克服 ClickHouse 运维难题:ByteHouse 水平扩容功能上线
前言
- 流程全手动,无数据可靠性保证。
- 扩容期间性能开销大,通常需要暂停服务。
开源社区的实现方案
- 新增节点后,手动提升新节点的导入权重,或暂时停止旧节点的数据导入,直至数据均衡。这种配置要求 Distributed 表的分片键(Sharding-key)设置为 random,对于设定了指定的 sharding-key 的表,无法采用这种模式。此外,如果存量数据很大,通过该方式实现均衡非常缓慢,可能花费数天乃至数个月才能追平。
- 手动在节点之间移动分区,使节点间均衡。该方式需要大表均已设置比较合理的分区键(Partition Key),并且分片键也只能为 Random,并且需要手动计算分区的移动目标节点。
- 使用 ClickHouse Copier或 Insert Into Select 方式,将现存表全部重新插入实现均衡。该方式开销非常高,将占用大量的 CPU / 存储 IO / 网络 IO 资源。
ByteHouse 的优化方案
数据库引擎优化
Alter Table...Resharding命令,将一张表以分区的粒度进行重分布到另一张表。该命令支持两种方式:- 重分布到其他集群的另一张表
- 重分布到本集群的另一张表
alter table <db>.<table> resharding partition <partition_expr> with <sharding_expr> to shard [shard_list]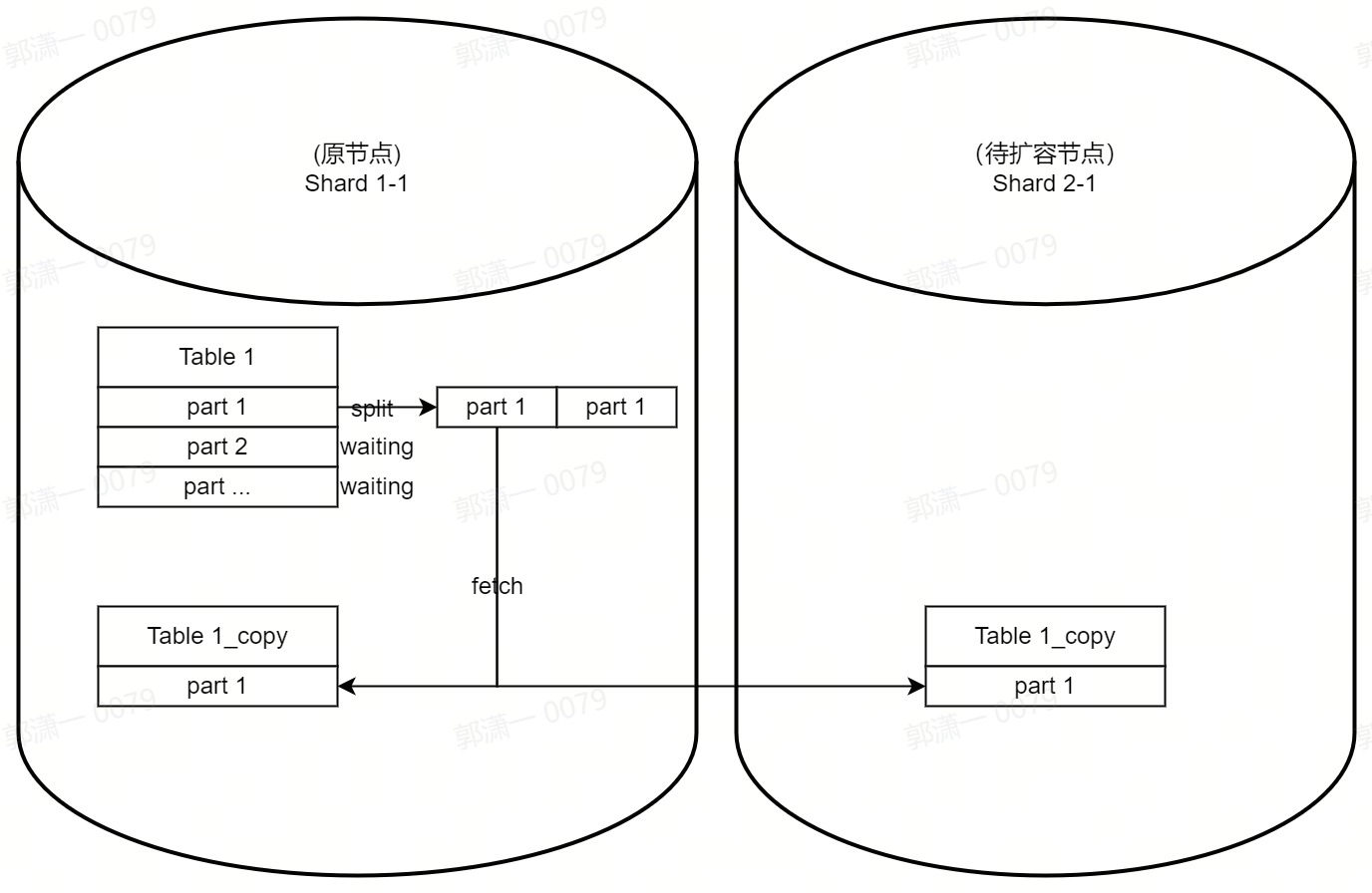
- 对于要扩容的表 table,新建目标表,如 table1_new;
- 提交
Alter Table table1 Resharding Partition <partition_expr> with <sharding_expr> to table [table1_new_list];提交的任务会被存储到 ZooKeeper 上,后台线程负责调度执行; - 所有提交的任务逐个开始执行。每个任务首先执行 Part 拆分,将一个 Part 根据 Sharding-key 拆分为 N 份(N 为扩容后的分片数);
- Part 拆分结束后,将 Part 信息发布到对应的分片上,对应不同分片上的目标表 table1_new 会进入 FETCHING 状态,开始拉取 Part;
- 等待这些 Part 被拉取完成,然后开始执行下一个任务,直至一张表的所有 Part 都被重分布完成
system.reshard_partition追踪进度,取得状态。- 扩容的适应性好,对于是否设置分片键、分区键,均无硬性要求,都可以进行扩容。
- 性能损耗小。整个重分布过程为一个旁路计算任务,开销远低于
insert into select全局数据重新插入的方式。 - 执行过程中,数据保持可查询,下游数据看板、数据分析等服务不用暂停。目前在扩容过程中,ByteHouse暂时不支持写入。但就原理而言,扩容进度90%前都可写入,只需要最后阶段一次性 Resharding 在扩容任务执行过程中新写入的 Part 即可。因此,ByteHouse未来功能也有继续提升的空间。
操作界面优化
- 在集群列表/详情页选择“更改配置”,选择“水平更配”。
- 用户选择集群更配后节点数,支持增加节点(水平扩容),也支持减少节点(水平缩容);
- 可在扩容前勾选“完成后自动重分布”,也可不勾选,在扩容后再手动重分布;如果勾选“自动重分布”,则需要选择需要在扩容后立即重分布的表。
- 界面会给出预估扩容时间。用户可以根据实际情况,对下游业务发出扩容公告。
- 提交扩容任务,集群进入“运维任务中”状态。后台执行两阶段任务:
- 阶段1,新增节点。实际在进行新节点的初始化,并在新节点上新建元数据;
- 阶段2,集群节点完成增加后,则开始重分布,可以查看每张表的重分布进度。
- 上述步骤完成,集群恢复“运行中”状态。
- 全流程自动化,不再需要自行编写脚本。
- 也开放一小部分手动空间。例如,在扩容前可选立即重分布的表,对于剩余的表,可在扩容后再选择时间重分布任务,适应一些希望在业务低峰时扩容大表,进一步降低大表只读带来的影响。
- 包含容错处理,自动校验数据,流程便利可靠。
总结
- 低 CPU / IO 开销,数据重分布期间可读;
- 全程自动化,界面化;
- 不依赖其他外置工具,在 ByteHouse 产品内闭环;
了解更多
克服 ClickHouse 运维难题:ByteHouse 水平扩容功能上线的更多相关文章
- “网红架构师”解决你的Ceph 运维难题
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由Tstack发表于云+社区专栏 本文为长篇连续剧,将分多个篇幅发表,主要介绍了从动手部署环境到后期运营故障处理过程中常见的问题,内容由 ...
- 数据库运维平台~inception回滚功能
一 简介:inception的另一个激动人心的功能,很强大.二 功能简介: inception会针对已经执行sql语句进行1 记录 2 生成回滚语句三 备份: 1 启用远程备份机制(强烈建议一台单 ...
- 开发便于运维的Windows服务
过去几个月,DevOps on Windows网站推出了一系列文章,详细讲解了开发者应怎样创建便于运维的Windows服务.这一系列文章详细分析了如何克服在运维部门看来最困难的部分:Windows服务 ...
- (转)ceph 常用 运维命令--查看信息 - 不错的文档
下面是测试验证环节 1. 创建一个 pool rbd create foo --size 4 --image-format 2 --image-feature layering 2. 挂载和格式化 r ...
- Redis运维利器 -- RedisManager
Redis作为一个基于内存的可持久化的日志型.Key-Value数据库,以其出色的性能表现以及高可用性在许多公司有着举足轻重的地位.伴随着业务量的增长,redis集群的规模不可避免的需要扩大,此时re ...
- 浅谈SDN架构下的运维工作
导读 目前国内的网络运维还处于初级阶段,工作人员每天就像救火一样,天天疲于奔命.运维人员只能埋头查找系统运行的日志,耗时耗力,老眼昏花不说,有时候忙了半天还一无所获,作为运维工程师的你,有木有遇到过类 ...
- 自动化运维与Saltstack
一.自动化运维介绍 1.自动化运维产生背景 传统的IT运维是将数据中心中的网络设备.服务器.数据库.中间件.存储.虚拟化.硬件等资源进行统一监控,当资源出现告警时,运维人员通过工具或者基于经验进行 ...
- Ansible自动化运维工具
ansible软件介绍 python语言是运维人员必会的语言! ansible是一个基于Python开发的自动化运维工具!(saltstack) 其功能实现基于SSH远程连接服务! ans ...
- iNeuOS工业互联网操作系统,设备运维业务和“低代码”表单开发工具
目 录 1. 概述... 2 2. 设备运维业务... 3 3. "低代码"表单开发工具... 6 1. 概述 iNeuOS工业互联网 ...
- saltstack自动化运维系列11基于etcd的saltstack的自动化扩容
saltstack自动化运维系列11基于etcd的saltstack的自动化扩容 自动化运维-基于etcd加saltstack的自动化扩容# tar -xf etcd-v2.2.1-linux-amd ...
随机推荐
- 在 windows 借助 git 修改文件权限
起因: 创建新仓库的时候,仓库都没有脚本,然后就需要把运维同事的脚本复制过来,可执行脚本都是在 scripts 文件夹下面的 过了几天,来活了 刚开始还不知道咋回事,想到的文件权限是在linux系统下 ...
- 对于goland相对较新一些版本新建项目时没有go mod模式选项的坑
前言 对于一些小白在网上看很早的一些go视频,使用goland2020.3.x版本或者其之前版本创建新项目,里面会有GO Modules(vgo)这个选项,也就是gomod模式创建新项目,然而对于现在 ...
- 25. 干货系列从零用Rust编写正反向代理,序列化之serde是如何工作的
wmproxy wmproxy已用Rust实现http/https代理, socks5代理, 反向代理, 静态文件服务器,四层TCP/UDP转发,内网穿透,后续将实现websocket代理等,会将实现 ...
- Python 利用pandas和matplotlib绘制堆叠柱状图
在数据可视化中,堆叠柱状图是一种常用的图表类型,它能够清晰地展示多个类别的数据,并突出显示每个类别中各部分的总量和组成比例.本文将演示如何使用 Python 的 pandas 和 matplotlib ...
- TPshop商城的安装流程(windows)----超详细版
提前准备 phpStudy下载:https://www.xp.cn/download.html 选择适合自己的版本下载 TPshop商城源文件下载链接:https://pan.baidu.com/s/ ...
- 金蝶云星空与吉客云电商ERP数据对接
01 系统说明: 吉客云 吉客云: 从业务数字化和组织数字化两个方向出发,以生成流程的闭环为依归,致力于为企业的数字化升级提供落地工具.销售订单层面,吉客云对接了国内外主流的销售平台,兼容了电商渠道. ...
- class-dump 混淆加固、保护与优化原理
class-dump 混淆加固.保护与优化原理 进行逆向时,经常需要dump可执行文件的头文件,用以确定类信息和方法信息,为hook相关方法提供更加详细的数据.class-dump的主要用于检查存 ...
- MySQL 有哪些常见的面试题
MySQL 是一种常用的关系型数据库管理系统,在面试过程中经常会涉及与 MySQL 相关的问题.以下是一些常见的 MySQL 面试题: 1. 介绍一下 MySQL 和其他数据库管理系统的区别. - M ...
- 手机成绩分析软件排行榜TOP10下载
随着智能手机的普及和移动应用的快速发展,手机成绩分析软件越来越受到学生.家长和教育机构的关注.这些软件可以帮助用户方便地记录.分析和管理学生成绩,提供个性化的学习指导和反馈.在本文中,将详细介绍202 ...
- SpringBoot项目中常见组件的配置属性
本文本的属性摘录自官方Properties配置清单,并附加了国内开发常用的框架配置属性.以国内WEB开发中,所涉及的常见组件为顺序组织配置清单 1. 配置属性清单 1.1 日志配置 序号 属性名 类型 ...