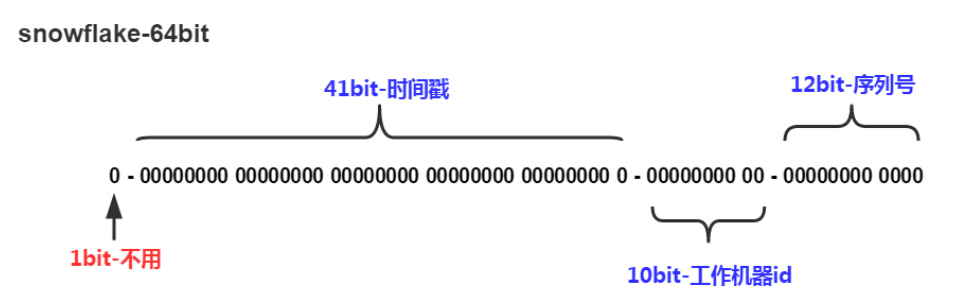
- 1 bit:不用
因为二进制里第一个bit为如果是1,那么都是负数,但是我们生成的id都是正数,所以第一个bit统一都是0 - 41 bit:表示的是时间戳,单位是ms
41 bit可以表示的数字多达2^41 - 1,也就是可以标识2 ^ 41 - 1个毫秒值,换算成年就是表示69年的时间 - 10 bit:记录工作机器id
代表的是这个服务最多可以部署在2^10台机器上哪,也就是1024台机器,但是10 bit里5个bit代表机房id,5个bit代表机器id。意思就是最多代表2 ^ 5个机房(32个机房),每个机房里可以代表2 ^ 5个机器(32台机器)。 - 12 bit:记录同一个毫秒内产生的不同id
12 bit可以代表的最大正整数是2 ^ 12 - 1 = 4096,也就是说可以用这个12bit代表的数字来区分同一个毫秒内的4096个不同的id
缺点:
依赖于系统时钟的一致性。如果某台机器的系统时钟回拨,有可能造成ID冲突,或者ID乱序、ID重复
优点:
- 生成ID时不依赖于数据库,完全在内存生成,高性能高可用
- 容量大,每秒可生成几百万ID
- ID呈趋势递增,后续插入数据库的索引树的时候,性能较高
分布式ID生成总结的更多相关文章
- 一种基于Orleans的分布式Id生成方案
基于Orleans的分布式Id生成方案,因Orleans的单实例.单线程模型,让这种实现变的简单,贴出一种实现,欢迎大家提出意见 public interface ISequenceNoGenerat ...
- 细聊分布式ID生成方法
细聊分布式ID生成方法 https://mp.weixin.qq.com/s?__biz=MjM5ODYxMDA5OQ==&mid=403837240&idx=1&sn=ae9 ...
- spring boot / cloud (十六) 分布式ID生成服务
spring boot / cloud (十六) 分布式ID生成服务 在几乎所有的分布式系统或者采用了分库/分表设计的系统中,几乎都会需要生成数据的唯一标识ID的需求, 常规做法,是使用数据库中的自动 ...
- Leaf——美团点评分布式ID生成系统 UUID & 类snowflake
Leaf——美团点评分布式ID生成系统 https://tech.meituan.com/MT_Leaf.html
- 分布式ID生成系统 UUID与雪花(snowflake)算法
Leaf——美团点评分布式ID生成系统 -https://tech.meituan.com/MT_Leaf.html 网游服务器中的GUID(唯一标识码)实现-基于snowflake算法-云栖社区-阿 ...
- Leaf:美团分布式ID生成服务开源
Leaf是美团基础研发平台推出的一个分布式ID生成服务,名字取自德国哲学家.数学家莱布尼茨的一句话:“There are no two identical leaves in the world.”L ...
- 分布式ID生成方法-趋势有序的全局唯一ID
一.需求缘起 几乎所有的业务系统,都有生成一个记录标识的需求,例如: (1)消息标识:message-id (2)订单标识:order-id (3)帖子标识:tiezi-id 这个记录标识往往就是数据 ...
- 【58沈剑架构系列】细聊分布式ID生成方法
一.需求缘起 几乎所有的业务系统,都有生成一个记录标识的需求,例如: (1)消息标识:message-id (2)订单标识:order-id (3)帖子标识:tiezi-id 这个记录标识往往就是数据 ...
- 分布式ID生成方案
系统唯一ID是设计一个系统的时候常常会遇到的问题,也常常为这个问题而纠结. 生成ID的方法有很多,适应不同的场景.需求以及性能要求.所以有些比较复杂的系统会有多个ID生成的策略. 0. 分布式ID要求 ...
- 160302、细聊分布式ID生成方法
一.需求缘起 几乎所有的业务系统,都有生成一个记录标识的需求,例如: (1)消息标识:message-id (2)订单标识:order-id (3)帖子标识:tiezi-id 这个记录标识往往就是数据 ...
随机推荐
- 2019年杭电多校第二场 1012题Longest Subarray(HDU6602+线段树)
题目链接 传送门 题意 要你找一个最长的区间使得区间内每一个数出现次数都大于等于\(K\). 思路 我们通过固定右端点考虑每个左端点的情况. 首先对于每个位置,我们用线段树来维护它作为\(C\)种元素 ...
- c#每天生成漂亮桌面背景、英文名言、翻译
阅读目录 一.1. 下载bing.com壁纸查询API 二.2. 解析返回的壁纸JSON信息 三.3. 下载完成的壁纸图片 阅读目录 .NET生成漂亮桌面背景 .NET生成漂亮桌面背景 总结 回到目录 ...
- linux定时任务(转)
转自:https://www.cnblogs.com/intval/p/5763929.html linux 系统则是由 cron (crond) 这个系统服务来控制的.Linux 系统上面原本就有非 ...
- keepalived是什么及作用?
参考:https://www.cnblogs.com/hqjy/p/7615439.html keepalived介绍 keepalived观察其名可知,保持存活,在网络里面就是保持在线了, 也就是所 ...
- linux 打印当前工作目录
pwd
- Numpy | 04 数组属性
NumPy 数组的维数称为秩(rank),一维数组的秩为 1,二维数组的秩为 2,以此类推. 在 NumPy中,每一个线性的数组称为是一个轴(axis),也就是维度(dimensions).比如说,二 ...
- Wbbpack --3配置
Wbbpack --3配置 什么是webpack webpack 是一个现代 JavaScript 应用程序的静态模块打包(modulebundler)当 webpack 处理应用程序时,它会递归地构 ...
- 套接字编程简介: IPV4套接字地址结构/ 通用套接字地址结构/ IPV6套接字地址结构/新通用套接字地址结构
IPv4套接字地址结构通常也称为“网际套接字地址结构”,它以sockaddr_in命名,定义在<netinet/in.h>头文件中. struct in_addr { in_addr_t ...
- 洛谷 P4149 [IOI2011]Race-树分治(点分治,不容斥版)+读入挂-树上求一条路径,权值和等于 K,且边的数量最小
P4149 [IOI2011]Race 题目描述 给一棵树,每条边有权.求一条简单路径,权值和等于 KK,且边的数量最小. 输入格式 第一行包含两个整数 n, Kn,K. 接下来 n - 1n−1 行 ...
- [golang][gui]Hands On GUI Application Development in Go【在Go中动手进行GUI应用程序开发】读书笔记03-拒交“智商税”,解密“GUI”运行之道
和老外的原文好像没多大联系了,哈哈哈,反正是读书笔记,下面的内容也是我读此书中的历程,也写进来吧.不过说实话,这框架的作者还挺对我脾气的,哈哈哈. 拒交“智商税”,解密“GUI”运行之道 我很忙 项目 ...