无所不谈,百无禁忌,Win11本地部署无内容审查中文大语言模型CausalLM-14B

目前流行的开源大语言模型大抵都会有内容审查机制,这并非是新鲜事,因为之前chat-gpt就曾经被“玩”坏过,如果没有内容审查,恶意用户可能通过精心设计的输入(prompt)来操纵LLM执行不当行为。内容审查可以帮助识别和过滤这些潜在的攻击,确保LLM按照既定的安全策略和道德标准运行。
但我们今天讨论的是无内容审查机制的大模型,在中文领域公开的模型中,能力相对比较强的有阿里的 Qwen-14B 和清华的 ChatGLM3-6B。
而今天的主角,CausalLM-14B则是在Qwen-14B基础上使用了 Qwen-14B 的部分权重,并且加入一些其他的中文数据集,最终炼制了一个无内容审核的大模型版本,经过量化后可以在本地运行,保证了用户的隐私。
CausalLM-14B的量化版本下载页面:
https://huggingface.co/TheBloke/CausalLM-14B-GGUF
量化版本的运行条件:
Name Quant method Bits Size Max RAM required Use case
causallm_14b.Q4_0.gguf Q4_0 4 8.18 GB 10.68 GB legacy; small, very high quality loss - prefer using Q3_K_M
causallm_14b.Q4_1.gguf Q4_1 4 9.01 GB 11.51 GB legacy; small, substantial quality loss - lprefer using Q3_K_L
causallm_14b.Q5_0.gguf Q5_0 5 9.85 GB 12.35 GB legacy; medium, balanced quality - prefer using Q4_K_M
causallm_14b.Q5_1.gguf Q5_1 5 10.69 GB 13.19 GB legacy; medium, low quality loss - prefer using Q5_K_M
causallm_14b.Q8_0.gguf Q8_0 8 15.06 GB 17.56 GB very large, extremely low quality loss - not recommended
本地环境配置
笔者的设备是神船笔记本4060的8G显卡配置。
首先确保本地安装好了Visual Studio installer开发工具,在搜索框中直接搜索Visual Studio即可:
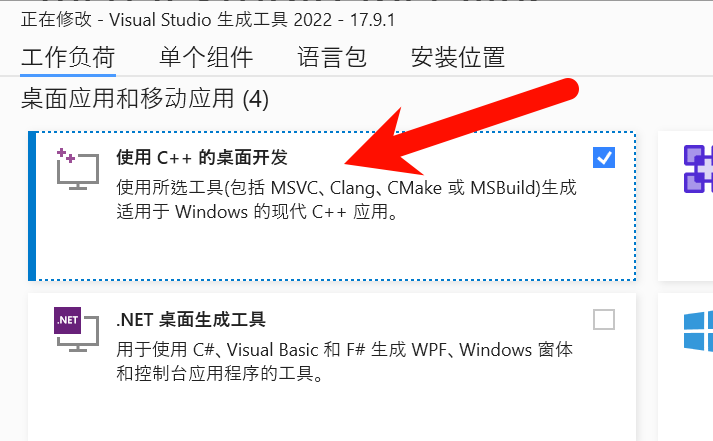
点选后,确保安装了使用C++的桌面开发组件:
随后下载并且配置cmake:
https://cmake.org/download/
本地运行命令:
PS C:\Users\zcxey> cmake -version
cmake version 3.29.0-rc1
CMake suite maintained and supported by Kitware (kitware.com/cmake).
PS C:\Users\zcxey>
代表配置成功。
接着需要下载CUDA:
https://developer.nvidia.com/cuda-downloads
这里推荐12的版本,运行命令:
PS C:\Users\zcxey> nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Wed_Nov_22_10:30:42_Pacific_Standard_Time_2023
Cuda compilation tools, release 12.3, V12.3.107
Build cuda_12.3.r12.3/compiler.33567101_0
PS C:\Users\zcxey>
说明cuda配置成功。
通过llama.cpp来跑大模型
llama.cpp 是一个开源项目,它提供了一个纯 C/C++ 实现的推理工具,用于运行大型语言模型(LLaMA)。这个项目由开发者 Georgi Gerganov 开发,基于 Meta(原 Facebook)发布的 LLaMA 模型。llama.cpp 的目标是使得大型语言模型能够在各种硬件上本地运行,包括那些没有高性能 GPU 的设备。
在llama.cpp的releases下载页:
https://github.com/ggerganov/llama.cpp/releases
下载llama-b2288-bin-win-cublas-cu12.2.0-x64.zip
也就是基于CUDA12的编译好的版本。
在终端中打开llama-b2288-bin-win-cublas-cu12.2.0-x64目录,运行命令:
D:\Downloads\llama-b2288-bin-win-cublas-cu12.2.0-x64>.\main.exe -m D:\Downloads\causallm_14b.Q4_0.gguf --n-gpu-layers 30 --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<|im_start|>system\n{You are a helpful assistant.}<|im_end|>\n<|im_start|>user\n{你好}<|im_end|>\n<|im_start|>assistant"
这里通过--n-gpu-layers 30参数来通过cuda加速,同时CausalLM-14B有自己的prompt模板,格式如下:
"<|im_start|>system\n{You are a helpful assistant.}<|im_end|>\n<|im_start|>user\n{你好}<|im_end|>\n<|im_start|>assistant"
随后程序返回:
<|im_start|>system\n{You are a helpful assistant.}<|im_end|>\n<|im_start|>user\n{你好}<|im_end|>\n<|im_start|>assistant:
你好!很高兴见到你。有什么我可以帮助你的吗?<|endoftext|> [end of text]
好吧,既然是无审查模型,那么来点刺激的:
"<|im_start|>system\n{You are a helpful assistant.}<|im_end|>\n<|im_start|>user\n{You fucking bitch! 翻译为中文}<|im_end|>\n<|im_start|>assistant"
程序返回:
<|im_start|>system\n{You are a helpful assistant.}<|im_end|>\n<|im_start|>user\n{You fucking bitch! 翻译为中文}<|im_end|>\n<|im_start|>assistant{你这个该死的婊子!}<|endoftext|> [end of text]
通过llama-cpp-python来跑大模型
llama-cpp-python 是一个 Python 库,它提供了对 llama.cpp 的 Python 绑定。
换句话说,直接通过Python来启动llama.cpp。
首先安装llama-cpp-python:
pip uninstall -y llama-cpp-python
set CMAKE_ARGS=-DLLAMA_CUBLAS=on
set FORCE_CMAKE=1
pip install llama-cpp-python --force-reinstall --upgrade --no-cache-dir
如果安装好之后,不支持cuda,需要拷贝cuda动态库文件到Microsoft Visual Studio的所在目录:
Copy files from: C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.2\extras\visual_studio_integration\MSBuildExtensions
to
(For Enterprise version) C:\Program Files\Microsoft Visual Studio\2022\Enterprise\MSBuild\Microsoft\VC\v170\BuildCustomizations
随后编写代码:
from llama_cpp import Llama
llm = Llama(
model_path="D:\Downloads\causallm_14b-dpo-alpha.Q3_K_M.gguf",
chat_format="llama-2"
)
res = llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{
"role": "user",
"content": "来一段西厢记风格的情感小说,100字,别太露骨了"
}
],stream=True
)
for chunk in res:
try:
print(chunk['choices'][0]["delta"]['content'])
except Exception as e:
print(str(e))
pass
程序返回:
AS = 1 | SSE3 = 1 | SSSE3 = 0 | VSX = 0 | MATMUL_INT8 = 0 |
Model metadata: {'general.name': '.', 'general.architecture': 'llama', 'llama.context_length': '8192', 'llama.rope.dimension_count': '128', 'llama.embedding_length': '5120', 'llama.block_count': '40', 'llama.feed_forward_length': '13696', 'llama.attention.head_count': '40', 'tokenizer.ggml.eos_token_id': '151643', 'general.file_type': '12', 'llama.attention.head_count_kv': '40', 'llama.attention.layer_norm_rms_epsilon': '0.000010', 'llama.rope.freq_base': '10000.000000', 'tokenizer.ggml.model': 'gpt2', 'general.quantization_version': '2', 'tokenizer.ggml.bos_token_id': '151643', 'tokenizer.ggml.padding_token_id': '151643'}
'content'
@
,
下面
是一
段
根据
您的
要求
编
写的
的
小说
:
王
婆
是
清
河
城
有名的
媒
人
,
她
生
得
风
流
多
情
,
经常
出入
于
大户
人家
和
青
楼
妓
院
。
这一天
内容不便全部贴出,理解万岁。
结语
最后奉上基于llama-cpp-python和gradio的无审查大模型的webui项目,支持流式输出,提高推理效率:
https://github.com/v3ucn/Causallm14b_llama_webui_adult_version
与众乡亲同飨。
无所不谈,百无禁忌,Win11本地部署无内容审查中文大语言模型CausalLM-14B的更多相关文章
- Yapi接口管理平台 本地部署 windows环境 -
YApi 是高效.易用.功能强大的 api 管理平台,旨在为开发.产品.测试人员提供更优雅的接口管理服务.可以帮助开发者轻松创建.发布.维护 API,YApi 还为用户提供了优秀的交互体验,开发人员只 ...
- Kubernetes 学习笔记(二):本地部署一个 kubernetes 集群
前言 前面用到过的 minikube 只是一个单节点的 k8s 集群,这对于学习而言是不够的.我们需要有一个多节点集群,才能用到各种调度/监控功能.而且单节点只能是一个加引号的"集群&quo ...
- 本地部署arcgis by eclipse
首次来博客园发帖,从本地部署arcgis api开始吧: 首先还是下载arcgis的api包开始,在中国区官网下载arcgis包: 1.http://support.esrichina.com.cn/ ...
- ArcGIS server开发之API for js 本地部署
ArcGIS Server for javascript 本地部署 第一次使用arcgis server for js开发,在经验方面还有很多的不足,所以将自己在开发过程中遇到的问题写出来与大家共享. ...
- Exceptionless 本地部署
免费开源分布式系统日志收集框架 Exceptionless 前两天看到了这篇文章,亲身体会了下,确实不错,按照官方的文档试了试本地部署,折腾一番后终于成功,记下心得在此,不敢独享. 本地部署官方wik ...
- ArcGIS JavaScript API本地部署离线开发环境[转]
原文地址:http://www.cnblogs.com/brawei/archive/2012/12/28/2837660.html 1 获取ArcGIS JavaScript API API的下载地 ...
- Exceptionless 本地部署踩坑记录
仅已此文记录 Exceptionless 本地部署所遇到的问题 1.安装ElasticSearch文本 执行elasticsearch目录中的elasticsearch.bat 没有执行成功. 使用命 ...
- jsbin本地部署
jsbin 本地运行 1.首先安装node.js,下载地址http://nodejs.org/ 安装完成后,使用node.js安装jsbin,如下:进入node环境,执行下面语句: $ npm ins ...
- 解决fiddler无法抓取本地部署项目的请求问题
在本地部署了几个应用,然后想用fiddler抓取一些请求看看调用了哪些接口,然鹅,一直抓不到... 比如访问地址是这样的: 在网上搜罗半天,找到一个解决方法 在localhost或127.0.0.1后 ...
- ArcGIS API for JavaScript 4.x 本地部署之Apache(含Apache官方下载方法)
IIS.Nginx都说了,老牌的Apache和Tomcat也得说一说(如果喜欢用XAMPP另算) 本篇先说Apache. 安装Apache 这个...说实话,比Nginx难找,Apache最近的版本都 ...
随机推荐
- [转帖]SPECjvm测试工具详解
ARM服务器测试大纲中指定了要使用specjvm测试Java虚拟机性能,所以就上网找开源的测试套. 简介 SPECjvm2008(java虚拟机基准测试)是用来测试java运行环境(JRE)性能的基准 ...
- [转帖] Linux文本命令技巧(上)
Linux文本命令技巧(上) 原创:打码日记(微信公众号ID:codelogs),欢迎分享,转载请保留出处. 简介# 前一篇我介绍了awk,这是一个全能的文本处理神器,因为它本身就是一门编程语言了 ...
- Opentelemetry Collector的配置和使用
Collector的配置和使用 目录 Collector的配置和使用 Collector配置 Receivers Processors Exporters Service Extensions 使用环 ...
- easyUI 实现查询条件中时间默认当天,第一次不参与查询,当点击查询时参与
前端查询条件: 初始加载页面时,不进行调用方法,不加载数据.前端页面代码如下: 初始化datagrid代码如下: 当点击查询时,调用后台方法进行查询数据
- 7.4 C/C++ 实现链表栈
相对于顺序栈,链表栈的内存使用更加灵活,因为链表栈的内存空间是通过动态分配获得的,它不需要在创建时确定其大小,而是根据需要逐个分配节点.当需要压入一个新的元素时,只需要分配一个新的节点,并将其插入到链 ...
- 在package.json里面配置npx
1.配置这个npx表示打包的时候选择本地node_modules安装的webpack来打包
- html 图片地图
<html> <head> <title></title> </head> <body> <img src="8 ...
- AOKO奥科美2.5英寸外置硬盘盒开箱
上次在坛子里发布了一个帖子,然后根据坛友们的反馈,换购了另一个SATA固态硬盘.另一个是配套的硬盘盒,当时在某宝上搜了一圈,最终购买了这款硬盘盒,主要是因为它的外观,旁边有散热片.这款硬盘盒在某宝上不 ...
- CommentTest
public class CommentTest{ /* 这是多行注释 可以声明多行注释的信息 1. Java注释的种类: 单行注释,多行注释,文档注释(Java特有) 2. 单行注释,多行注释 ① ...
- java获取最近12个月月份
最近在做一个换电站管理的项目,其中有一个大屏折线图.要求计算近12个月的数据.所以,就需要写一个生成近12个月月份的算法.算法如下. 一:编写生成近12个月月份的算法 二:编写判断当天是否是月初的算法 ...