2023-09-13:用go语言,给定一个整数数组 nums 和一个正整数 k, 找出是否有可能把这个数组分成 k 个非空子集,其总和都相等。 输入: nums = [4, 3, 2, 3, 5,
2023-09-13:用go语言,给定一个整数数组 nums 和一个正整数 k,
找出是否有可能把这个数组分成 k 个非空子集,其总和都相等。
输入: nums = [4, 3, 2, 3, 5, 2, 1], k = 4。
输出: True。
来自左程云。
答案2023-09-13:
第一种算法(canPartitionKSubsets1)使用动态规划的思想,具体过程如下:
1.计算数组nums的总和sum。如果sum不能被k整除,则直接返回false。
2.调用process1函数,传入数组nums、status初始值为0、sum初始值为0、sets初始值为0、limit为sum/k、k和一个空的dp map。
3.在process1函数中,首先检查dp map,如果已经计算过该状态,则直接返回dp[status]。
4.如果sets等于k,表示已经找到k个非空子集,返回1。
5.遍历数组nums,对于每个数字nums[i],判断该数字是否可以加入到当前的子集中。
6.如果当前子集的和加上nums[i]等于limit,则将状态status的第i位设置为1,sum重置为0,sets加1,继续递归调用process1函数。
7.如果当前子集的和加上nums[i]小于limit,则将状态status的第i位设置为1,sum加上nums[i],sets保持不变,继续递归调用process1函数。
8.如果递归调用的结果为1,则表示找到了满足条件的分组,设置ans为1,并跳出循环。
9.更新dp map,将状态status对应的结果ans存入dp[status],并返回ans。
第二种算法(canPartitionKSubsets2)使用回溯的思想,具体过程如下:
1.计算数组nums的总和sum。如果sum不能被k整除,则直接返回false。
2.将数组nums按照从大到小的顺序排序。
3.创建一个长度为k的数组group,用于存放k个子集的和,初始值都为0。
4.调用partitionK函数,传入group、sum/k、排序后的nums数组和nums数组的长度-1。
5.在partitionK函数中,如果index小于0,表示已经遍历完了数组nums,此时返回true。
6.取出nums[index]作为当前要放入子集的数字。
7.遍历group数组,对于group数组中的每个元素group[i],如果将当前数字nums[index]放入到group[i]中不超过目标和target,则将该数字放入group[i]。
8.递归调用partitionK函数,传入更新过的group、target、nums和index-1。
9.如果递归调用的结果为true,则表示找到了满足条件的分组,返回true。
10.从i+1开始,减少重复计算,跳过和group[i]相等的元素。
11.返回false。
第一种算法的时间复杂度为O(k * 2^n),其中n是数组nums的长度,对于每个状态,需要遍历一次nums数组。
第二种算法的时间复杂度为O(k * n * 2^n),其中n是数组nums的长度,对于每个状态,需要遍历一次group数组和nums数组。
第一种算法的额外空间复杂度为O(2^n),用于存储dp map。
第二种算法的额外空间复杂度为O(k),用于存储group数组。
go完整代码如下:
package main
import (
"fmt"
"sort"
)
func canPartitionKSubsets1(nums []int, k int) bool {
sum := 0
for _, num := range nums {
sum += num
}
if sum%k != 0 {
return false
}
return process1(nums, 0, 0, 0, sum/k, k, make(map[int]int)) == 1
}
func process1(nums []int, status, sum, sets, limit, k int, dp map[int]int) int {
if ans, ok := dp[status]; ok {
return ans
}
ans := -1
if sets == k {
ans = 1
} else {
for i := 0; i < len(nums); i++ {
if (status&(1<<i)) == 0 && sum+nums[i] <= limit {
if sum+nums[i] == limit {
ans = process1(nums, status|(1<<i), 0, sets+1, limit, k, dp)
} else {
ans = process1(nums, status|(1<<i), sum+nums[i], sets, limit, k, dp)
}
if ans == 1 {
break
}
}
}
}
dp[status] = ans
return ans
}
func canPartitionKSubsets2(nums []int, k int) bool {
sum := 0
for _, num := range nums {
sum += num
}
if sum%k != 0 {
return false
}
sort.Ints(nums)
return partitionK(make([]int, k), sum/k, nums, len(nums)-1)
}
func partitionK(group []int, target int, nums []int, index int) bool {
if index < 0 {
return true
}
num := nums[index]
len := len(group)
for i := 0; i < len; i++ {
if group[i]+num <= target {
group[i] += num
if partitionK(group, target, nums, index-1) {
return true
}
group[i] -= num
for i+1 < len && group[i] == group[i+1] {
i++
}
}
}
return false
}
func main() {
nums := []int{4, 3, 2, 3, 5, 2, 1}
k := 4
fmt.Println(canPartitionKSubsets1(nums, k))
fmt.Println(canPartitionKSubsets2(nums, k))
}
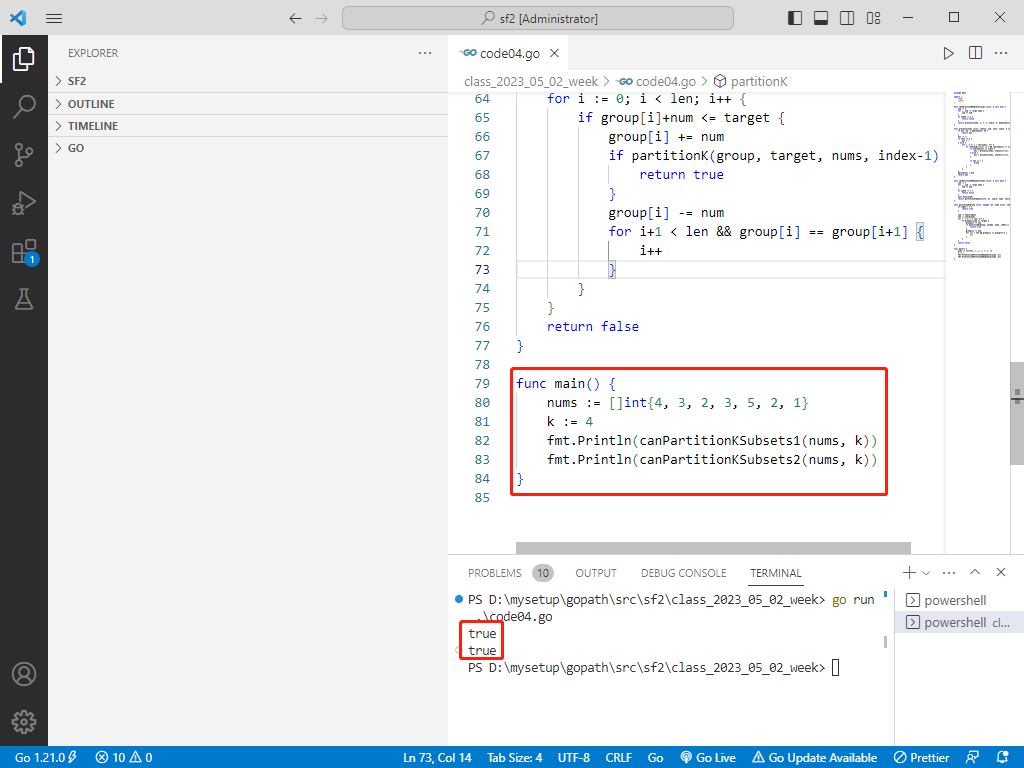
rust完整代码如下:
fn can_partition_k_subsets1(nums: Vec<i32>, k: i32) -> bool {
let sum: i32 = nums.iter().sum();
if sum % k != 0 {
return false;
}
let mut dp: Vec<i32> = vec![0; 1 << nums.len()];
process1(nums, 0, 0, 0, sum / k, k, &mut dp) == 1
}
fn process1(
nums: Vec<i32>,
status: usize,
sum: i32,
sets: i32,
limit: i32,
k: i32,
dp: &mut Vec<i32>,
) -> i32 {
if dp[status] != 0 {
return dp[status];
}
let mut ans = -1;
if sets == k {
ans = 1;
} else {
for i in 0..nums.len() {
if (status & (1 << i)) == 0 && sum + nums[i] <= limit {
if sum + nums[i] == limit {
ans = process1(nums.clone(), status | (1 << i), 0, sets + 1, limit, k, dp);
} else {
ans = process1(
nums.clone(),
status | (1 << i),
sum + nums[i],
sets,
limit,
k,
dp,
);
}
if ans == 1 {
break;
}
}
}
}
dp[status] = ans;
return ans;
}
fn can_partition_k_subsets2(nums: Vec<i32>, k: i32) -> bool {
let sum: i32 = nums.iter().sum();
if sum % k != 0 {
return false;
}
let mut sorted_nums = nums.clone();
sorted_nums.sort();
partition_k(
&mut vec![0; k as usize],
sum / k,
&sorted_nums,
(sorted_nums.len() - 1) as i32,
)
}
fn partition_k(group: &mut Vec<i32>, target: i32, nums: &Vec<i32>, index: i32) -> bool {
if index < 0 {
return true;
}
let num = nums[index as usize];
let len = group.len() as i32;
for mut i in 0..len {
if group[i as usize] + num <= target {
group[i as usize] += num;
if partition_k(group, target, nums, index - 1) {
return true;
}
group[i as usize] -= num;
while i + 1 < group.len() as i32 && group[i as usize] == group[(i + 1) as usize] {
i += 1;
}
}
}
false
}
fn main() {
let nums = vec![4, 3, 2, 3, 5, 2, 1];
let k = 4;
let result1 = can_partition_k_subsets1(nums.clone(), k);
let result2 = can_partition_k_subsets2(nums.clone(), k);
println!("Result using can_partition_k_subsets1: {}", result1);
println!("Result using can_partition_k_subsets2: {}", result2);
}
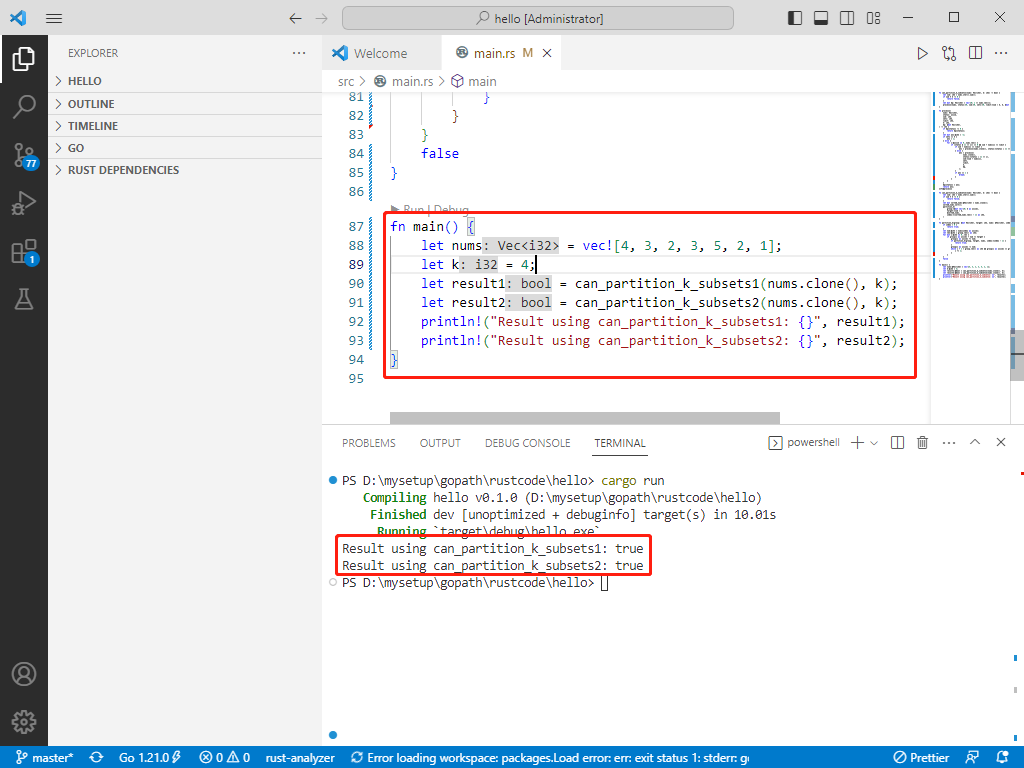
c++完整代码如下:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
bool process1(vector<int>& nums, int status, int sum, int sets, int limit, int k, vector<int>& dp) {
if (dp[status] != 0) {
return dp[status] == 1;
}
bool ans = false;
if (sets == k) {
ans = true;
}
else {
for (int i = 0; i < nums.size(); i++) {
if ((status & (1 << i)) == 0 && sum + nums[i] <= limit) {
if (sum + nums[i] == limit) {
ans = process1(nums, status | (1 << i), 0, sets + 1, limit, k, dp);
}
else {
ans = process1(nums, status | (1 << i), sum + nums[i], sets, limit, k, dp);
}
if (ans) {
break;
}
}
}
}
dp[status] = ans ? 1 : -1;
return ans;
}
bool canPartitionKSubsets1(vector<int>& nums, int k) {
int sum = 0;
for (int num : nums) {
sum += num;
}
if (sum % k != 0) {
return false;
}
vector<int> dp(1 << nums.size(), 0);
return process1(nums, 0, 0, 0, sum / k, k, dp);
}
bool partitionK(vector<int>& group, int target, vector<int>& nums, int index) {
if (index < 0) {
return true;
}
int num = nums[index];
int len = group.size();
for (int i = 0; i < len; i++) {
if (group[i] + num <= target) {
group[i] += num;
if (partitionK(group, target, nums, index - 1)) {
return true;
}
group[i] -= num;
while (i + 1 < group.size() && group[i] == group[i + 1]) {
i++;
}
}
}
return false;
}
bool canPartitionKSubsets2(vector<int>& nums, int k) {
int sum = 0;
for (int num : nums) {
sum += num;
}
if (sum % k != 0) {
return false;
}
sort(nums.begin(), nums.end());
vector<int> t = vector<int>(k, 0);
return partitionK(t, sum / k, nums, nums.size() - 1);
}
int main()
{
vector<int> nums = { 4, 3, 2, 3, 5, 2, 1 };
int k = 4;
bool result1 = canPartitionKSubsets1(nums, k);
cout << "Result using canPartitionKSubsets1: " << (result1 ? "true" : "false") << endl;
bool result2 = canPartitionKSubsets2(nums, k);
cout << "Result using canPartitionKSubsets2: " << (result2 ? "true" : "false") << endl;
return 0;
}
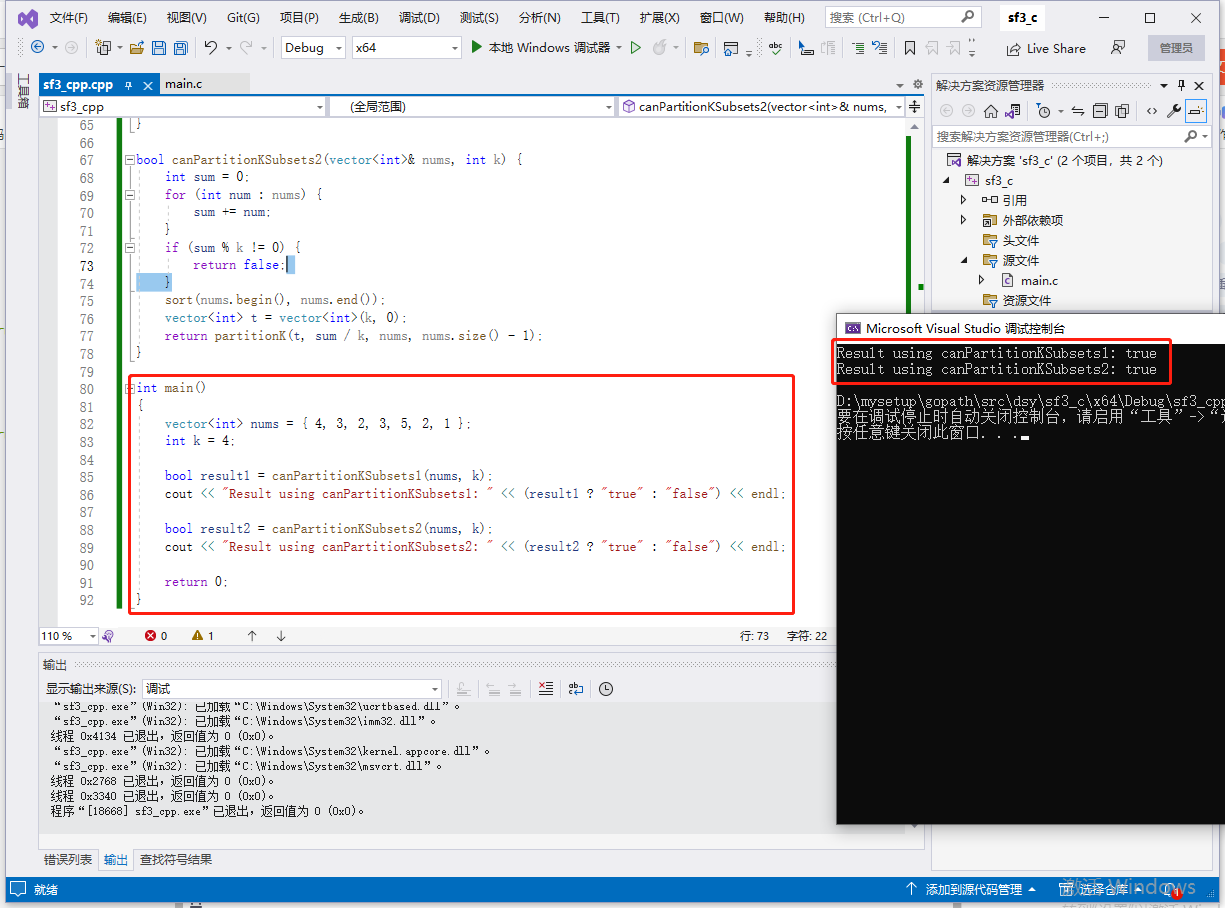
c完整代码如下:
#include <stdio.h>
#include <stdbool.h>
#include <stdlib.h>
int process1(int* nums, int numsSize, int status, int sum, int sets, int limit, int k, int* dp) {
if (dp[status] != 0) {
return dp[status];
}
int ans = -1;
if (sets == k) {
ans = 1;
}
else {
for (int i = 0; i < numsSize; i++) {
if ((status & (1 << i)) == 0 && sum + nums[i] <= limit) {
if (sum + nums[i] == limit) {
ans = process1(nums, numsSize, status | (1 << i), 0, sets + 1, limit, k, dp);
}
else {
ans = process1(nums, numsSize, status | (1 << i), sum + nums[i], sets, limit, k, dp);
}
if (ans == 1) {
break;
}
}
}
}
dp[status] = ans;
return ans;
}
bool canPartitionKSubsets1(int* nums, int numsSize, int k) {
int sum = 0;
for (int i = 0; i < numsSize; i++) {
sum += nums[i];
}
if (sum % k != 0) {
return false;
}
int* dp = (int*)malloc((1 << numsSize) * sizeof(int));
for (int i = 0; i < (1 << numsSize); i++) {
dp[i] = 0;
}
bool result = process1(nums, numsSize, 0, 0, 0, sum / k, k, dp) == 1;
free(dp);
return result;
}
bool partitionK(int* group, int target, int* nums, int index, int len) {
if (index < 0) {
return true;
}
int num = nums[index];
for (int i = 0; i < len; i++) {
if (group[i] + num <= target) {
group[i] += num;
if (partitionK(group, target, nums, index - 1, len)) {
return true;
}
group[i] -= num;
while (i + 1 < len && group[i] == group[i + 1]) {
i++;
}
}
}
return false;
}
bool canPartitionKSubsets2(int* nums, int numsSize, int k) {
int sum = 0;
for (int i = 0; i < numsSize; i++) {
sum += nums[i];
}
if (sum % k != 0) {
return false;
}
for (int i = 0; i < numsSize; i++) {
for (int j = i + 1; j < numsSize; j++) {
if (nums[i] < nums[j]) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
}
}
int target = sum / k;
int* group = (int*)malloc(k * sizeof(int));
for (int i = 0; i < k; i++) {
group[i] = 0;
}
bool result = partitionK(group, target, nums, numsSize - 1, k);
free(group);
return result;
}
int main() {
int nums[] = { 4, 3, 2, 3, 5, 2, 1 };
int numsSize = sizeof(nums) / sizeof(nums[0]);
int k = 4;
bool result1 = canPartitionKSubsets1(nums, numsSize, k);
bool result2 = canPartitionKSubsets2(nums, numsSize, k);
printf("Result from canPartitionKSubsets1: %s\n", result1 ? "true" : "false");
printf("Result from canPartitionKSubsets2: %s\n", result2 ? "true" : "false");
return 0;
}
2023-09-13:用go语言,给定一个整数数组 nums 和一个正整数 k, 找出是否有可能把这个数组分成 k 个非空子集,其总和都相等。 输入: nums = [4, 3, 2, 3, 5,的更多相关文章
- 【c语言】数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字
题目:数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字. 比如输入一个长度为9的数组{1,2.3.2,2.2.5,4.2}, 因为数组中数字2出现了5次,超过数组的长度的一半,因此输出2 ...
- 给定两个list A ,B,请用找出 A ,B中相同的元素,A ,B中不同的元素 ??
A.B 中相同元素:print(set(A)&set(B)) A.B 中不同元素:print(set(A)^set(B))
- 很火的Java题——判断一个整数是否是奇数
完成以下代码,判断一个整数是否是奇数: public boolean isOdd(int i) 看过<编程珠玑>的人都知道这道题的答案和其中极为简单的道理. 最普遍的风格,如下: 这个函数 ...
- 刷题之给定一个整数数组 nums 和一个目标值 taget,请你在该数组中找出和为目标值的那 两个 整数
今天下午,看了一会github,想刷个题呢,就翻出来了刷点题提高自己的实际中的解决问题的能力,在面试的过程中,我们发现,其实很多时候,面试官 给我们的题,其实也是有一定的随机性的,所以我们要多刷更多的 ...
- 给定一个整数数组 nums 和一个目标值 target,求nums和为target的两个数的下表
这个是来自力扣上的一道c++算法题目: 给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标. 你可以假设每种输入只会对应一个答案 ...
- 给定一个整数数组nums和一个整数目标值target,请你在该数组中找出和为目标值target的那两个整数,并返回它们的数组下标。
/** * 给定一个整数数组nums和一个整数目标值target,请你在该数组中找出和为目标值target的那两个整数,并返回它们的数组下标. * * 你可以假设每种输入只会对应一个答案.但是,数组中 ...
- 【C语言】输入一个整数N,求N以内的素数之和
[C语言]输入一个整数N,求N以内的素数之和 /* ========================================================================== ...
- 在排序数组中查找元素的第一个和最后一个位置(给定一个按照升序排列的整数数组 nums,和一个目标值 target。找出给定目标值在数组中的开始位置和结束位置。)
示例 1: 输入: nums = [5,7,7,8,8,10], target = 8 输出: [3,4] 示例 2: 输入: nums = [5,7,7,8,8,10], target = 6 输出 ...
- C语言必会面试题(3、耶稣有13个门徒,当中有一个就是出卖耶稣的叛徒,请用排除法找出这位叛徒:13人围坐一圈,从第一个開始报号:1,2,3,1,2,3...。凡是报到“3”就退出圈子,...)
3.耶稣有13个门徒.当中有一个就是出卖耶稣的叛徒,请用排除法找出这位叛徒:13人围坐一圈,从第一个開始报号:1.2,3.1,2,3.... 凡是报到"3"就退出圈子.最后留在圈子 ...
- C语言:找出一个大于给定整数m且紧随m的素数,-求出能整除x且不是偶数的数的个数,
//函数fun功能:找出一个大于给定整数m且紧随m的素数,并作为函数值返回. #include <stdlib.h> #include <conio.h> #include & ...
随机推荐
- docker容器管理脚本
#!/bin/bash #auto install docker and Create VM #by jfedu.net 2017 #Define PATH Varablies IPADDR=`ifc ...
- CSP2023 模拟赛总结合集
9.9 ZZFLS 感觉 ucup 剩下的题完全不可做了啊!先对比赛时间来写总结对队友道歉(鞠躬.jpg 开题策略很失败.开场 30min 得的分数是一整场考试的分数. 开题,发现 T1 是水题,30 ...
- ASP.NET CORE MVC的一些说明
1.ASP.NET CORE MVC 是微软公司的Web应用开发框架,结合了MVC架构的高效.简洁等优秀思想并融合了.NET的灵活性. 2.ASP.NET诞生于2002年,当时微软想保持桌面应用程序的 ...
- React 基础介绍以及demo实践
这篇文章是之前给新同事培训react基础所写的文章,现贴这里供大家参考: 1.什么是React? React 是一个用于构建用户界面的JavaScript库核心专注于视图,目的实现组件化开发 2.组件 ...
- C++基础杂记(3)
类的继承 基类与派生类之间的构造行为 在派生类中使用基类方法 protected 的访问权限 多态公有继承 关键字 virtual 示例 抽象基类(ABC) 私有继承和保护继承 多重继承 类的继承 基 ...
- websocket和ajax的区别(和http的区别)
websocket和ajax的区别(和http的区别) https://segmentfault.com/a/1190000021741131 1. 本质不同 ajax,即异步JavaScript和X ...
- SpringBoot+Redis实现接口级别缓存信息
本文主要讲述如何通过SpringBoot+Redis实现接口级别缓存信息 背景 近期因为一直在处理公司的老项目,恰好碰到产品说页面有一些信息展示慢,简单看了一下页面接口,发现查询的是系统中几张大表(数 ...
- 编译wasm Web应用
刚学完WebAssembly的入门课,卖弄一点入门知识. 首先我们知道wasm是目标语言,是一种新的V-ISA标准,所以编写wasm应用,正常来说不会直接使用WAT可读文本格式,更不会用wasm字节码 ...
- Linux 本地AMH 服务器管理面板实现远程访问方法
AMH 是一款基于 Linux 系统的服务器管理面板,它提供了一系列的功能,包括网站管理.FTP 管理.数据库管理.DNS 管理.SSL 证书管理等.使用 AMH 云主机面板可以方便地管理服务器,提高 ...
- 决策树C4.5算法的技术深度剖析、实战解读
在本篇深入探讨的文章中,我们全面分析了C4.5决策树算法,包括其核心原理.实现流程.实战案例,以及与其他流行决策树算法(如ID3.CART和Random Forests)的比较.文章不仅涵盖了丰富的理 ...