【赵渝强老师】什么是Spark SQL?

一、Spark SQL简介
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用。
为什么要学习Spark SQL?我们已经学习了Hive,它是将Hive SQL转换成MapReduce然后提交到集群上执行,大大简化了编写MapReduce的程序的复杂性,由于MapReduce这种计算模型执行效率比较慢。所以Spark SQL的应运而生,它是将Spark SQL转换成RDD,然后提交到集群执行,执行效率非常快!同时Spark SQL也支持从Hive中读取数据。
二、Spark SQL的特点
- 无缝集成在Spark中,将SQL查询与Spark程序混合。Spark SQL允许您使用SQL或熟悉的DataFrame API在Spark程序中查询结构化数据。适用于Java、Scala、Python和R语言。
- 提供统一的数据访问,以相同的方式连接到任何数据源。DataFrames和SQL提供了一种访问各种数据源的通用方法,包括Hive、Avro、Parquet、ORC、JSON和JDBC。您甚至可以通过这些源连接数据。
- 支持Hive集成。在现有仓库上运行SQL或HiveQL查询。Spark SQL支持HiveQL语法以及Hive SerDes和udf,允许您访问现有的Hive仓库。
- 支持标准的连接,通过JDBC或ODBC连接。服务器模式为业务智能工具提供了行业标准JDBC和ODBC连接。
三、核心概念:DataFrames和Datasets
DataFrame
DataFrame是组织成命名列的数据集。它在概念上等同于关系数据库中的表,但在底层具有更丰富的优化。DataFrames可以从各种来源构建,例如:
- 结构化数据文件
- hive中的表
- 外部数据库或现有RDDs
DataFrame API支持的语言有Scala,Java,Python和R。

从上图可以看出,DataFrame多了数据的结构信息,即schema。RDD是分布式的 Java对象的集合。DataFrame是分布式的Row对象的集合。DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化。
Datasets
Dataset是数据的分布式集合。Dataset是在Spark 1.6中添加的一个新接口,是DataFrame之上更高一级的抽象。它提供了RDD的优点(强类型化,使用强大的lambda函数的能力)以及Spark SQL优化后的执行引擎的优点。一个Dataset 可以从JVM对象构造,然后使用函数转换(map, flatMap,filter等)去操作。 Dataset API 支持Scala和Java。 Python不支持Dataset API。
四、创建DataFrames
- 测试数据如下:员工表

- 定义case class(相当于表的结构:Schema)
case class Emp(empno:Int,ename:String,job:String,mgr:Int,hiredate:String,sal:Int,comm:Int,deptno:Int)
- 将HDFS上的数据读入RDD,并将RDD与case Class关联
val lines = sc.textFile("hdfs://bigdata111:9000/input/emp.csv").map(_.split(","))
- 把每个Array映射成一个Emp的对象
val emp = lines.map(x => Emp(x(0).toInt,x(1),x(2),x(3).toInt,x(4),x(5).toInt,x(6).toInt,x(7).toInt))
- 生成DataFrame
val allEmpDF = emp.toDF
- 通过DataFrames查询数据
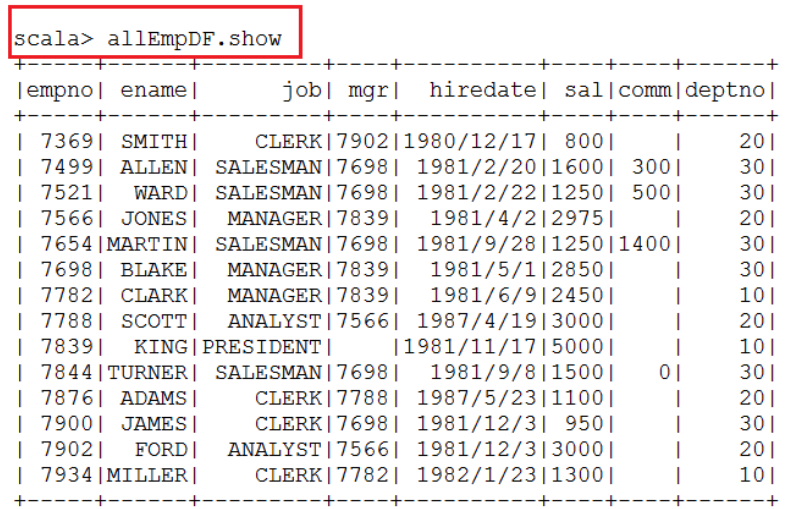
- 将DataFrame注册成表(视图)
allEmpDF.createOrReplaceTempView("emp")
- 执行SQL查询
spark.sql("select * from emp").show
【赵渝强老师】什么是Spark SQL?的更多相关文章
- 平易近人、兼容并蓄——Spark SQL 1.3.0概览
自2013年3月面世以来,Spark SQL已经成为除Spark Core以外最大的Spark组件.除了接过Shark的接力棒,继续为Spark用户提供高性能的SQL on Hadoop解决方案之外, ...
- 【转载】Spark SQL 1.3.0 DataFrame介绍、使用
http://www.aboutyun.com/forum.php?mod=viewthread&tid=12358&page=1 1.DataFrame是什么?2.如何创建DataF ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- 大数据技术之_19_Spark学习_03_Spark SQL 应用解析 + Spark SQL 概述、解析 、数据源、实战 + 执行 Spark SQL 查询 + JDBC/ODBC 服务器
第1章 Spark SQL 概述1.1 什么是 Spark SQL1.2 RDD vs DataFrames vs DataSet1.2.1 RDD1.2.2 DataFrame1.2.3 DataS ...
- Spark SQL中的Catalyst 的工作机制
Spark SQL中的Catalyst 的工作机制 答:不管是SQL.Hive SQL还是DataFrame.Dataset触发Action Job的时候,都会经过解析变成unresolved的逻 ...
- 1. Spark SQL概述
1.1 什么是Spark SQL Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用 它是将Hive SQL转换成 ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- Spark SQL源码解析(二)Antlr4解析Sql并生成树
Spark SQL原理解析前言: Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述 这一次要开始真正介绍Spark解析SQL的流程,首先是从Sql Parse阶段开始,简单点说, ...
- 第1章 Spark SQL概述
第1章 Spark SQL概述 1.1 什么是Spark SQL Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作 ...
- spark SQL (一)初识 ,简介
一, 简介 Spark SQL是用于结构化数据处理的Spark模块.与基本的Spark RDD API不同,Spark SQL提供的接口为Spark提供了关于数据结构和正在执行的计算的更多信息.在内部 ...
随机推荐
- 图灵课堂netty 仿微信开发
通信的图文示例 以下是需要实现的前端界面, 准备工作:开始实现前需要技术关健字解释 第一步,这儿直接建一个maven 项目 就好,只要是可能用maven 管理包的环境就行,课程使用的版本是 java ...
- Linux 备份命令 fsarchiver 基础使用教程
1 安装配置 fsarchiver 使用yum安装[二者选一个即可,我使用的是下面那个]: yum install https://dl.fedoraproject.org/pub/epel/epel ...
- 【Eclipse】下载安装(Windows)
Eclipse的下载和安装 官网地址:https://www.eclipse.org/downloads/ 刚用的时候选了安装版,然后安装到一半就失败了 建议点下面的解压包下载,解压即用 注意看框线的 ...
- 【Dos-BatchPrograming】03
--1.AT 计划任务 Microsoft Windows [版本 10.0.19041.746] (c) 2020 Microsoft Corporation. 保留所有权利. C:\Users\A ...
- 为什么要使用工业仿真软件? —— CAE(Computer Aided Engineering)工程设计中的计算机辅助工程
CAE技术: 引自: https://baike.baidu.com/item/CAE技术/18884456?fr=ge_ala 引自: https://www.mscsoftware.com.cn/ ...
- python代码实现将PDF文件转为文本及其对应的音频
代码地址: https://github.com/TiffinTech/python-pdf-audo ============================================ imp ...
- WhaleStudio 2.6重磅发布!调度模块WhaleScheduler更新78项核心功能
我们很高兴地宣布WhaleStudio 2.6版本的正式发布!新版本中包含了数据调度模块WhaleScheduler和数据集成模块WhaleTunnel的百余项核心功能更新,本文摘选了WhaleSch ...
- vue 文件流下载
/** * 文件转为文件流 * @param {file} file //文件 */ export function getFileBlob(file) { var dataUrl va ...
- 信创环境:鲲鹏ARM+麒麟V10离线部署K8s和Rainbond信创平台
在上篇<国产化信创开源云原生平台>文章中,我们介绍了 Rainbond 作为可能是国内首个开源国产化信创平台,在支持国产化和信创方面的能力,并简要介绍了如何在国产化信创环境中在线部署 Ku ...
- Linux下常用组件镜像源、smaba、gcc、ssh、mysql安装
Linux安装 博主使用的是ubuntu 16.04 apt更换镜像源 这里以更换阿里云镜像源为例. 首先去阿里云官方网站找对应版本系统的镜像源https://developer.aliyun.com ...