【赵渝强老师】什么是Spark SQL?

一、Spark SQL简介
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用。
为什么要学习Spark SQL?我们已经学习了Hive,它是将Hive SQL转换成MapReduce然后提交到集群上执行,大大简化了编写MapReduce的程序的复杂性,由于MapReduce这种计算模型执行效率比较慢。所以Spark SQL的应运而生,它是将Spark SQL转换成RDD,然后提交到集群执行,执行效率非常快!同时Spark SQL也支持从Hive中读取数据。
二、Spark SQL的特点
- 无缝集成在Spark中,将SQL查询与Spark程序混合。Spark SQL允许您使用SQL或熟悉的DataFrame API在Spark程序中查询结构化数据。适用于Java、Scala、Python和R语言。
- 提供统一的数据访问,以相同的方式连接到任何数据源。DataFrames和SQL提供了一种访问各种数据源的通用方法,包括Hive、Avro、Parquet、ORC、JSON和JDBC。您甚至可以通过这些源连接数据。
- 支持Hive集成。在现有仓库上运行SQL或HiveQL查询。Spark SQL支持HiveQL语法以及Hive SerDes和udf,允许您访问现有的Hive仓库。
- 支持标准的连接,通过JDBC或ODBC连接。服务器模式为业务智能工具提供了行业标准JDBC和ODBC连接。
三、核心概念:DataFrames和Datasets
DataFrame
DataFrame是组织成命名列的数据集。它在概念上等同于关系数据库中的表,但在底层具有更丰富的优化。DataFrames可以从各种来源构建,例如:
- 结构化数据文件
- hive中的表
- 外部数据库或现有RDDs
DataFrame API支持的语言有Scala,Java,Python和R。

从上图可以看出,DataFrame多了数据的结构信息,即schema。RDD是分布式的 Java对象的集合。DataFrame是分布式的Row对象的集合。DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化。
Datasets
Dataset是数据的分布式集合。Dataset是在Spark 1.6中添加的一个新接口,是DataFrame之上更高一级的抽象。它提供了RDD的优点(强类型化,使用强大的lambda函数的能力)以及Spark SQL优化后的执行引擎的优点。一个Dataset 可以从JVM对象构造,然后使用函数转换(map, flatMap,filter等)去操作。 Dataset API 支持Scala和Java。 Python不支持Dataset API。
四、创建DataFrames
- 测试数据如下:员工表

- 定义case class(相当于表的结构:Schema)
case class Emp(empno:Int,ename:String,job:String,mgr:Int,hiredate:String,sal:Int,comm:Int,deptno:Int)
- 将HDFS上的数据读入RDD,并将RDD与case Class关联
val lines = sc.textFile("hdfs://bigdata111:9000/input/emp.csv").map(_.split(","))
- 把每个Array映射成一个Emp的对象
val emp = lines.map(x => Emp(x(0).toInt,x(1),x(2),x(3).toInt,x(4),x(5).toInt,x(6).toInt,x(7).toInt))
- 生成DataFrame
val allEmpDF = emp.toDF
- 通过DataFrames查询数据
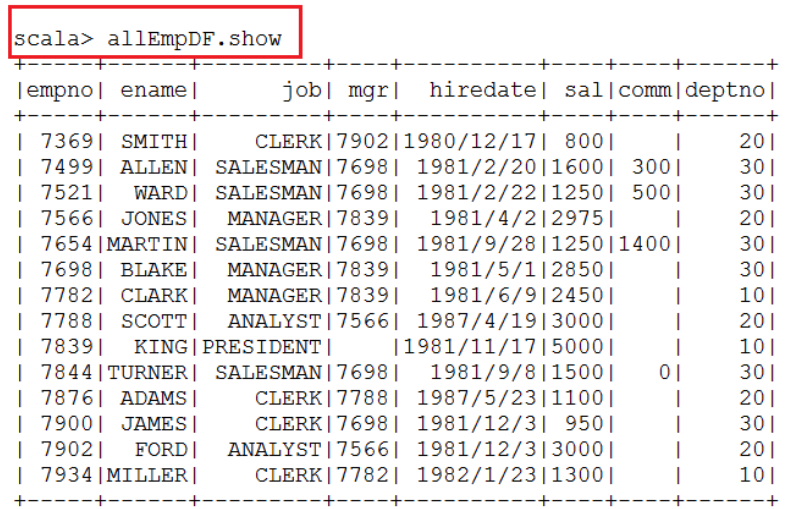
- 将DataFrame注册成表(视图)
allEmpDF.createOrReplaceTempView("emp")
- 执行SQL查询
spark.sql("select * from emp").show
【赵渝强老师】什么是Spark SQL?的更多相关文章
- 平易近人、兼容并蓄——Spark SQL 1.3.0概览
自2013年3月面世以来,Spark SQL已经成为除Spark Core以外最大的Spark组件.除了接过Shark的接力棒,继续为Spark用户提供高性能的SQL on Hadoop解决方案之外, ...
- 【转载】Spark SQL 1.3.0 DataFrame介绍、使用
http://www.aboutyun.com/forum.php?mod=viewthread&tid=12358&page=1 1.DataFrame是什么?2.如何创建DataF ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- 大数据技术之_19_Spark学习_03_Spark SQL 应用解析 + Spark SQL 概述、解析 、数据源、实战 + 执行 Spark SQL 查询 + JDBC/ODBC 服务器
第1章 Spark SQL 概述1.1 什么是 Spark SQL1.2 RDD vs DataFrames vs DataSet1.2.1 RDD1.2.2 DataFrame1.2.3 DataS ...
- Spark SQL中的Catalyst 的工作机制
Spark SQL中的Catalyst 的工作机制 答:不管是SQL.Hive SQL还是DataFrame.Dataset触发Action Job的时候,都会经过解析变成unresolved的逻 ...
- 1. Spark SQL概述
1.1 什么是Spark SQL Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用 它是将Hive SQL转换成 ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- Spark SQL源码解析(二)Antlr4解析Sql并生成树
Spark SQL原理解析前言: Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述 这一次要开始真正介绍Spark解析SQL的流程,首先是从Sql Parse阶段开始,简单点说, ...
- 第1章 Spark SQL概述
第1章 Spark SQL概述 1.1 什么是Spark SQL Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作 ...
- spark SQL (一)初识 ,简介
一, 简介 Spark SQL是用于结构化数据处理的Spark模块.与基本的Spark RDD API不同,Spark SQL提供的接口为Spark提供了关于数据结构和正在执行的计算的更多信息.在内部 ...
随机推荐
- 题解:P7482 不条理狂诗曲
题解:P7482 不条理狂诗曲 本题解借鉴 blossom_j 大佬思路,但这位大佬的题解似乎没放正确代码. 题意 对于每一个 \(a\) 的子区间 \(a_{l\dots r}\),求选择若干个不连 ...
- 如何立刻读取在MySQL中自动生成的主键
在写一个接口时,我们需要对两个表分别动刀,但是我们需要前一个表的主键作为下一个表的功能外键, 如果使用mybatisplus,insert完成之后便可以直接在对象中取出这个id值 如果使用mybati ...
- 2023/4/15 SCRUM个人博客
1.我昨天的任务 获得了人脸识别作弊检测和绘制界面的分工,准备先从作弊检测入手 2.遇到了什么困难 对作弊检测的组件不熟悉,进展缓慢,需要进行对点的学习 3.我今天的任务 初步学习cython
- Diffutoon下载介绍:真人视频转动漫工具,轻松获得上千点赞
最近在刷短视频的时候,偶尔能看到一些真人转动漫风的作品,看起来给人一种新鲜感,流量都还不错,简简单单跳个舞,就能获得上千个点赞~ 那么,这种视频是怎么制作的? 本期给大家介绍一款AI转绘工具Diffu ...
- 【Uni-App】关于获取手机系统信息的项目实践
原因是这里APP下载方式的问题 安卓 和 IOS都可以写A标签跳转访问附件资源 但是甲方对这种下载方式并8满意[安卓行 苹果8行, 苹果行,安卓又8行] 通过 uni.getSystemInfo来判断 ...
- NVIDIA的Isaac AMR产品介绍
NVIDIA的Isaac AMR是仓库自动运货机器人项目,说直白些就是一个AGV的小车,不过和传统的AGV不同,NVIDIA推出的这个产品是智能化的.传统AGV小车的运行代码都是写死的,直接把运行命令 ...
- 论文《policy-gradient-methods-for-reinforcement-learning-with-function-approximation 》的阅读——强化学习中的策略梯度算法基本形式与部分证明
最近组会汇报,由于前一阵听了中科院的教授讲解过这篇论文,于是想到以这篇论文为题做了学习汇报.论文<policy-gradient-methods-for-reinforcement-learni ...
- 在国产超算平台上(aarch64架构)安装pytorch-cuda失败,究其原因竟是官方未提供对应的cuda版本——pip方式和conda方式均无法获得相应cuda版本
最近在国产超算平台上安装pytorch,但是怎么弄都会报错: raise AssertionError("Torch not compiled with CUDA enabled" ...
- baselines中环境包装器EpisodicLifeEnv的分析
如题: class EpisodicLifeEnv(gym.Wrapper): def __init__(self, env): """Make end-of-life ...
- abc366-cnblog
[E](E - Manhattan Multifocal Ellipse (atcoder.jp)) 解题思路 这题求的是满足\(\sum^n_{i=1}(|x-x_i|+|y-y_i|)\leq D ...