Python爬虫爬取爱奇艺电影片库首页
1 import time
2 import traceback
3 import requests
4 from lxml import etree
5 import re
6 from bs4 import BeautifulSoup
7 from lxml.html.diff import end_tag
8 import json
9 import pymysql
10 #连接数据库 获取游标
11 def get_conn():
12 """
13 :return: 连接,游标
14 """
15 # 创建连接
16 conn = pymysql.connect(host="82.157.112.34",
17 user="root",
18 password="root",
19 db="MovieRankings",
20 charset="utf8")
21 # 创建游标
22 cursor = conn.cursor() # 执行完毕返回的结果集默认以元组显示
23 if ((conn != None) & (cursor != None)):
24 print("数据库连接成功!游标创建成功!")
25 else:
26 print("数据库连接失败!")
27 return conn, cursor
28 #关闭数据库连接和游标
29 def close_conn(conn, cursor):
30 if cursor:
31 cursor.close()
32 if conn:
33 conn.close()
34 return 1
35 def get_iqy():
36 # 获取数据库总数据条数
37 conn, cursor = get_conn()
38 sql = "select count(*) from movieiqy"
39 cursor.execute(sql) # 执行sql语句
40 conn.commit() # 提交事务
41 all_num = cursor.fetchall()[0][0] #cursor 返回值的类型是一个元祖的嵌套形式 比如( ( ) ,)
42 pagenum=int(all_num/48)+1 #这里是计算一个下面循环的起始值 每48个电影分一组
43 print(pagenum)
44 print("movieiqy数据库有", all_num, "条数据!")
45
46
47 url = "https://pcw-api.iqiyi.com/search/recommend/list?channel_id=1&data_type=1&mode=11&page_id=1&ret_num=48&session=ee4d98ebb4e8e44c8d4b14fa90615fb7"
48 headers = {
49 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
50 }
51 # response=requests.get(url=url,headers=headers)
52 # response.encoding="utf-8"
53 # page_text=response.text
54 # print(page_text)
55 """
56 """
57 #
58 temp_list = [] #暂时存放单部电影的数据
59 dataRes = [] #每次循环把单部电影数据放到这个list
60 for i in range(pagenum+1, pagenum+100): #循环100-1次
61 url = "https://pcw-api.iqiyi.com/search/recommend/list?channel_id=1&data_type=1&mode=11&page_id=1&ret_num=48&session=ee4d98ebb4e8e44c8d4b14fa90615fb7"
62 url_0 = "https://pcw-api.iqiyi.com/search/recommend/list?channel_id=1&data_type=1&mode=11&page_id="
63 url_0 = url_0 + str(i) + "&ret_num=48&session=ad1d98bb953b7e5852ff097c088d66f2"
64 print(url_0) #输出拼接好的url
65 response = requests.get(url=url_0, headers=headers)
66 response.encoding = "utf-8"
67 page_text = response.text
68 #解析json对象
69 json_obj = json.loads(page_text)
70 #这里的异常捕获是因为 测试循环的次数有可能超过电影网站提供的电影数 为了防止后续爬到空的json对象报错
71 try:
72 json_list = json_obj['data']['list']
73 except KeyError:
74 return dataRes #json为空 程序结束
75 for j in json_list: # 开始循环遍历json串
76 # print(json_list)
77 name = j['name'] #找到电影名
78 print(name)
79 temp_list.append(name)
80 #异常捕获,防止出现电影没有评分的现象
81 try:
82 score = j['score'] #找到电影评分
83 print(score)
84 temp_list.append(score)
85 except KeyError:
86 print( "KeyError")
87 temp_list.append("iqy暂无评分") #替换字符串
88
89 link = j['playUrl'] #找到电影链接
90 temp_list.append(link)
91 # 解析播放状态
92 state = []
93 pay_text = j['payMarkUrl'] #因为播放状态只有在一个图片链接里有 所以需要使用re解析出类似vip和only(独播)的字样
94 if (len(pay_text) == 0): #如果没有这个图片链接 说明电影是免费播放
95 state="免费"
96 else:
97 find_state = re.compile("(.*?).png")
98 state = re.findall(find_state, pay_text) #正则匹配链接找到vip
99 if(len(state)!=0): #只有当链接不为空再执行
100 # print(state)
101 # 再次解析
102 state = state[0][0:3] #字符串分片
103
104 # 这里只输出了三个字符,如果是独播,页面显示的是only,我们设置为”独播“
105 if (state == "onl"):
106 state = "独播"
107 else:
108 state = "VIP"
109 # print(state)
110 # 添加播放状态
111 temp_list.append(state)
112 dataRes.append(temp_list)
113 # print(temp_list)
114 temp_list = []
115
116 print('___________________________')
117 return dataRes
118
119 def insert_iqy():
120 cursor = None
121 conn = None
122 try:
123 count=0
124 list = get_iqy()
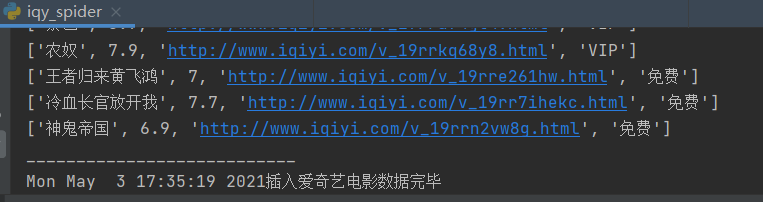
125 print(f"{time.asctime()}开始插入爱奇艺电影数据")
126 conn, cursor = get_conn()
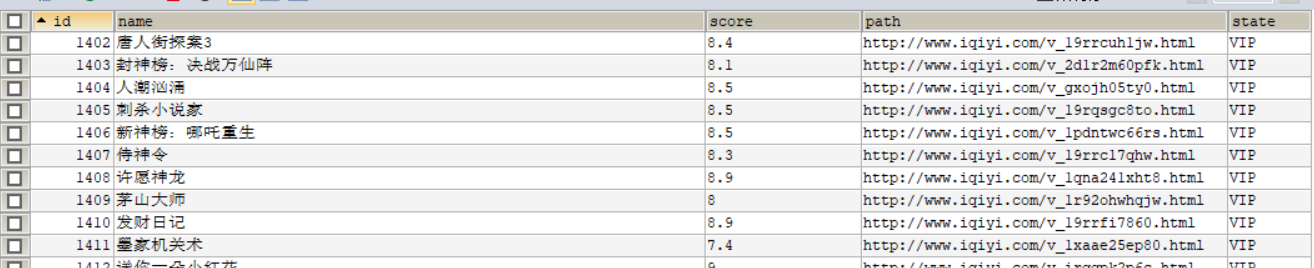
127 sql = "insert into movieiqy (id,name,score,path,state) values(%s,%s,%s,%s,%s)"
128 for item in list:
129 print(item)
130 count = count + 1
131 if (count % 48 == 0):
132 print('___________________________')
133 #异常捕获,防止数据库主键冲突
134 try:
135 cursor.execute(sql, [0, item[0], item[1], item[2], item[3] ])
136 except pymysql.err.IntegrityError:
137 print("重复!跳过!")
138
139 conn.commit() # 提交事务 update delete insert操作
140 print(f"{time.asctime()}插入爱奇艺电影数据完毕")
141 except:
142 traceback.print_exc()
143 finally:
144 close_conn(conn, cursor)
145 return;
146
147 if __name__ == '__main__':
148 # get_iqy()
149 insert_iqy()
数据获取方式:微信搜索关注【靠谱杨阅读人生】回复【电影】。
整理不易,资源付费,谢谢支持。
Python爬虫爬取爱奇艺电影片库首页的更多相关文章
- 如何利用python爬虫爬取爱奇艺VIP电影?
环境:windows python3.7 思路: 1.先选取你要爬取的电影 2.用vip解析工具解析,获取地址 3.写好脚本,下载片断 4.将片断利用电脑合成 需要的python模块: ##第一 ...
- 使用selenium 多线程爬取爱奇艺电影信息
使用selenium 多线程爬取爱奇艺电影信息 转载请注明出处. 爬取目标:每个电影的评分.名称.时长.主演.和类型 爬取思路: 源文件:(有注释) from selenium import webd ...
- Python爬虫实战案例:爬取爱奇艺VIP视频
一.实战背景 爱奇艺的VIP视频只有会员能看,普通用户只能看前6分钟.比如加勒比海盗5的URL:http://www.iqiyi.com/v_19rr7qhfg0.html#vfrm=19-9-0-1 ...
- Python 爬虫实例(5)—— 爬取爱奇艺视频电视剧的链接(2017-06-30 10:37)
1. 我们找到 爱奇艺电视剧的链接地址 http://list.iqiyi.com/www/2/-------------11-1-1-iqiyi--.html 我们点击翻页发现爱奇艺的链接是这样的 ...
- Python爬取爱奇艺资源
像iqiyi这种视频网站,现在下载视频都需要下载相应的客户端.那么如何不用下载客户端,直接下载非vip视频? 选择你想要爬取的内容 该安装的程序以及运行环境都配置好 下面这段代码就是我在爱奇艺里搜素“ ...
- Python爬取爱奇艺【老子传奇】评论数据
# -*- coding: utf-8 -*- import requests import os import csv import time import random base_url = 'h ...
- 爬取爱奇艺电视剧url
----因为需要顺序,所有就用串行了---- import requests from requests.exceptions import RequestException import re im ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
随机推荐
- Java集合框架学习(十) LinkedHashMap详解
LinkedHashMap介绍 1.Key和Value都允许null: 2.维护key的插入顺序: 3.非线程安全: 4.Key重复会覆盖.Value允许重复. 类定义 public class Li ...
- spring事务的传播
目录 事务的传播行为类型 注意事项 关于事务的传播,我们先确定一个场景:方法A调用方法B,方法A可能存在事务,也可能不存在事务,我们这里重点关注方法B上定义的事务传播行为,以及方法B中出现异常时,方法 ...
- SpringBoot整合Swagger2实现接口文档
展示一下 访问方式一 访问地址:http://localhost:8080/swagger-ui.html#/ 首页 详情页 访问方式二 访问地址:http://localhost:8080/doc. ...
- sliver生成木马.sh
生成sliver木马多个步骤合成一个sh #!/bin/bash # date: 20230222 host_ip=$1 WORK_DIR=/opt/work rm -rf /root/.sliver ...
- pinia
Pinia学习 Vue3中 使用 官网:https://pinia.web3doc.top/introduction.html 安装 yarn add pinia # 或者使用 npm npm ins ...
- 临时修改session日期格式冲突问题
输入的格式要看你安装的ORACLE字符集的类型, 比如: US7ASCII, date格式的类型就是: '01-Jan-01' alter session set NLS_DATE_LANGUAGE ...
- VUE 腾讯云 web端上传视频SDK 上传进度无法显示
上传视频官方文档:https://cloud.tencent.com/document/product/266/9239 错误信息 在本地调试可以显示视频上传进度,也可以打印到浏览器控制台.但是,发布 ...
- RocketMQ(10) 消息类型
一.普通消息 1. 消息发送方式分类 Producer对于消息的发送方式也有多种选择,不同的方式会产生不同的系统效果. 同步发送消息: 同步发送消息是指,Producer发出⼀条消息后,会在收到MQ返 ...
- Codeforces Round 170 (Div. 1)A. Learning Languages并查集
如果两个人会的语言中有共同语言那么他们之间就可以交流,并且如果a和b可以交流,b和c可以交流,那么a和c也可以交流,具有传递性,就容易联想到并查集,我们将人和语言看成元素,一个人会几种语言的话,就将这 ...
- 快速带你入门css
css复习笔记 1. css样式值 1.1 文字样式 1 p{ 2 font-size: 30px;/*设置文字大小*/ 3 font-weight: bold;/*文字加粗*/ 4 font-sty ...