在MATPool矩池云完成Pytorch训练MNIST数据集
本文为矩池云入门手册的补充:Pytorch训练MNIST数据集代码运行过程。
案例代码和对应数据集,以及在矩池云上的详细操作可以在矩池云入门手册中查看,本文基于矩池云入门手册,默认用户已经完成了机器租用,上传解压好了数据、代码,并使用jupyter lab进行代码运行。
在MATPool矩池云完成Pytorch训练MNIST数据集
1. 安装自己需要的第三方包
以tqdm包为例子,如果在运行代码过程出现了ModuleNotFoundError: No module named 'tqdm',说明我们选择的系统镜像中没有预装这个包,我们只需要再JupyterLab的Terminal输入pip install tqdm即可安装相关包。

其他自己需要的第三方包安装方法也类似。
2. 在JupyterLab中运行代码
JupyterLab目录里面,我们依次点击mnt->MyMNIST进入到项目文件夹,在项目文件夹下双击pytorch_mnist.ipynb文件,即可打开代码文件。
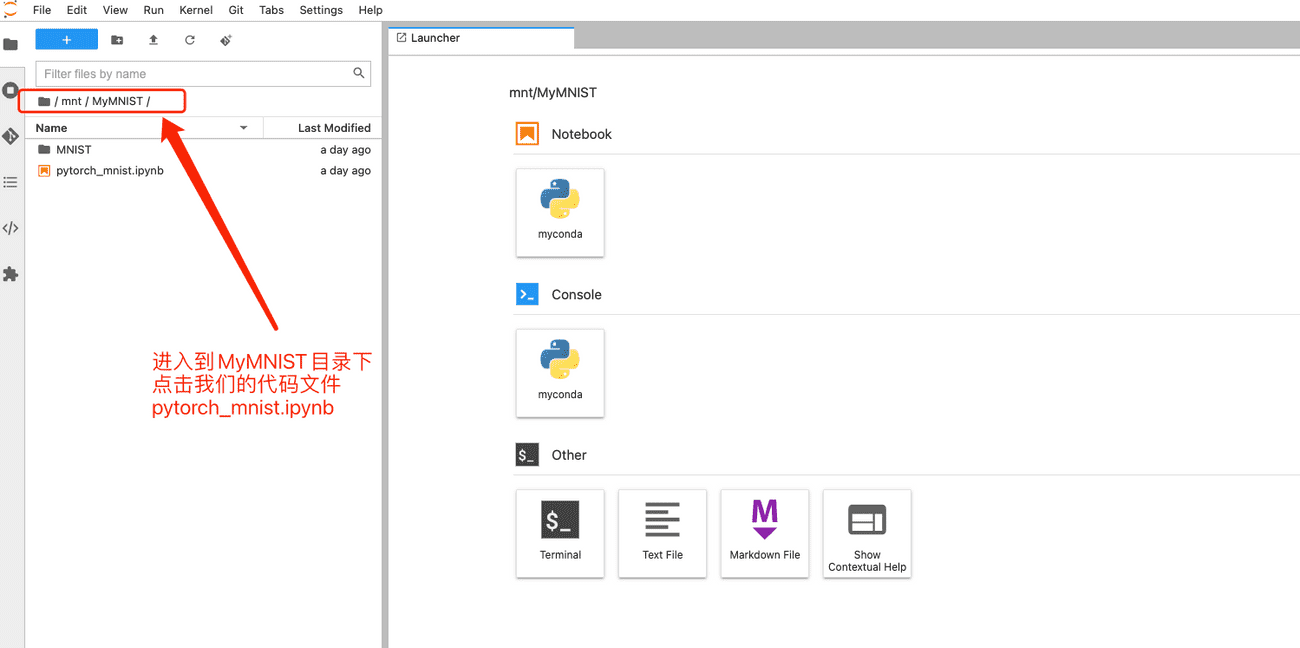
打开代码文件后,我们就可以直接运行了,截图中给大家说明了几个常用的JupyteLab 按钮功能。
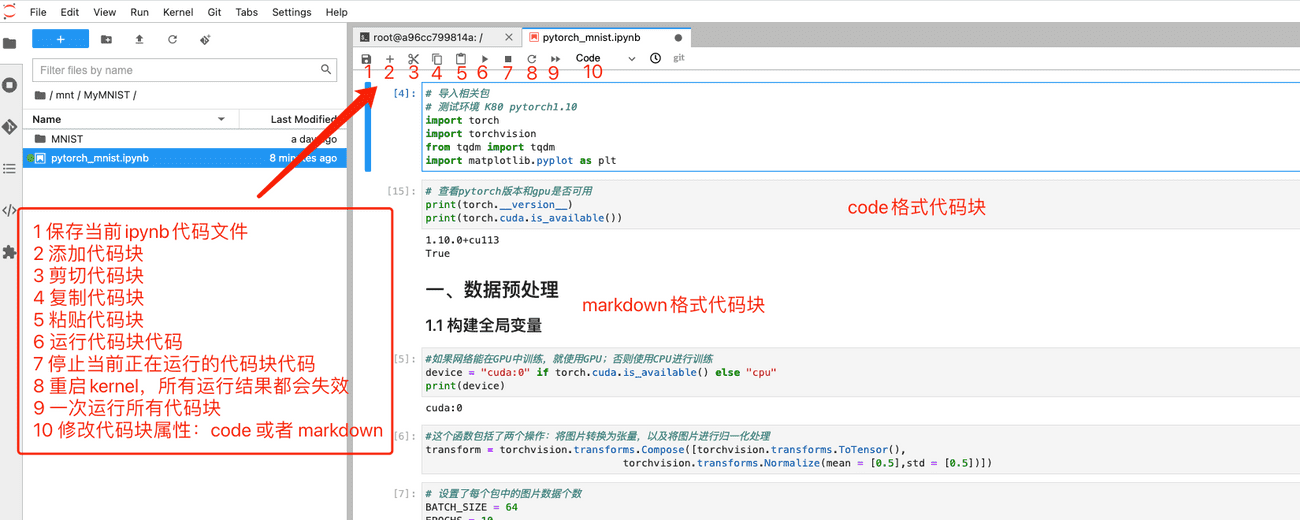
接下来我们开始运行代码~
2.1 导入需要的Python包
首先运行下面代码导入需要的模块,如:
- pytorch相关:torch、torchvision
- 训练输出进度条可视化显示:tqdm
- 训练结果图表可视化显示:matplotlib.pyplot
# 导入相关包
# 测试环境 K80 pytorch1.10
import torch
import torchvision
from tqdm import tqdm
import matplotlib.pyplot as plt
测试下机器中的pytorch版本和GPU是否可用。
# 查看pytorch版本和gpu是否可用
print(torch.__version__)
print(torch.cuda.is_available())
'''
输出:
1.10.0+cu113
True
'''
上面输出表示pytorch版本为1.10.0,机器GPU可用。
2.2 数据预处理
设置device、BATCH_SIZE和EPOCHS
# 如果网络能在GPU中训练,就使用GPU;否则使用CPU进行训练
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# 这个函数包括了两个操作:将图片转换为张量,以及将图片进行归一化处理
transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean = [0.5],std = [0.5])])
# 设置了每个包中的图片数据个数
BATCH_SIZE = 64
EPOCHS = 10
加载构建训练和测试数据集
# 从项目文件中加载训练数据和测试数据
train_dataset = torchvision.datasets.MNIST('/mnt/MyMNIST/',train = True,transform = transform)
test_dataset = torchvision.datasets.MNIST('/mnt/MyMNIST/',train = False,transform = transform)
# 建立一个数据迭代器
# 装载训练集
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=BATCH_SIZE,
shuffle=True)
# 装载测试集
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=BATCH_SIZE,
shuffle=True)
2.3 构建数据训练模型并创建实例
构建数据训练模型
# 一个简单的卷积神经网络
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.model = torch.nn.Sequential(
#The size of the picture is 28x28
torch.nn.Conv2d(in_channels = 1,out_channels = 16,kernel_size = 3,stride = 1,padding = 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size = 2,stride = 2),
#The size of the picture is 14x14
torch.nn.Conv2d(in_channels = 16,out_channels = 32,kernel_size = 3,stride = 1,padding = 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size = 2,stride = 2),
#The size of the picture is 7x7
torch.nn.Conv2d(in_channels = 32,out_channels = 64,kernel_size = 3,stride = 1,padding = 1),
torch.nn.ReLU(),
torch.nn.Flatten(),
torch.nn.Linear(in_features = 7 * 7 * 64,out_features = 128),
torch.nn.ReLU(),
torch.nn.Linear(in_features = 128,out_features = 10),
torch.nn.Softmax(dim=1)
)
def forward(self,input):
output = self.model(input)
return output
构建模型实例
# 构建模型实例
net = Net()
# 将模型转换到device中,并将其结构显示出来
print(net.to(device))

2.4 构建迭代器与损失函数
# 交叉熵损失来作为损失函数
# Adam迭代器
loss_fun = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters())
2.5 构建并运行训练循环
history = {'Test Loss':[],'Test Accuracy':[]}
for epoch in range(1,EPOCHS + 1):
process_bar = tqdm(train_loader,unit = 'step')
net.train(True)
for step,(train_imgs,labels) in enumerate(process_bar):
train_imgs = train_imgs.to(device)
labels = labels.to(device)
net.zero_grad()
outputs = net(train_imgs)
loss = loss_fun(outputs,labels)
predictions = torch.argmax(outputs, dim = 1)
accuracy = torch.true_divide(torch.sum(predictions == labels), labels.shape[0])
loss.backward()
optimizer.step()
process_bar.set_description("[%d/%d] Loss: %.4f, Acc: %.4f" %
(epoch,EPOCHS,loss.item(),accuracy.item()))
if step == len(process_bar)-1:
correct,total_loss = 0,0
net.train(False)
with torch.no_grad():
for test_imgs,labels in test_loader:
test_imgs = test_imgs.to(device)
labels = labels.to(device)
outputs = net(test_imgs)
loss = loss_fun(outputs,labels)
predictions = torch.argmax(outputs,dim = 1)
total_loss += loss
correct += torch.sum(predictions == labels)
test_accuracy = torch.true_divide(correct, (BATCH_SIZE * len(test_loader)))
test_loss = torch.true_divide(total_loss, len(test_loader))
history['Test Loss'].append(test_loss.item())
history['Test Accuracy'].append(test_accuracy.item())
process_bar.set_description("[%d/%d] Loss: %.4f, Acc: %.4f, Test Loss: %.4f, Test Acc: %.4f" %
(epoch,EPOCHS,loss.item(),accuracy.item(),test_loss.item(),test_accuracy.item()))
process_bar.close()

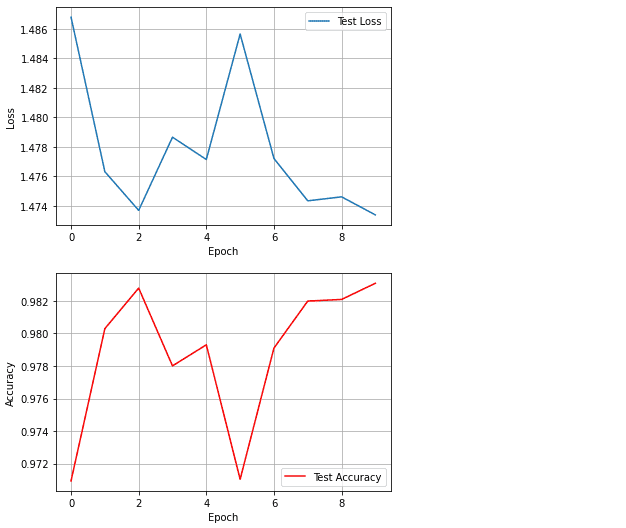
2.6 训练结果可视化
#对测试Loss进行可视化
plt.plot(history['Test Loss'],label = 'Test Loss')
plt.legend(loc='best')
plt.grid(True)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()
#对测试准确率进行可视化
plt.plot(history['Test Accuracy'],color = 'red',label = 'Test Accuracy')
plt.legend(loc='best')
plt.grid(True)
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.show()
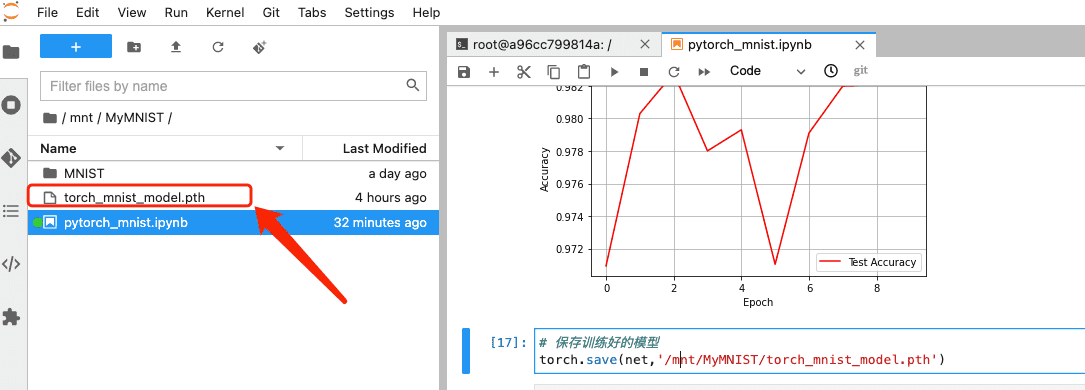
2.7 保存模型
# 保存训练好的模型
torch.save(net,'/mnt/MyMNIST/torch_mnist_model.pth')
保存成功后,JupyterLab 中对应文件夹会出现该文件,在矩池云网盘对应目录下也会存在。
参考文章
在MATPool矩池云完成Pytorch训练MNIST数据集的更多相关文章
- 矩池云上安装yolov4 darknet教程
这里我是用PyTorch 1.8.1来安装的 拉取仓库 官方仓库 git clone https://github.com/AlexeyAB/darknet 镜像仓库 git clone https: ...
- 矩池云 | 高性价比的GPU租用深度学习平台
矩池云是一个专业的国内深度学习云平台,拥有着良好的深度学习云端训练体验.在性价比上,我们以 2080Ti 单卡为例,36 小时折扣后的价格才 55 元,每小时单价仅 1.52 元,属于全网最低价.用户 ...
- 矩池云上TensorBoard/TensorBoardX配置说明
Tensorflow用户使用TensorBoard 矩池云现在为带有Tensorflow的镜像默认开启了6006端口,那么只需要在租用后使用命令启动即可 tensorboard --logdir lo ...
- 矩池云助力科研算力免费上"云",让 AI 教学简单起来
矩池云是一个专业的国内深度学习云平台,拥有着良好的深度学习云端训练体验,和高性价比的GPU集群资源.而且对同学们比较友好,会经常做一些大折扣的活动,最近双十一,全场所有的RTX 2070.Platin ...
- 在矩池云使用Disco Diffusion生成AI艺术图
在 Disco Diffusion 官方说明的第一段,其对自身是这样定义: AI Image generating technique called CLIP-Guided Diffusion.DD ...
- 在矩池云上复现 CVPR 2018 LearningToCompare_FSL 环境
这是 CVPR 2018 的一篇少样本学习论文:Learning to Compare: Relation Network for Few-Shot Learning 源码地址:https://git ...
- 用端口映射的办法使用矩池云隐藏的vnc功能
矩池云隐藏了很多高级功能待用户去挖掘. 租用机器 进入jupyterlab 设置vnc密码 VNC_PASSWD="userpasswd" ./root/vnc_startup.s ...
- 矩池云上安装ikatago及远程链接教程
https://github.com/kinfkong/ikatago-resources/tree/master/dockerfiles 从作者的库中可以看到,该程序支持cuda9.2.cuda10 ...
- 使用 MobaXterm 连接矩池云 GPU服务器
Host Name(主机名):hz.matpool.com 或 hz-t2.matpool.com,请以您 SSH 中给定的域名为准. Port(端口号):矩池云租用记录里 SSH 链接里冒号后的几位 ...
- 如何使用 PuTTY 远程连接矩池云主机
PuTTY 是一款开源的连接软件,用来远程连接服务器,支持 SSH.Telnet.Serial 等协议. 矩池云的主机支持 SSH 登录,以下为使用 PuTTY 连接矩池云 GPU 的使用教程. 如您 ...
随机推荐
- 推荐系统[三]:粗排算法常用模型汇总(集合选择和精准预估),技术发展历史(向量內积,Wide&Deep等模型)以及前沿技术
1.前言:召回排序流程策略算法简介 推荐可分为以下四个流程,分别是召回.粗排.精排以及重排: 召回是源头,在某种意义上决定着整个推荐的天花板: 粗排是初筛,一般不会上复杂模型: 精排是整个推荐环节的重 ...
- 8.2 C++ 引用与取别名
C/C++语言是一种通用的编程语言,具有高效.灵活和可移植等特点.C语言主要用于系统编程,如操作系统.编译器.数据库等:C语言是C语言的扩展,增加了面向对象编程的特性,适用于大型软件系统.图形用户界面 ...
- Centos8 配置IP地址与阿里YUM源
Centos8 系统中无法找到network.service网络服务,默认已经被nmcli替换了,所以修改方式略微变化,在/etc/sysconfig/network-scripts/里也看不到任何脚 ...
- Apache Typecho框架启用地址重写
地址重写有利于SEO优化,开启地址重写可以去掉Typecho框架中的index.php后缀,该后缀如下. 第一步,进到apache配置文件目录下cat /etc/httpd/conf/httpd.co ...
- Json Schema高性能.net实现库 LateApexEarlySpeed.Json.Schema - 直接从code生成json schema validator
LateApexEarlySpeed.Json.Schema - Json schema validator generation from code 除了用户手动传入标准的json schema来生 ...
- SpringBoot2.7集成Swagger3
1.引入pom坐标 <!--swagger--> <dependency> <groupId>io.springfox</groupId> <ar ...
- 基于Hyper-V搭建免费桌面云
Hyper-V 是 Microsoft 的硬件虚拟化产品. 它用于创建并运行计算机的软件版本,称为"虚拟机". 每个虚拟机都像一台完整的计算机一样运行操作系统和程序. 如果需要计算 ...
- ch583/ch582/ch573/ch571 central(主机)程序
本程序是在CH582m上运行的, 一.主从连接 主机这里可以根据从机的MAC地址进行连接.static uint8_t PeerAddrDef[B_ADDR_LEN] = {0x02, 0x02, 0 ...
- SOCKS5协议解析
socks的官方文档:https://www.ietf.org/rfc/rfc1928.txt 本文改变其他作者之手,在原文基础上加入客户端的编写,完善了服务端代码,原文是Linux端的程序代码,本文 ...
- delphi 异常测试(我自己捕捉)
由于最近的短信模块老是报SocketErorr错误,有的时候也不确定是哪里有问题,影响短信的销售,所以这里这样写,把出现的异常捕捉到显示出来.然后跳过这个不发送 ------------------- ...