MySQL 的 crash-safe 原理解析
本文首发于 vivo互联网技术 微信公众号
链接:https://mp.weixin.qq.com/s/5i9wmJs4_Er7RaYfNnETyA
作者:xieweipeng
MySQL作为当下最流行的开源关系型数据库,有一个很关键和基本的能力,就是必须能够保证数据不会丢。那么在这个能力背后,MySQL是如何设计才能保证不管在什么时间崩溃,恢复后都能保证数据不会丢呢?有哪些关键技术支撑了这个能力?本文将为我们一一揭晓。
一、前言
MySQL 保证数据不会丢的能力主要体现在两方面:
- 能够恢复到任何时间点的状态;
- 能够保证MySQL在任何时间段突然奔溃,重启后之前提交的记录都不会丢失;
对于第一点将MySQL恢复到任何时间点的状态,相信很多人都知道,只要保留有足够的binlog,就能通过重跑binlog来实现。
对于第二点的能力,也就是本文标题所讲的crash-safe。即在 InnoDB 存储引擎中,事务提交过程中任何阶段,MySQL突然奔溃,重启后都能保证事务的完整性,已提交的数据不会丢失,未提交完整的数据会自动进行回滚。这个能力依赖的就是redo log和unod log两个日志。
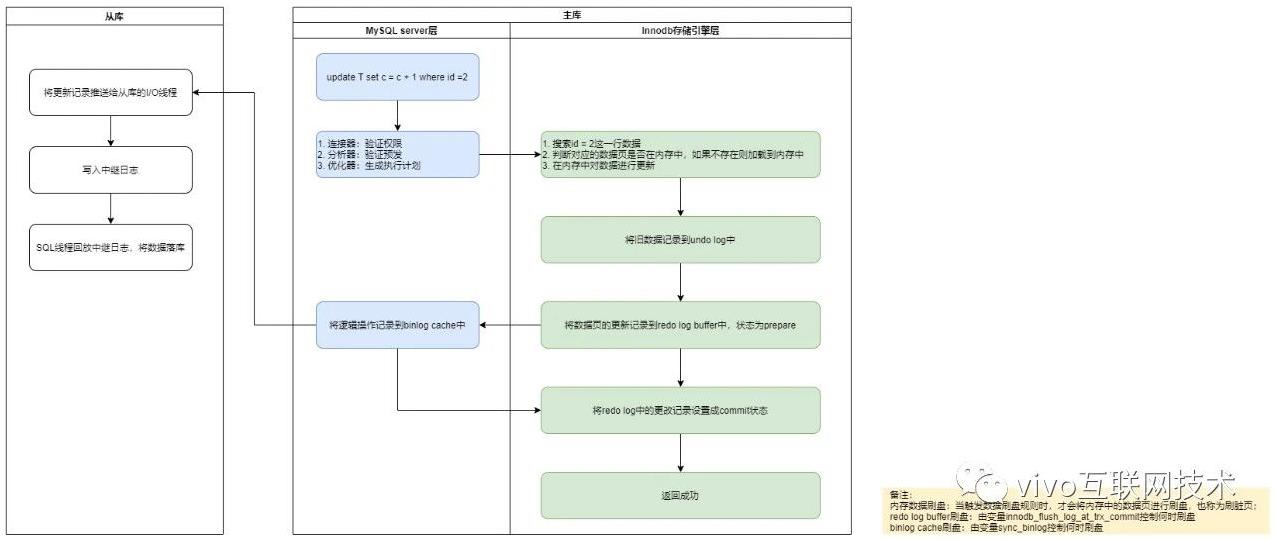
因为crash-safe主要体现在事务执行过程中突然奔溃,重启后能保证事务完整性,所以在讲解具体原理之前,先了解下MySQL事务执行有哪些关键阶段,后面才能依据这几个阶段来进行解析。下面以一条更新语句的执行流程为例,话不多说,直接上图:
从上图可以清晰地看出一条更新语句在MySQL中是怎么执行的,简单进行总结一下:
从内存中找出这条数据记录,对其进行更新;
将对数据页的更改记录到redo log中;
将逻辑操作记录到binlog中;
对于内存中的数据和日志,都是由后台线程,当触发到落盘规则后再异步进行刷盘;
上面演示了一条更新语句的详细执行过程,接下来咱们通过解答问题,带着问题来剖析这个crash-safe的设计原理。
二、WAL机制
问题:为什么不直接更改磁盘中的数据,而要在内存中更改,然后还需要写日志,最后再落盘这么复杂?
这个问题相信很多同学都能猜出来,MySQL更改数据的时候,之所以不直接写磁盘文件中的数据,最主要就是性能问题。因为直接写磁盘文件是随机写,开销大性能低,没办法满足MySQL的性能要求。所以才会设计成先在内存中对数据进行更改,再异步落盘。但是内存总是不可靠,万一断电重启,还没来得及落盘的内存数据就会丢失,所以还需要加上写日志这个步骤,万一断电重启,还能通过日志中的记录进行恢复。
写日志虽然也是写磁盘,但是它是顺序写,相比随机写开销更小,能提升语句执行的性能(针对顺序写为什么比随机写更快,可以比喻为你有一个本子,按照顺序一页一页写肯定比写一个字都要找到对应页写快得多)。
这个技术就是大多数存储系统基本都会用的WAL(Write Ahead Log)技术,也称为日志先行的技术,指的是对数据文件进行修改前,必须将修改先记录日志。保证了数据一致性和持久性,并且提升语句执行性能。
三、核心日志模块
问题:更新SQL语句执行流程中,总共需要写3个日志,这3个是不是都需要,能不能进行简化?
更新SQL执行过程中,总共涉及MySQL日志模块其中的三个核心日志,分别是redo log(重做日志)、undo log(回滚日志)、binlog(归档日志)。这里提前预告,crash-safe的能力主要依赖的就是这三大日志。
接下来,针对每个日志将单独介绍各自的作用,然后再来评估是否能简化掉。
1、重做日志 redo log
redo log也称为事务日志,由InnoDB存储引擎层产生。记录的是数据库中每个页的修改,而不是某一行或某几行修改成怎样,可以用来恢复提交后的物理数据页(恢复数据页,且只能恢复到最后一次提交的位置,因为修改会覆盖之前的)。
前面提到的WAL技术,redo log就是WAL的典型应用,MySQL在有事务提交对数据进行更改时,只会在内存中修改对应的数据页和记录redo log日志,完成后即表示事务提交成功,至于磁盘数据文件的更新则由后台线程异步处理。由于redo log的加入,保证了MySQL数据一致性和持久性(即使数据刷盘之前MySQL奔溃了,重启后仍然能通过redo log里的更改记录进行重放,重新刷盘),此外还能提升语句的执行性能(写redo log是顺序写,相比于更新数据文件的随机写,日志的写入开销更小,能显著提升语句的执行性能,提高并发量),由此可见redo log是必不可少的。
redo log是固定大小的,所以只能循环写,从头开始写,写到末尾就又回到开头,相当于一个环形。当日志写满了,就需要对旧的记录进行擦除,但在擦除之前,需要确保这些要被擦除记录对应在内存中的数据页都已经刷到磁盘中了。在redo log满了到擦除旧记录腾出新空间这段期间,是不能再接收新的更新请求,所以有可能会导致MySQL卡顿。(所以针对并发量大的系统,适当设置redo log的文件大小非常重要!!!)
2、回滚日志 undo log
undo log顾名思义,主要就是提供了回滚的作用,但其还有另一个主要作用,就是多个行版本控制(MVCC),保证事务的原子性。在数据修改的流程中,会记录一条与当前操作相反的逻辑日志到undo log中(可以认为当delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然,当update一条记录时,它记录一条对应相反的update记录),如果因为某些原因导致事务异常失败了,可以借助该undo log进行回滚,保证事务的完整性,所以undo log也必不可少。
3、归档日志 binlog
binlog在MySQL的server层产生,不属于任何引擎,主要记录用户对数据库操作的SQL语句(除了查询语句)。之所以将binlog称为归档日志,是因为binlog不会像redo log一样擦掉之前的记录循环写,而是一直记录(超过有效期才会被清理),如果超过单日志的最大值(默认1G,可以通过变量 max_binlog_size 设置),则会新起一个文件继续记录。但由于日志可能是基于事务来记录的(如InnoDB表类型),而事务是绝对不可能也不应该跨文件记录的,如果正好binlog日志文件达到了最大值但事务还没有提交则不会切换新的文件记录,而是继续增大日志,所以 max_binlog_size 指定的值和实际的binlog日志大小不一定相等。
正是由于binlog有归档的作用,所以binlog主要用作主从同步和数据库基于时间点的还原。
那么回到刚才的问题,binlog可以简化掉吗?这里需要分场景来看:
如果是主从模式下,binlog是必须的,因为从库的数据同步依赖的就是binlog;
如果是单机模式,并且不考虑数据库基于时间点的还原,binlog就不是必须,因为有redo log就可以保证crash-safe能力了;但如果万一需要回滚到某个时间点的状态,这时候就无能为力,所以建议binlog还是一直开启;
根据上面对三个日志的详解,我们可以对这个问题进行解答:在主从模式下,三个日志都是必须的;在单机模式下,binlog可以视情况而定,保险起见最好开启。
四、两阶段提交
问题:为什么redo log要分两步写,中间再穿插写binlog呢?
从上面可以看出,因为redo log影响主库的数据,binlog影响从库的数据,所以redo log和binlog必须保持一致才能保证主从数据一致,这是前提。
相信很多有过开发经验的同学都知道分布式事务,这里的redo log和binlog其实就是很典型的分布式事务场景,因为两者本身就是两个独立的个体,要想保持一致,就必须使用分布式事务的解决方案来处理。而将redo log分成了两步,其实就是使用了两阶段提交协议(Two-phase Commit,2PC)。
下面对更新语句的执行流程进行简化,看一下MySQL的两阶段提交是如何实现的:
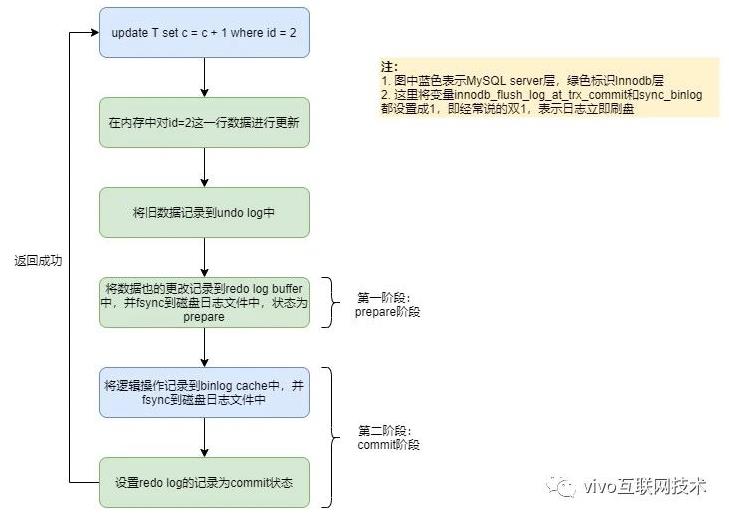
从图中可看出,事务的提交过程有两个阶段,就是将redo log的写入拆成了两个步骤:prepare和commit,中间再穿插写入binlog。
如果这时候你很疑惑,为什么一定要用两阶段提交呢,如果不用两阶段提交会出现什么情况,比如先写redo log,再写binlog或者先写binlog,再写redo log不行吗?下面我们用反证法来进行论证。
我们继续用update T set c=c+1 where id=2这个例子,假设id=2这一条数据的c初始值为0。那么在redo log写完,binlog还没有写完的时候,MySQL进程异常重启。由于redo log已经写完了,系统重启后会通过redo log将数据恢复回来,所以恢复后这一行c的值是1。但是由于binlog没写完就crash了,这时候binlog里面就没有记录这个语句。因此,不管是现在的从库还是之后通过这份binlog还原临时库都没有这一次更新,c的值还是0,与原库的值不同。
同理,如果先写binlog,再写redo log,中途系统crash了,也会导致主从不一致,这里就不再详述。
所以将redo log分成两步写,即两阶段提交,才能保证redo log和binlog内容一致,从而保证主从数据一致。
两阶段提交虽然能够保证单事务两个日志的内容一致,但在多事务的情况下,却不能保证两者的提交顺序一致,比如下面这个例子,假设现在有3个事务同时提交:
T1 (--prepare--binlog---------------------commit)
T2 (-----prepare-----binlog----commit)
T3 (--------prepare-------binlog------commit) 解析:
redo log prepare的顺序:T1 --》T2 --》T3
binlog的写入顺序:T1 --》 T2 --》T3
redo log commit的顺序:T2 --》 T3 --》T1 结论:由于binlog写入的顺序和redo log提交结束的顺序不一致,导致binlog和redo log所记录的事务提交结束的顺序不一样,最终导致的结果就是主从数据不一致。
因此,在两阶段提交的流程基础上,还需要加一个锁来保证提交的原子性,从而保证多事务的情况下,两个日志的提交顺序一致。所以在早期的MySQL版本中,通过使用prepare_commit_mutex锁来保证事务提交的顺序,在一个事务获取到锁时才能进入prepare,一直到commit结束才能释放锁,下个事务才可以继续进行prepare操作。通过加锁虽然完美地解决了顺序一致性的问题,但在并发量较大的时候,就会导致对锁的争用,性能不佳。除了锁的争用会影响到性能之外,还有一个对性能影响更大的点,就是每个事务提交都会进行两次fsync(写磁盘),一次是redo log落盘,另一次是binlog落盘。大家都知道,写磁盘是昂贵的操作,对于普通磁盘,每秒的QPS大概也就是几百。
五、组提交
问题:针对通过在两阶段提交中加锁控制事务提交顺序这种实现方式遇到的性能瓶颈问题,有没有更好的解决方案呢?
答案自然是有的,在MySQL 5.6 就引入了binlog组提交,即BLGC(Binary Log Group Commit)。binlog组提交的基本思想是,引入队列机制保证InnoDB commit顺序与binlog落盘顺序一致,并将事务分组,组内的binlog刷盘动作交给一个事务进行,实现组提交目的。具体如图:
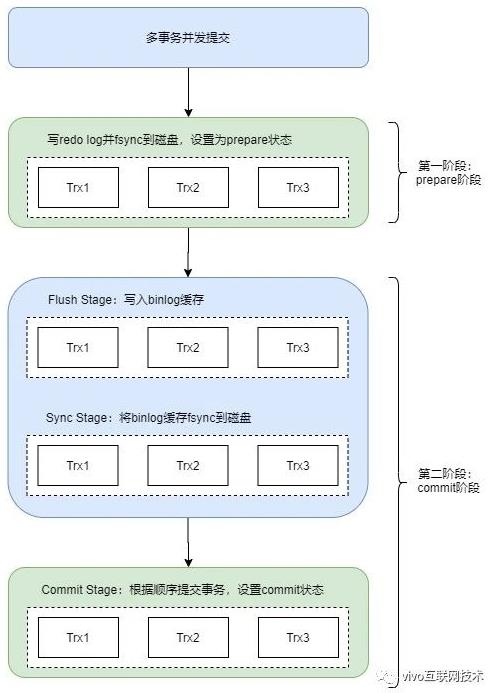
第一阶段(prepare阶段):
持有prepare_commit_mutex,并且write/fsync redo log到磁盘,设置为prepared状态,完成后就释放prepare_commit_mutex,binlog不作任何操作。
第二个阶段(commit阶段):这里拆分成了三步,每一步的任务分配给一个专门的线程处理:
Flush Stage(写入binlog缓存)
① 持有Lock_log mutex [leader持有,follower等待]
② 获取队列中的一组binlog(队列中的所有事务)
③ 写入binlog缓存
Sync Stage(将binlog落盘)
①释放Lock_log mutex,持有Lock_sync mutex[leader持有,follower等待]
②将一组binlog落盘(fsync动作,最耗时,假设sync_binlog为1)。
Commit Stage(InnoDB commit,清楚undo信息)
①释放Lock_sync mutex,持有Lock_commit mutex[leader持有,follower等待]
② 遍历队列中的事务,逐一进行InnoDB commit
③ 释放Lock_commit mutex
每个Stage都有自己的队列,队列中的第一个事务称为leader,其他事务称为follower,leader控制着follower的行为。每个队列各自有mutex保护,队列之间是顺序的。只有flush完成后,才能进入到sync阶段的队列中;sync完成后,才能进入到commit阶段的队列中。但是这三个阶段的作业是可以同时并发执行的,即当一组事务在进行commit阶段时,其他新事务可以进行flush阶段,实现了真正意义上的组提交,大幅度降低磁盘的IOPS消耗。
针对组提交为什么比两阶段提交加锁性能更好,简单做个总结:组提交虽然在每个队列中仍然保留了prepare_commit_mutex锁,但是锁的粒度变小了,变成了原来两阶段提交的1/4,所以锁的争用性也会大大降低;另外,组提交是批量刷盘,相比之前的单条记录都要刷盘,能大幅度降低磁盘的IO消耗。
六、数据恢复流程
问题:假设事务提交过程中,MySQL进程突然奔溃,重启后是怎么保证数据不丢失的?
下图就是MySQL重启后,提供服务前会先做的事 -- 恢复数据的流程:
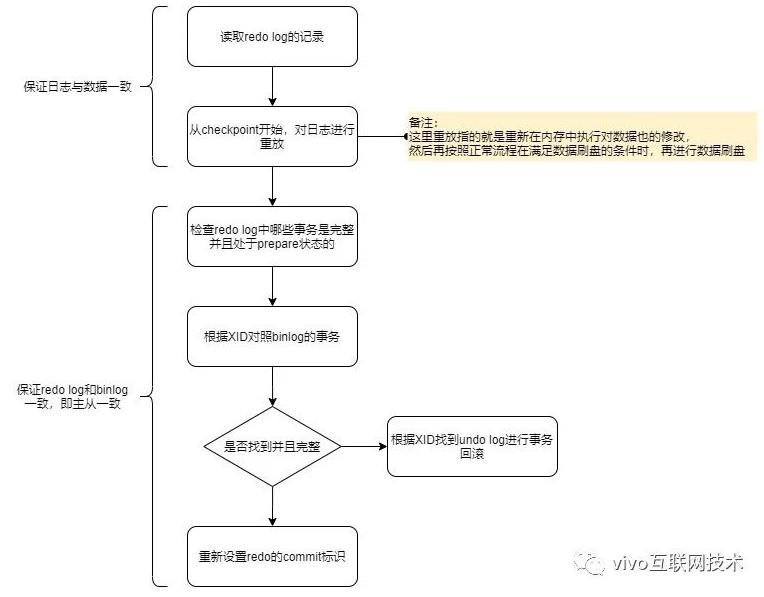
对上图进行简单描述就是:奔溃重启后会检查redo log中是完整并且处于prepare状态的事务,然后根据XID(事务ID),从binlog中找到对应的事务,如果找不到,则回滚;找到并且事务完整则重新commit redo log,完成事务的提交。
下面我们根据事务提交流程,在不同的阶段时刻,看看MySQL突然奔溃后,按照上述流程是如何恢复数据的。
时刻A(刚在内存中更改完数据页,还没有开始写redo log的时候奔溃):
因为内存中的脏页还没刷盘,也没有写redo log和binlog,即这个事务还没有开始提交,所以奔溃恢复跟该事务没有关系;
时刻B(正在写redo log或者已经写完redo log并且落盘后,处于prepare状态,还没有开始写binlog的时候奔溃):
恢复后会判断redo log的事务是不是完整的,如果不是则根据undo log回滚;如果是完整的并且是prepare状态,则进一步判断对应的事务binlog是不是完整的,如果不完整则一样根据undo log进行回滚;
时刻C(正在写binlog或者已经写完binlog并且落盘了,还没有开始commit redo log的时候奔溃):
恢复后会跟时刻B一样,先检查redo log中是完整并且处于prepare状态的事务,然后判断对应的事务binlog是不是完整的,如果不完整则一样根据undo log回滚,完整则重新commit redo log;
时刻D(正在commit redo log或者事务已经提交完的时候,还没有反馈成功给客户端的时候奔溃):
恢复后跟时刻C基本一样,都会对照redo log和binlog的事务完整性,来确认是回滚还是重新提交。
七、总结
至此对MySQL 的crash-safe原理细节就基本讲完了,简单回顾一下:
首先简单介绍了WAL日志先行技术,包括它的定义、流程和作用。WAL是大部分数据库系统实现一致性和持久性的通用设计模式。;
接着对MySQL的日志模块,redo log、undo log、binlog、两阶段提交和组提交都进行了详细介绍;
最后讲解了数据恢复流程,并从不同时刻加以验证。
更多内容敬请关注 vivo 互联网技术 微信公众号

注:转载文章请先与微信号:Labs2020 联系。
MySQL 的 crash-safe 原理解析的更多相关文章
- MySQL crash-safe replication(3): MySQL的Crash Safe和Binlog的关系
2016-12-23 17:29 宋利兵 作者:宋利兵 来源:MySQL代码研究(mysqlcode) 0.导读 本文重点介绍了InnoDB的crash safe和binlog之间的关系,以及2阶段提 ...
- MySQL索引机制(详细+原理+解析)
MySQL索引机制 永远年轻,永远热泪盈眶 一.索引的类型与常见的操作 前缀索引 MySQL 前缀索引能有效减小索引文件的大小,提高索引的速度.但是前缀索引也有它的坏处:MySQL 不能在 ORDER ...
- 【原创】14. MYSQL++之SSQLS(原理解析)
从之前所介绍的SSQLS的介绍中我们可以感受到,SSQLS的精髓应该在sql_create_#这个宏,他所创建出来的这个结构体将会是突破的关键,所以我将会从以下顺序入手. 1. sql_create_ ...
- MySQL查询优化器工作原理解析
手册上查询优化器概述 查询优化器的任务是发现执行SQL查询的最佳方案.大多数查询优化器,包括MySQL的查询优化器,总或多或少地在所有可能的查询评估方案中搜索最佳方案.对于联接查询,MySQL优化器所 ...
- InnoSQL HA Suite的实现原理与配置说明 InnoSQL的VSR功能Virtual Sync Replication MySQL 5.5版本引入了半同步复制(semi-sync replicaiton)的功能 MySQL 5.6支持了crash safe功能
InnoSQL HA Suite的实现原理与配置说明 InnoSQL的VSR功能Virtual Sync Replication MySQL 5.5版本引入了半同步复制(semi-sync repl ...
- 深入解析Mysql 主从同步延迟原理及解决方案
MySQL的主从同步是一个很成熟的架构,优点为:①在从服务器可以执行查询工作(即我们常说的读功能),降低主服务器压力;②在从主服务器进行备份,避免备份期间影响主服务器服务;③当主服务器出现问题时,可以 ...
- 【算法】(查找你附近的人) GeoHash核心原理解析及代码实现
本文地址 原文地址 分享提纲: 0. 引子 1. 感性认识GeoHash 2. GeoHash算法的步骤 3. GeoHash Base32编码长度与精度 4. GeoHash算法 5. 使用注意点( ...
- 十种MYSQL显错注入原理讲解(二)
上一篇讲过,三种MYSQL显错注入原理.下面我继续讲解. 1.geometrycollection() and geometrycollection((select * from(select * f ...
- 十种MYSQL显错注入原理讲解(一)
开篇我要说下,在<代码审计:企业级Web代码安全架构>这本书中讲十种MYSQL显错注入,讲的很清楚. 感兴趣请去读完,若处于某种原因没读还想了解,那请继续往下. 1.count,rand, ...
- GeoHash原理解析
GeoHash 核心原理解析 引子 一提到索引,大家脑子里马上浮现出B树索引,因为大量的数据库(如MySQL.oracle.PostgreSQL等)都在使用B树.B树索引本质上是对索引字段 ...
随机推荐
- 小闫s人格大爆发 | 坐椅子上?study:sleep
hadoop视频 搭建环境 刷单词 看电影
- 写入数据或者通过EXCEl批量导入到数据库时报类型转换异常问题
报错日志如下(此处我用的是达梦,实际MySQL和oracle也会有类似的问题): Cause: org.apache.ibatis.type.TypeException: Error setting ...
- [清华集训2017] Hello World!
Hello world! 题目背景 不远的一年前,小 V 还是一名清华集训的选手,坐在机房里为他已如风中残烛的OI 生涯做最后的挣扎.而如今,他已成为了一名光荣的出题人.他感到非常激动,不禁感叹道: ...
- hbase报错 ERROR: org.apache.hadoop.hbase.ipc.ServerNotRunningYetException: Server is not running yet
hbase报错:hbase shell能打开 网页也能打开 但是一执行命令就开始报错. 原因:hadoop的安全模式打开. 解决方法:关闭安全模式 ,再重新启动HBase就可以了. 具体的命令: 1. ...
- Oracle-lsnrctl监听进程控制
LSNRCTL> help The following operations are available An asterisk (*) denotes a modifier or extend ...
- Centos8 硬盘挂载
查看硬盘分区状况 fdisk -l 可以看到数据盘 /dev/vdb 大小为 10Gb,目前还没有进行分区. 对 /dev/vdb 资源盘进行分区 fdisk /dev/vdb //根据提示输入信息: ...
- cmd命令根据端口号杀进程
1.根据端口查到进程pid netstat –ano|findstr 端口号 1 2.使用taskkill命令杀死进程 taskkill /pid pid 1 温馨提醒: 1.执行完第一步后,命令行显 ...
- 网安区过年-Log4j2
Log4j2-2021 漏洞原理 Apache Log4j 2 是Java语言的日志处理套件,使用极为广泛.在其2.0到2.14.1版本中存在一处JNDI注入漏洞,攻击者在可以控制日志内容的情况下,通 ...
- Python——第五章:Zipfile模块
Zipfile模块 zipfile 模块是 Python 中用于处理 ZIP 文件的标准库模块.它提供了创建.读取和写入 ZIP 文件的功能. zipfile 模块在写入文件时,如果要将文件写入子目录 ...
- 使用Spring AI让你的Spring Boot应用快速拥有生成式AI能力
之前分享了关于Spring新项目Spring AI的介绍视频.视频里演示了关于使用Spring AI将Open AI的能力整合到Spring应用中的操作,但有不少读者提到是否有博客形式的学习内容.所以 ...