Karmada:让跨集群弹性伸缩FederatedHPA突破新边界
本文分享自华为云社区《Kubernetes多集群管理Karmada,跨集群弹性伸缩FederatedHPA突破新边界!》,作者:华为云云原生团队。
根据 Flexera 最新发布的《2023年云现状调查报告》,750家受访企业中,高达36%的企业表示云成本支出超过预期,另有9%的企业云成本严重超出预期,企业急需有效手段来降低云成本支出:
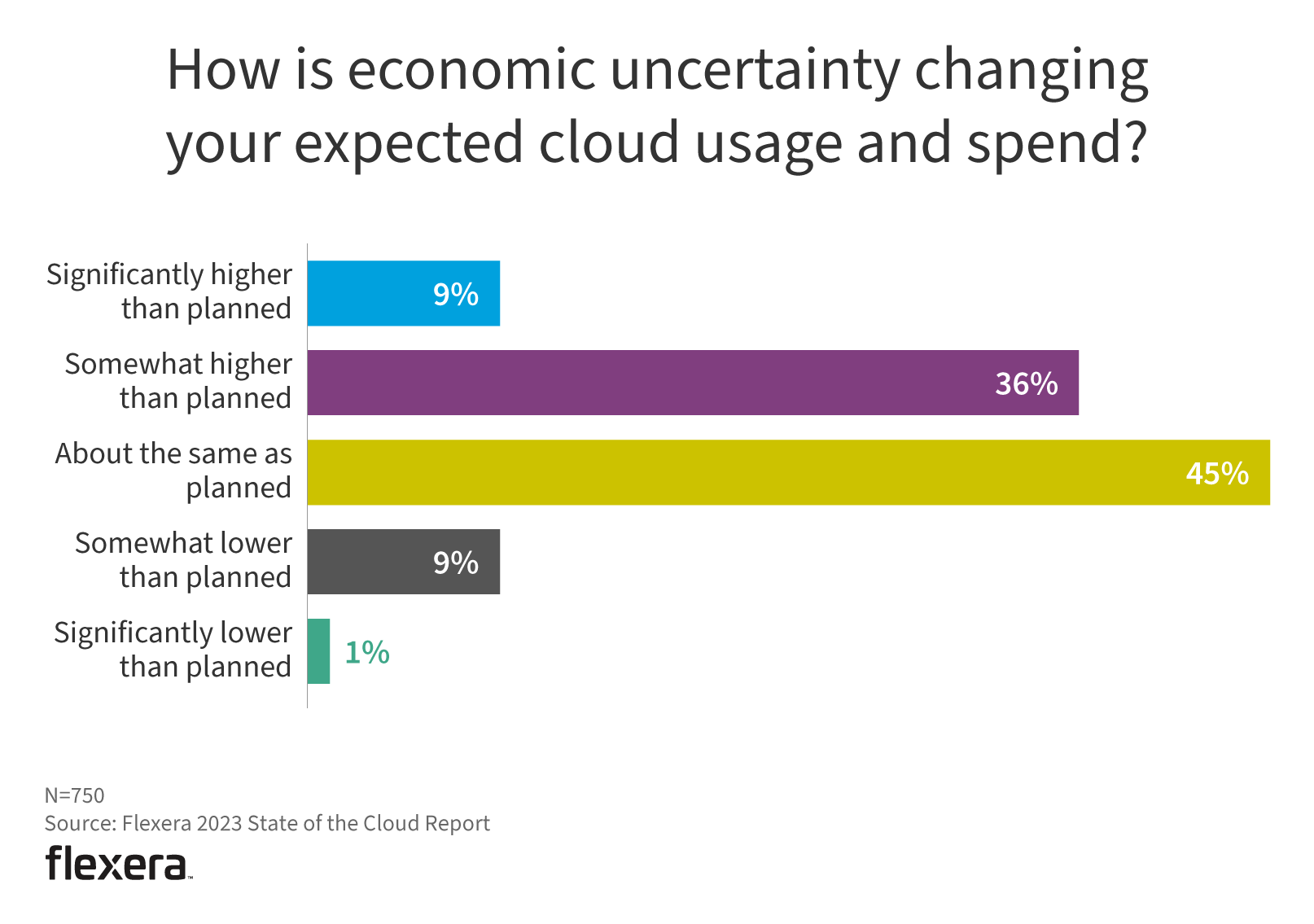
▲ 图片1
同时,在这些企业中,有高达87%的企业使用多云,多云架构的优势在于可以方便的提供业务高可用部署、满足安全合规的属地化部署、以及公有云弹性等能力,但如果缺少相应的成本管理,也容易导致云成本增加。
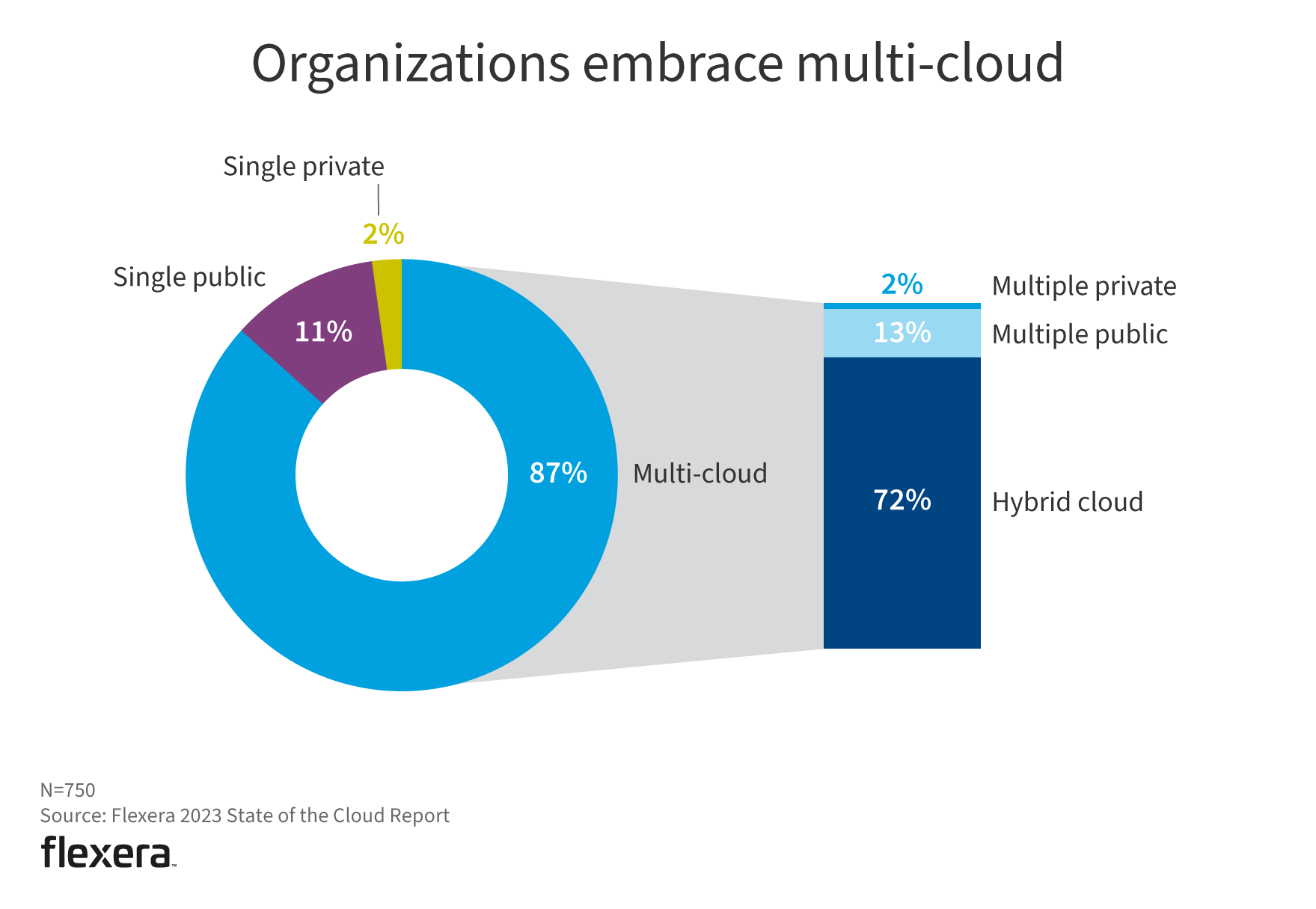
▲ 图片2
为了解决多云多集群下的成本难题,Karmada 率先提出并实现了支持多指标,多策略的全新跨集群HPA(即 FederatedHPA),实现业务跨集群弹性伸缩,为多云架构提供了新的玩法,比如本地数据中心+公有云的组合,业务优先使用本地数据中心资源,当本地资源不足时又可以借助公有云无限弹性能力,做到按需使用云资源,进而节省云成本开支。
FederatedHPA
Karmada FederatedHPA 可基于 CPU/Memory 利用率来自动伸缩业务,也可以基于各种自定义指标伸缩业务,其 YAML 配置示例为:
apiVersion: autoscaling.karmada.io/v1alpha1 kind: FederatedHPA metadata: name: nginx spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: nginx minReplicas: 1 maxReplicas: 10 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 10
通过使用 FederatedHPA,可以实现应用跨集群弹性能力,如下图所示,应用部署在 cluster1 集群中,当流量洪峰到来时,应用可以先在 cluster1 集群中自动扩容,当 cluster1 资源受限时,应用可以自动在 cluster2 集群中扩容。
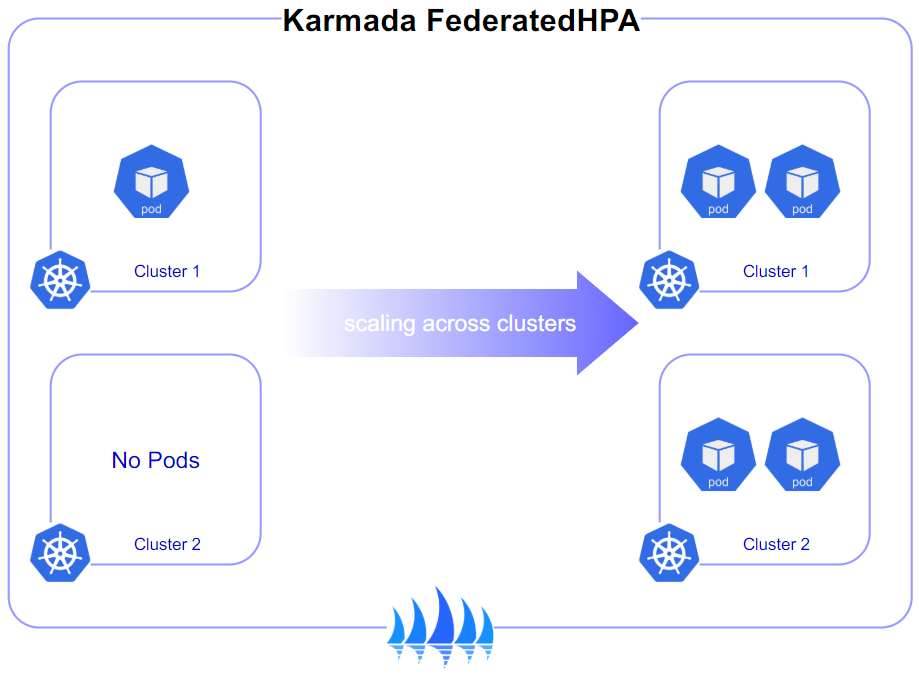
▲ 图片3
当然,Karmada FederatedHPA 带来的不仅仅是跨集群弹性伸缩,还能带来如下核心优势:
1.对于一个多集群业务,在每个集群中都有对应HPA资源,以伸缩业务。但分别管理这些HPA配置较为低效,而使用 Karmada FederatedHPA 能够统一配置多集群业务的伸缩,简化流程。
2.对于一个使用 Karmada FederatedHPA 的多集群业务,实例数会随着负载变化而变化。而这些新增或者减少的实例数,用户想要在不同集群,差异化的伸缩,如按可用资源比例,静态权重比例,优先顺序等。Karmada FederatedHPA 同样可满足这样的多集群差异化伸缩的诉求。
3.对于一个使用 Karmada FederatedHPA 的多集群业务,在某个集群因故障而无法弹性时,Karmada 会在其他正常集群弹性,从而解决单点故障问题。
统一弹性伸缩配置,提升管理效率
传统的部署方式下,用户如果想在多个集群中配置弹性伸缩,以匹配业务请求负载,需要逐一管理集群中的 HPA,繁琐而且容易出错,如下图:
▲ 图片4
使用 Karmade FederatedHPA,能够实现统一配置多集群业务的弹性伸缩,在集群数量较多的情况下,能极大提高效率,如下图:
▲ 图片5
通过单一 FederatedHPA 对象,Karmada 会自动监测多个集群的业务负载,根据配置的策略,在不同的集群伸缩,最终匹配多集群服务的业务负载。
优先扩容低成本集群业务,降低云成本支出
对于同一业务部署的多个集群,可能存在成本差异,用户可以利用 FederatedHPA 实现优先扩容成本更低集群的业务,实现更低的云成本消耗,例如:本地数据中心集群使用成本更低,公有云厂商提供的托管集群成本更高,因此,用户更愿意在本地数据中心中扩容业务。
下面我们给出一个优先扩容本地集群业务的例子:
apiVersion: autoscaling.karmada.io/v1alpha1 kind: FederatedHPA metadata: name: nginx spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: nginx minReplicas: 1 maxReplicas: 10 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 80 --- apiVersion: policy.karmada.io/v1alpha1 kind: PropagationPolicy metadata: name: nginx spec: resourceSelectors: - apiVersion: apps/v1 kind: Deployment name: nginx placement: clusterAffinities: - affinityName: local-cluster clusterNames: - local-cluster1 - affinityName: cloud-cluster clusterNames: - local-cluster1 - huawei-cluster1 replicaScheduling: replicaDivisionPreference: Weighted replicaSchedulingType: Divided weightPreference: dynamicWeight: AvailableReplicas
上面 PropagationPolicy 中配置有 本地集群组(local-cluster)和云上集群组(cloud-cluster)共两个集群组,Karmada 在扩容业务时,会优先尝试扩容在本地集群组中的业务,如果失败(缺乏资源),则继续扩容云上集群组的业务,从而实现在本地集群资源足够时,优先扩容本地集群的业务,实现更低的云成本消耗。
总结
FederatedHPA 为用户提供了跨集群弹性伸缩的能力,结合丰富的PropagationPolicy/ClusterPropagationPolicy 调度策略,能满足不同的跨集群伸缩场景。
Karmada 后续也会继续探索更多的跨集群伸缩场景,包括 定时联邦 HPA,分布式多集群 HPA,大家有任何感兴趣的想法,都欢迎大家来 Karmada 社区进行讨论和分享。
附:Karmada社区交流地址
Karmada官网:https://karmada.io/
项目地址:https://github.com/karmada-io/karmada
Slack地址:https://slack.cncf.io/
Karmada:让跨集群弹性伸缩FederatedHPA突破新边界的更多相关文章
- Karmada跨集群优雅故障迁移特性解析
摘要:在 Karmada 最新版本 v1.3中,跨集群故障迁移特性支持优雅故障迁移,确保迁移过程足够平滑. 本文分享自华为云社区<Karmada跨集群优雅故障迁移特性解析>,作者:Karm ...
- Karmada多云多集群生产实践专场圆满落幕
摘要:CNCF Karmada社区Cloud Native Days China 2022南京站成功举办. 本文分享自华为云社区<Karmada多云多集群生产实践专场圆满落幕|Cloud Nat ...
- 使用Karmada实现Helm应用的跨集群部署
摘要:借助Karmada原生API的支持能力,Karmada可以借助Flux轻松实现Helm应用的跨集群部署. 本文分享自华为云社区< 使用Karmada实现Helm应用的跨集群部署[云原生开源 ...
- 实现Kubernetes跨集群服务应用的高可用
在Kubernetes 1.3版本,我们希望降低跨集群跨地区服务部署相关的管理和运营难度.本文介绍如何实现此目标. 注意:虽然本文示例使用谷歌容器引擎(GKE)来提供Kubernetes集群,您可以在 ...
- SqlServer跨集群升级
SqlServer跨集群升级 1.新Server的IP要和旧的在同一网段. 2.安装SQL SERVER(注意:排序要和以前的一样,更改TempDB位置) 3.开启防火墙,并打开1433和5022端口 ...
- Elasticsearch跨集群搜索(Cross Cluster Search)
1.简介 Elasticsearch在5.3版本中引入了Cross Cluster Search(CCS 跨集群搜索)功能,用来替换掉要被废弃的Tribe Node.类似Tribe Node,Cros ...
- Hadoop 跨集群访问
[原文地址] 跨集群访问 发表于 2015-06-01 | 简单总结下跨集群访问的多种方式. 跨集群访问HDFS 直接给出HDFS URI 我们平常执行hadoop fs -ls /之类的操作 ...
- ES cross cluster search跨集群查询
ES 5.3以后出的新功能.测试demo如下: 下载ES 5.5版本,然后分别本机创建2个实例,配置如下: cluster.name: xx1 network.host: 127.0.0.1 http ...
- Hadoop跨集群迁移数据(整理版)
1. 什么是DistCp DistCp(分布式拷贝)是用于大规模集群内部和集群之间拷贝的工具.它使用Map/Reduce实现文件分发,错误处理和恢复,以及报告生成.它把文件和目录的列表作为map任务的 ...
- Hive跨集群迁移
Hive跨集群迁移数据工作是会出现的事情, 其中涉及到数据迁移, metastore迁移, hive版本升级等. 1. 迁移hdfs数据至新集群hadoop distcp -skipcrccheck ...
随机推荐
- 基于Python语言的KNN算法
import operator import numpy as np # 鸢尾花的数据集 load_iris from sklearn.datasets import load_iris ''' 对测 ...
- 2020/4/29 一场令人头疼的cf。。。
今天是被安排的cf...我真的是太菜了啊...又双叒叕被机房的一群dalao吊打了... 这就是我与6年级的dalao的区别吗...我裂开了 T1:A - Exercising Walk 简单题. 就 ...
- 谱图论:Laplacian算子及其谱性质
1 Laplacian 算子 给定无向图\(G=(V, E)\),我们在上一篇博客<谱图论:Laplacian二次型和Markov转移算子>中介绍了其对应的Laplacian二次型: \[ ...
- 栈溢出-GOT表劫持测试
1.目标程序源代码 char name[64]; int main(){ int unsigned long long addr; setvbuf(stdin,0,2,0); setvbuf(stdo ...
- 【羚珑AI智绘营】分分钟带你拿捏SD中的色彩控制
导言 颜色控制一直是AIGC的难点,prompt会污染.img2img太随机- 今天带来利用controlnet,实现对画面颜色的有效控制.都说AIGC是抽卡,但对把它作为工具而非玩具的设计师,必须掌 ...
- 【译】NoClassDefFoundError和ClassNotFoundException的不同(转)
https://www.jianshu.com/p/93d0db07d2e3 本文翻译自:Difference between NoClassDefFoundError vs ClassNotFoun ...
- NLP技术如何为搜索引擎赋能
在全球化时代,搜索引擎不仅需要为用户提供准确的信息,还需理解多种语言和方言.本文详细探讨了搜索引擎如何通过NLP技术处理多语言和方言,确保为不同地区和文化的用户提供高质量的搜索结果,同时提供了基于Py ...
- goto关键词
1.前言 goto,一个蒟蒻一用就废,大佬一用就吊炸天的神奇关键字. 今天,我要来盘它!!! 2.goto只能在函数内实现跳转,不能跨函数跳转 因为标号label是局部有效的. #include &l ...
- Educational Codeforces Round 105 (Rated for Div. 2) A-C题解
写在前边 链接:Educational Codeforces Round 105 (Rated for Div. 2) A. ABC String 链接:A题链接 题目大意: 给定一个有\(A.B.C ...
- TPshop商城的安装流程(windows)----超详细版
提前准备 phpStudy下载:https://www.xp.cn/download.html 选择适合自己的版本下载 TPshop商城源文件下载链接:https://pan.baidu.com/s/ ...