NanoDet:这是个小于4M超轻量目标检测模型
摘要:NanoDet 是一个速度超快和轻量级的移动端 Anchor-free 目标检测模型。
前言
YOLO、SSD、Fast R-CNN等模型在目标检测方面速度较快和精度较高,但是这些模型比较大,不太适合移植到移动端或嵌入式设备;轻量级模型 NanoDet-m,对单阶段检测模型三大模块(Head、Neck、Backbone)进行轻量化,目标加检测速度很快;模型文件大小仅几兆(小于4M)。
NanoDet作者开源代码地址:https://github.com/RangiLyu/nanodet (致敬)
基于NanoDet项目进行小裁剪,专门用来实现Python语言、PyTorch 版本的代码地址:https://github.com/guo-pu/NanoDet-PyTorch
下载直接能使用,支持图片、视频文件、摄像头实时目标检测
先看一下NanoDet目标检测的效果:
同时检测多辆汽车:

查看多目标、目标之间重叠、同时存在小目标和大目标的检测效果:

NanoDet 模型介绍
NanoDet 是一种 FCOS 式的单阶段 anchor-free 目标检测模型,它使用 ATSS 进行目标采样,使用 Generalized Focal Loss 损失函数执行分类和边框回归(box regression)。
1)NanoDet 模型性能
NanoDet-m模型和YoloV3-Tiny、YoloV4-Tiny作对比:

备注:以上性能基于 ncnn 和麒麟 980 (4xA76+4xA55) ARM CPU 获得的。使用 COCO mAP (0.5:0.95) 作为评估指标,兼顾检测和定位的精度,在 COCO val 5000 张图片上测试,并且没有使用 Testing-Time-Augmentation。
NanoDet作者将 ncnn 部署到手机(基于 ARM 架构的 CPU 麒麟 980,4 个 A76 核心和 4 个 A55 核心)上之后跑了一下 benchmark,模型前向计算时间只要 10 毫秒左右,而 yolov3 和 v4 tiny 均在 30 毫秒的量级。在安卓摄像头 demo app 上,算上图片预处理、检测框后处理以及绘制检测框的时间,NanoDet 也能轻松跑到 40+FPS。
2)NanoDet 模型架构
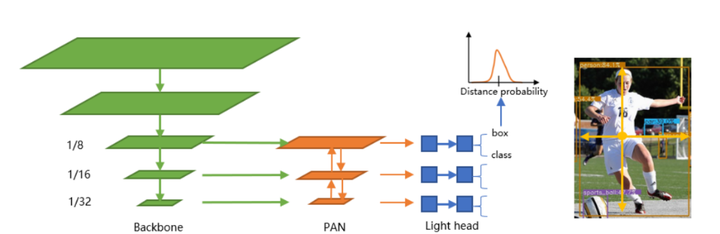
3)NanoDet损失函数
NanoDet 使用了李翔等人提出的 Generalized Focal Loss 损失函数。该函数能够去掉 FCOS 的 Centerness 分支,省去这一分支上的大量卷积,从而减少检测头的计算开销,非常适合移动端的轻量化部署。
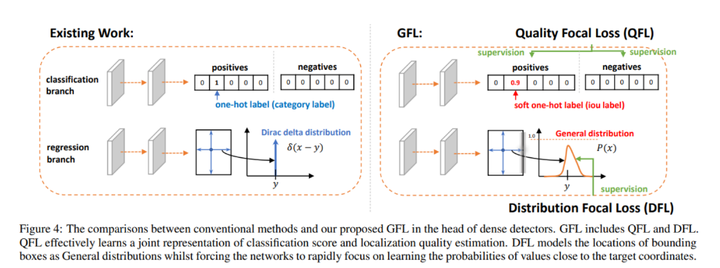
详细请参考:Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection
4)NanoDet 优势
NanoDet 是一个速度超快和轻量级的移动端 Anchor-free 目标检测模型。该模型具备以下优势:
- 超轻量级:模型文件大小仅几兆(小于4M——nanodet_m.pth);
- 速度超快:在移动 ARM CPU 上的速度达到 97fps(10.23ms);
- 训练友好:GPU 内存成本比其他模型低得多。GTX1060 6G 上的 Batch-size 为 80 即可运行;
- 方便部署:提供了基于 ncnn 推理框架的 C++ 实现和 Android demo。
基于PyTorch 实现NanoDet
基于NanoDet项目进行小裁剪,专门用来实现Python语言、PyTorch 版本的代码地址:
1)NanoDet目标检测效果
同时检测出四位少年

在复杂街道中,检测出行人、汽车:

通过测试发现NanoDet确实很快,但识别精度和效果比YOLOv4差不少的。
2)环境参数
测试环境参数
系统:Windows 编程语言:Python 3.8 整合开发环境:Anaconda
深度学习框架:PyTorch1.7.0+cu101 (torch>=1.3 即可) 开发代码IDE:PyCharm
开发具体环境要求如下:
- Cython
- termcolor
- numpy
- torch>=1.3
- torchvision
- tensorboard
- pycocotools
- matplotlib
- pyaml
- opencv-python
- tqdm
通常测试感觉GPU加速(显卡驱动、cudatoolkit 、cudnn)、PyTorch、pycocotools相对难装一点
Windows开发环境安装可以参考:
安装cudatoolkit 10.1、cudnn7.6请参考 https://blog.csdn.net/qq_41204464/article/details/108807165
安装PyTorch请参考 https://blog.csdn.net/u014723479/article/details/103001861
安装pycocotools请参考 https://blog.csdn.net/weixin_41166529/article/details/109997105
3)体验NanoDet目标检测
下载代码,打开工程
先到githug下载代码,然后解压工程,然后使用PyCharm工具打开工程;
githug代码下载地址:https://github.com/guo-pu/NanoDet-PyTorch
说明:该代码是基于NanoDet项目进行小裁剪,专门用来实现Python语言、PyTorch 版本的代码
NanoDet作者开源代码地址:https://github.com/RangiLyu/nanodet (致敬)
使用PyCharm工具打开工程
选择开发环境】
文件(file)——>设置(setting)——>项目(Project)——>Project Interpreters 选择搭建的开发环境;
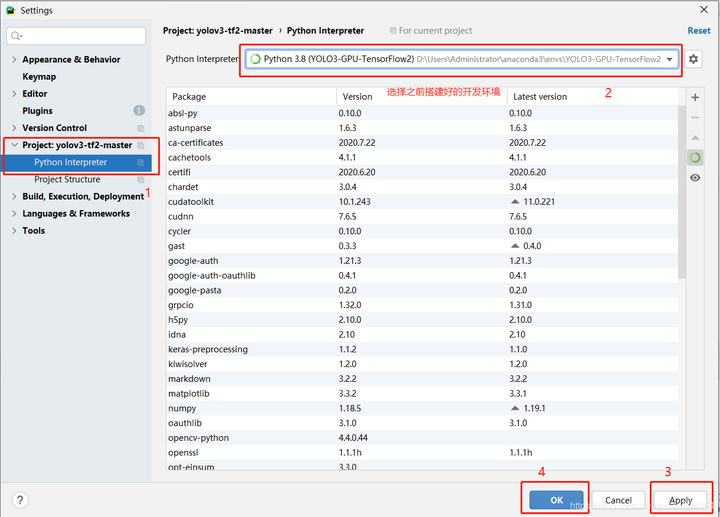
然后先点击Apply,等待加载完成,再点击OK;
进行目标检测
具体命令请参考:
'''目标检测-图片'''
python detect_main.py image --config ./config/nanodet-m.yml --model model/nanodet_m.pth --path street.png '''目标检测-视频文件'''
python detect_main.py video --config ./config/nanodet-m.yml --model model/nanodet_m.pth --path test.mp4 '''目标检测-摄像头'''
python detect_main.py webcam --config ./config/nanodet-m.yml --model model/nanodet_m.pth --path 0
【目标检测-图片】

【目标检测-视频文件】
检测的是1080*1920的图片,很流畅毫不卡顿,就是目前识别精度不太高

4)调用模型的核心代码
detect_main.py 代码:
import cv2
import os
import time
import torch
import argparse
from nanodet.util import cfg, load_config, Logger
from nanodet.model.arch import build_model
from nanodet.util import load_model_weight
from nanodet.data.transform import Pipeline image_ext = ['.jpg', '.jpeg', '.webp', '.bmp', '.png']
video_ext = ['mp4', 'mov', 'avi', 'mkv'] '''目标检测-图片'''
# python detect_main.py image --config ./config/nanodet-m.yml --model model/nanodet_m.pth --path street.png '''目标检测-视频文件'''
# python detect_main.py video --config ./config/nanodet-m.yml --model model/nanodet_m.pth --path test.mp4 '''目标检测-摄像头'''
# python detect_main.py webcam --config ./config/nanodet-m.yml --model model/nanodet_m.pth --path 0 def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument('demo', default='image', help='demo type, eg. image, video and webcam')
parser.add_argument('--config', help='model config file path')
parser.add_argument('--model', help='model file path')
parser.add_argument('--path', default='./demo', help='path to images or video')
parser.add_argument('--camid', type=int, default=0, help='webcam demo camera id')
args = parser.parse_args()
return args class Predictor(object):
def __init__(self, cfg, model_path, logger, device='cuda:0'):
self.cfg = cfg
self.device = device
model = build_model(cfg.model)
ckpt = torch.load(model_path, map_location=lambda storage, loc: storage)
load_model_weight(model, ckpt, logger)
self.model = model.to(device).eval()
self.pipeline = Pipeline(cfg.data.val.pipeline, cfg.data.val.keep_ratio) def inference(self, img):
img_info = {}
if isinstance(img, str):
img_info['file_name'] = os.path.basename(img)
img = cv2.imread(img)
else:
img_info['file_name'] = None height, width = img.shape[:2]
img_info['height'] = height
img_info['width'] = width
meta = dict(img_info=img_info,
raw_img=img,
img=img)
meta = self.pipeline(meta, self.cfg.data.val.input_size)
meta['img'] = torch.from_numpy(meta['img'].transpose(2, 0, 1)).unsqueeze(0).to(self.device)
with torch.no_grad():
results = self.model.inference(meta)
return meta, results def visualize(self, dets, meta, class_names, score_thres, wait=0):
time1 = time.time()
self.model.head.show_result(meta['raw_img'], dets, class_names, score_thres=score_thres, show=True)
print('viz time: {:.3f}s'.format(time.time()-time1)) def get_image_list(path):
image_names = []
for maindir, subdir, file_name_list in os.walk(path):
for filename in file_name_list:
apath = os.path.join(maindir, filename)
ext = os.path.splitext(apath)[1]
if ext in image_ext:
image_names.append(apath)
return image_names def main():
args = parse_args()
torch.backends.cudnn.enabled = True
torch.backends.cudnn.benchmark = True load_config(cfg, args.config)
logger = Logger(-1, use_tensorboard=False)
predictor = Predictor(cfg, args.model, logger, device='cuda:0')
logger.log('Press "Esc", "q" or "Q" to exit.')
if args.demo == 'image':
if os.path.isdir(args.path):
files = get_image_list(args.path)
else:
files = [args.path]
files.sort()
for image_name in files:
meta, res = predictor.inference(image_name)
predictor.visualize(res, meta, cfg.class_names, 0.35)
ch = cv2.waitKey(0)
if ch == 27 or ch == ord('q') or ch == ord('Q'):
break
elif args.demo == 'video' or args.demo == 'webcam':
cap = cv2.VideoCapture(args.path if args.demo == 'video' else args.camid)
while True:
ret_val, frame = cap.read()
meta, res = predictor.inference(frame)
predictor.visualize(res, meta, cfg.class_names, 0.35)
ch = cv2.waitKey(1)
if ch == 27 or ch == ord('q') or ch == ord('Q'):
break if __name__ == '__main__':
main()
本文分享自华为云社区《目标检测模型NanoDet(超轻量,速度很快)介绍和PyTorch版本实践》,原文作者:一颗小树x。
NanoDet:这是个小于4M超轻量目标检测模型的更多相关文章
- 平均精度均值(mAP)——目标检测模型性能统计量
在机器学习领域,对于大多数常见问题,通常会有多个模型可供选择.当然,每个模型会有自己的特性,并会受到不同因素的影响而表现不同. 每个模型的好坏是通过评价它在某个数据集上的性能来判断的,这个数据集通常被 ...
- 目标检测模型的性能评估--MAP(Mean Average Precision)
目标检测模型中性能评估的几个重要参数有精确度,精确度和召回率.本文中我们将讨论一个常用的度量指标:均值平均精度,即MAP. 在二元分类中,精确度和召回率是一个简单直观的统计量,但是在目标检测中有所不同 ...
- 谷歌大脑提出:基于NAS的目标检测模型NAS-FPN,超越Mask R-CNN
谷歌大脑提出:基于NAS的目标检测模型NAS-FPN,超越Mask R-CNN 朱晓霞发表于目标检测和深度学习订阅 235 广告关闭 11.11 智慧上云 云服务器企业新用户优先购,享双11同等价格 ...
- PyTorch专栏(八):微调基于torchvision 0.3的目标检测模型
专栏目录: 第一章:PyTorch之简介与下载 PyTorch简介 PyTorch环境搭建 第二章:PyTorch之60分钟入门 PyTorch入门 PyTorch自动微分 PyTorch神经网络 P ...
- 微调torchvision 0.3的目标检测模型
微调torchvision 0.3的目标检测模型 本文将微调在 Penn-Fudan 数据库中对行人检测和分割的已预先训练的 Mask R-CNN 模型.它包含170个图像和345个行人实例,说明如何 ...
- 目标检测模型的评价标准-AP与mAP
目录 目录 目录 前言 一,精确率.召回率与F1 1.1,准确率 1.2,精确率.召回率 1.3,F1 分数 1.4,PR 曲线 1.4.1,如何理解 P-R 曲线 1.5,ROC 曲线与 AUC 面 ...
- 旷世提出类别正则化的域自适应目标检测模型,缓解场景多样的痛点 | CVPR 2020
论文基于DA Faster R-CNN系列提出类别正则化框架,充分利用多标签分类的弱定位能力以及图片级预测和实例级预测的类一致性,从实验结果来看,类该方法能够很好地提升DA Faster R-CNN系 ...
- Yolov5——训练目标检测模型
项目的克隆 打开yolov5官网(GitHub - ultralytics/yolov5 at v5.0),下载yolov5的项目: 环境的安装(免额外安装CUDA和cudnn) 打开anaconda ...
- (转)如何用TensorLayer做目标检测的数据增强
数据增强在机器学习中的作用不言而喻.和图片分类的数据增强不同,训练目标检测模型的数据增强在对图像做处理时,还需要对图片中每个目标的坐标做相应的处理.此外,位移.裁剪等操作还有可能使得一些目标在处理后只 ...
- 目标检测 — two-stage检测
目前主流的目标检测算法主要是基于深度学习模型,其可以分成两大类:two-stage检测算法:one-stage检测算法.本文主要介绍第一类检测算法,第二类在下一篇博文中介绍. 目标检测模型的主要性能指 ...
随机推荐
- 差异行压缩算法(C#实现)
private byte[] DifferenceRowOrder(int offset, int count, byte[] inbyte)//差异行命令(此处的offset和count都从1开始) ...
- 记录一下我的ctf比赛的web题目
Web之getshell: 具体代码如下 <?php highlight_file(__FILE__); error_reporting(0); echo "<h1>WEL ...
- JZYZ作业好题
文章目录 敲砖块 Circle 敲砖块 首先把砖块向左对齐, 这样选择第 ( i , j ) (i,j) (i,j)块的前提是第 ( i − 1 , j ) , ( i − 1 , j + 1 ) ( ...
- pbootcms 后台内容列表搜索功能扩展及增加显示字段功能
应项目要求,一个内容模型下栏目不宜分的层级过多,如新闻模块,分2022.2023.2024年度,每年度下分12个月,这样就是2层栏目,再依类别(科技.动漫.电影...)划分层级,栏目数量较多,而且不易 ...
- Java之引用传递
引用传递分析 类本身就属于引用数据类型,既然是引用数据类型,就会牵扯到内存的引用传递. 引用传递的本质:同一块堆内存空间可以被不同的栈内存所指向,也可以变更指向. 引用传递案例 先看一个应用传递的例子 ...
- FPGA与Simulink联合仿真环境搭建(硬件在环)
硬件在环(HIL) \(\quad\)官方的一些定义:硬件在环 (HIL) 测试是一种实时仿真,让您无需使用系统硬件即可开始测试嵌入式代码.如果正在开发的代码未按照规范运行,您可以通过此项测试来发现可 ...
- python 数据可视化:直方图、核密度估计图、箱线图、累积分布函数图
本文使用数据来源自2023年数学建模国赛C题,以附件1.附件2数据为基础,通过excel的数据透视表等功能重新汇总了一份新的数据表,从中截取了一部分数据为例用于绘制图表.绘制的图表包括一维直方图.一维 ...
- C语言求100以内的全部素数,每行输出10个。素数就是只能被1和自身整除的正整数,1不是素数,2是素数。要求定义和调用函数prime(m)判断m是否为素数,当m为素数时返回1,否则返回0。
/* 开发者:慢蜗牛 开发时间:2020.5.28 程序功能:求100以内的素数 */ #include<stdio.h> int prime(int m); int prime(int ...
- Modbus转Profinet 网关
产品简介 实现 PROFINET 网络与串口网络之间的数据通信,三个串口可分别连接具有 RS232 或 RS485 接口的设 备到 PROFINET 网络.即将串口设备转换为 PROFINET 设备. ...
- 使用咱们公司的DataInside可视化产品配置了一个教育行业的大屏展示软件
今天在公司用配置了一个可视化大屏软件,大家觉得如何?