【一】分布式训练---单机多卡多机多卡(飞桨paddle1.8)
1.分布式训练简介
分布式训练的核心目的:
加快模型的训练速度。通过对训练任务按照一定方法拆分分配到多个计算节点进行计算,再按照一定的方法对需要汇总的信息进行聚合,从而实现加快训练速度的目的。
1.1 分布式训练的并行方式
在实际应用中,对训练任务的拆分方法是比较有限的,通常有如下几种:
数据并行:将数据集切分放到各计算节点,每个计算节点的计算内容完全一致,并在多个计算节点之间同步模型参数,我们通常称这种并行训练方法为数据并行。数据并行可以解决数据集过大无法在单机高效率训练的问题,也是工业生产中最常用的并行方法。
模型并行:通常指将模型单个算子计算分治到多个硬件设备上并发计算以达到计算单个算子计算速度的目的。我们一般会将单个算子的计算,利用模型并行的方式分配在配置相同的几个硬件上进行模型存储和计算,以保证计算步调一致。
流水线并行:一般是指将模型的不同算子,拆分到不同的硬件设备上进行计算,通过生产者-消费者的方式(流水线)完成不同设备之间的数据流通。深度学习中的跨设备交换数据场景很多,例如硬盘数据到内存,内存数据到显存,内存数据到网卡等,由于不同硬件之间处理数据的速度通常不一致,通常会采用流水线并行的方式进行训练效率最大化。
混合并行:在工业场景的实践中,分布式模型训练也会采用不同并行方式的组合,例如数据并行与模型并行结合,数据并行与流水线并行结合。
1.2 分布式训练中的模型同步方式
模型参数的同步是深度学习模型分布式训练中非常重要的一步,模型参数信息的同步方式、同步节奏等通常会直接影响模型的最终效果。下面我们会从模型参数同步的实现方法讲起,介绍两种常见的并行训练实现架构,即参数服务器架构、Collective架构。然后再介绍两种主流的模型参数同步方式,同步训练方式和异步训练方式。
1.2.1 模型同步的常见架构
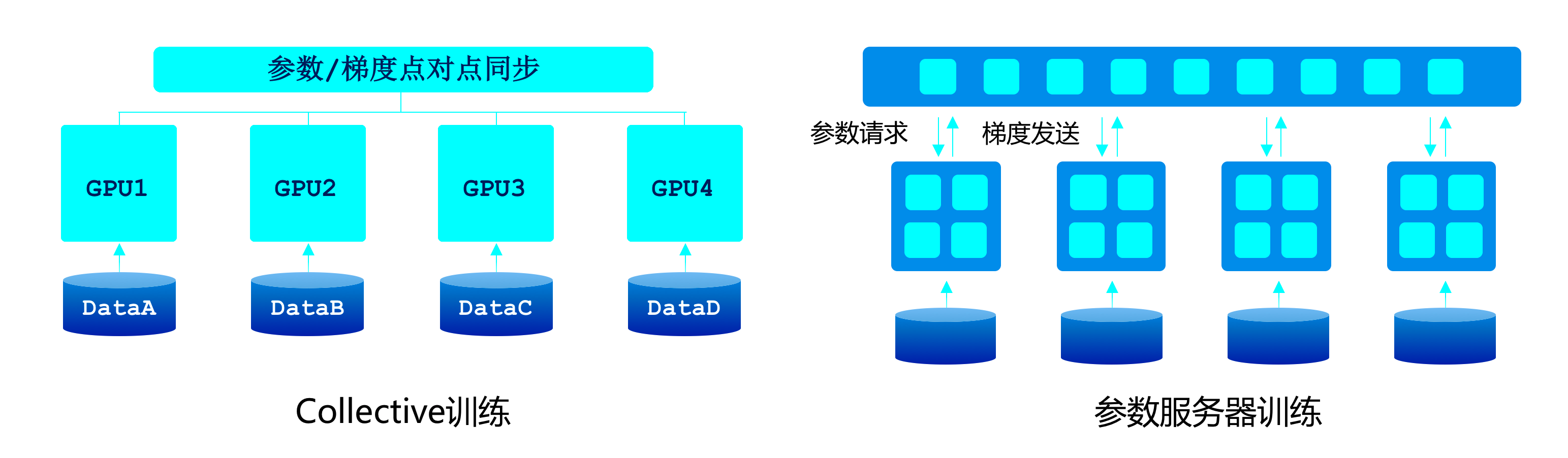
中心化的参数服务器架构,采用将模型参数进行中心化管理的方式实现模型参数的同步。每个硬件设备在执行每一步训练时都可以向参数服务器发出请求来获取全局最新的模型参数,并基于最新的模型参数计算当前数据的模型梯度。当单个设备基于最新的模型参数进行模型梯度的计算后,可以将模型梯度发回给参数服务器。经典的参数服务器架构,通常是将神经网络模型的前向、后向放在设备中执行,模型的更新部分放在参数服务器一端。参数服务器架构通常可以对模型参数的存储进行分布式保存,因此对于存储超大规模模型参数的训练场景十分友好,比如个性化推荐任务中需要保存的海量稀疏特征对应的模型参数,通常就只能采用参数服务器架构才能实现。
去中心化的Collective架构是近年来非常流行的分布式训练架构,没有所谓管理模型参数的中心节点,每个训练节点都相当于掌握当前最新全局信息的中心,因此Collective架构通常也叫做去中心训练架构。在Collective架构中,多节点的参数同步通常是采用多次设备之间的点对点通信完成的,比较经典的通信算法比如Baidu Ring All Reduce可以采用较少的点对点通信轮数完成全局节点的模型参数同步。去中心化的Collective架构通常在现代高性能AI芯片中使用较多,这种架构对计算芯片的算力和芯片之间的网络互联要求较高。高性能计算的AI芯片例如GPU,芯片之间的高速网络互联例如NVLINK, InfiniBand,都加快的Collective训练架构的发展。Collective训练架构对于计算密集的任务非常友好,我们熟知的经典模型,例如机器翻译中的Transformer,图像分类中的Resnet50,语音识别中的DeepSpeech2通常都是采用这种训练架构完成。
下图展示了Collective训练架构和参数服务器训练架构的示意图。
1.2.2 同步并行训练算法
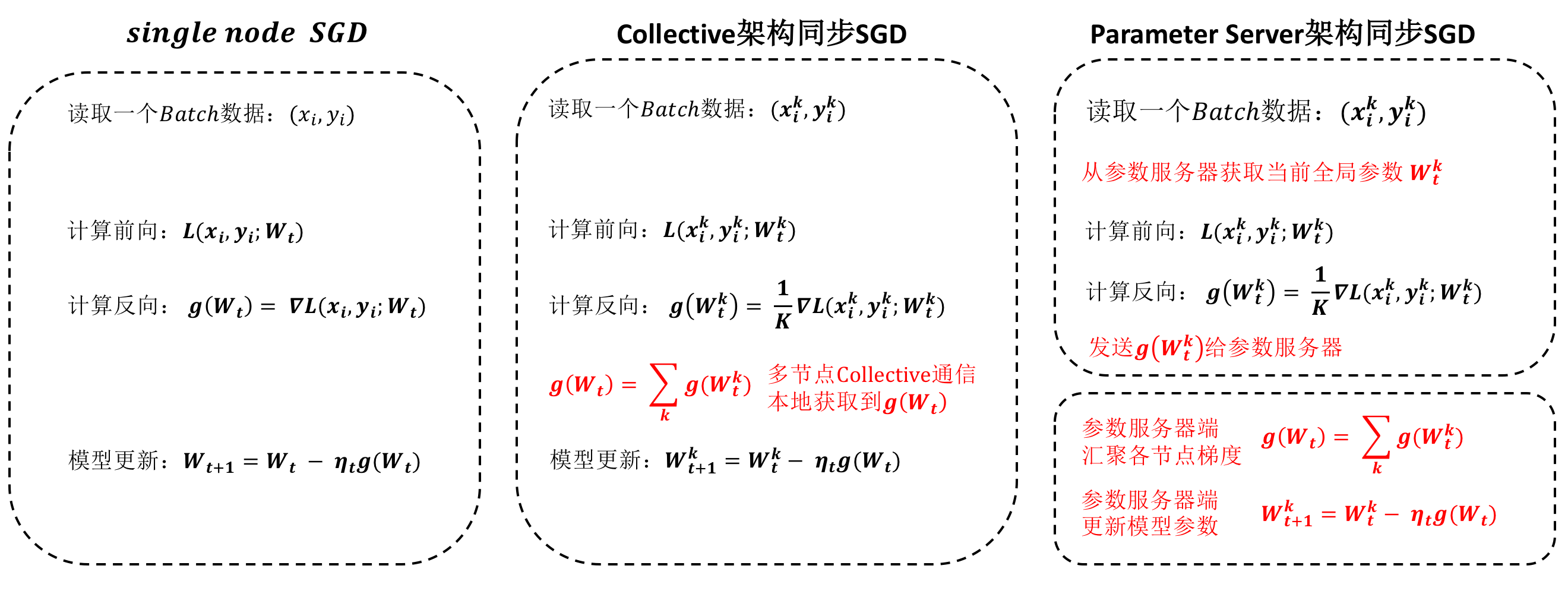
同步并行训练通常是指在每个计算节点在模型训练的每一步都进行一次模型参数的全局更新,更新方式可以采用参数服务器架构,也可以采用Collective架构。同步训练在训练的每一步都会进行参数同步,因此其行为本质上与单机训练一致,只是单步训练的总数据量会更大。值得一提的是,在参数服务器架构下的同步训练,优化算法的执行是发生在参数服务器一端,而在Collective架构下,通过对每一步所有样本产生的模型参数梯度进行全局同步后,每个设备执行优化算法即相当于优化全局的模型参数。下图展示了单机SGD算法,基于Collective架构的同步SGD算法,基于Parameter Server的异步SGD算法在计算步骤上的区别。可以看到Collective的架构发生通信的位置比较集中,并行是通过与正在训练的其他节点进行Collective通信完成,因此Collective架构是一种去中心化架构,每个节点只需要关注自己即可。参数服务器架构在获取参数,推送参数梯度等操作上都需要与参数服务器进行通信,参数服务器架构下的参数服务器端,要等待每个计算节点发送的梯度信息进行汇总后再进行模型参数的更新,因此是一种中心化的模式。
1.2.3 异步并行训练算法
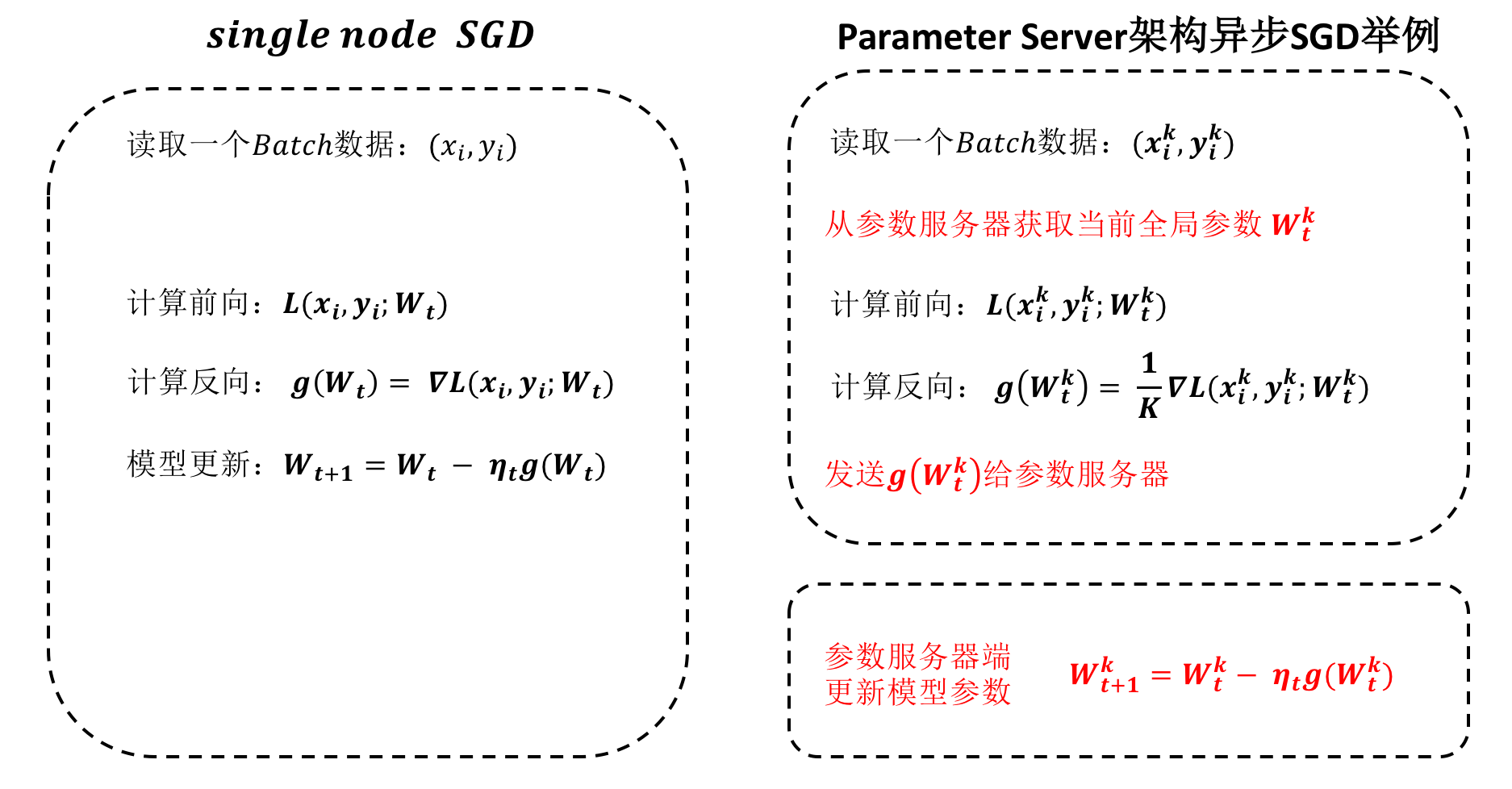
异步并行训练在参数服务器架构下采用较多,其核心思想就是让每个计算节点不用关心其他节点的计算步调,独自与参数服务器完成模型参数的更新。异步并行训练情况下,参数服务器端的模型参数更新也是异步进行,即不需要等待其他正在计算的节点的进度。异步并行训练下,各个计算节点的计算节奏不同,参数服务器更新模型参数的节奏也会不同,这种特性使得模型的收敛可能存在一定的问题,能够保证高效率收敛的异步并行算法是一个算法研究比较多的领域。下图是一个单机SGD与参数服务器架构下的异步SGD的计算步骤对比,可以看到参数服务器一端与同步SGD的区别在于不需要对各个节点的梯度进行汇聚而直接进行模型参数的更新。
2.飞桨中的分布式训练
飞桨主推的分布式训练场景包括拥有超大规模数据、超大规模稀疏特征的搜索、推荐场景(参数服务器架构为主),也有依赖于海量数据的自然语言处理、计算机视觉领域中的经典模型(Collective架构为主),这些场景也是能够覆盖百度大规模业务的场景。此外,针对一些领域前沿的研究和特殊的应用需求,飞桨也支持经典的模型并行和流水线并行。
2.1 飞桨分布式API
尽管分布式训练能够大大提升用户在大规模数据下的模型训练速度,如前面背景知识的描述可知普通用户想快速掌握并行训练的方法并不容易,将飞桨的单机训练程序转换成多机训练程序会给用户带来一定的使用成本。为了降低用户使用分布式训练的门槛,飞桨官方支持分布式训练高级API Fleet,作为分布式训练的统一入口API,用户可以在单机程序的基础上进行简单的几行代码修改即可实现多种类型的并行训练方式。Fleet API介绍飞桨数据并行方法在参数服务器架构和Collective架构下使用方法以及具体模型上的使用示例。
- 参数服务器训练(参数服务器架构的数据并行)
- 多机多卡训练(Collective架构的数据并行)
2.2 多机多卡训练简介
在工业实践中,许多较复杂的任务需要使用更强大的模型。强大模型加上海量的训练数据,经常导致模型训练耗时严重。比如在计算机视觉分类任务中,训练一个在ImageNet数据集上精度表现良好的模型,大概需要一周的时间,因为我们需要不断尝试各种优化的思路和方案。如果每次训练均要耗时1周,这会大大降低模型迭代的速度。在机器资源充沛的情况下,我们可以采用分布式训练,大部分模型的训练时间可压缩到小时级别。
飞桨有便利的数据并行训练方式,仅改动几行代码即可实现多GPU训练,接下来将讲述如何将一个单机程序通过简单的改造,变成多机多卡程序。
2.3 单机训练改多机多卡训练
将单机单卡训练模式转换为多机多卡训练模式是非常简单便捷的。在不修改原来的单机单卡程序的基础上,只需在该代码的指定位置上添加相应的函数,即可以实现多机多卡的转换。
首先来看一个简单的单机单卡程序。
# 下面是一个简单的单机单卡程序
import numpy as np
import paddle.fluid as fluid
import os
# 定义网络
def mlp(input_x, input_y, hid_dim=1280, label_dim=2):
fc_1 = fluid.layers.fc(input=input_x, size=hid_dim, act='tanh')
fc_2 = fluid.layers.fc(input=fc_1, size=hid_dim, act='tanh')
prediction = fluid.layers.fc(input=[fc_2], size=label_dim, act='softmax')
cost = fluid.layers.cross_entropy(input=prediction, label=input_y)
avg_cost = fluid.layers.mean(x=cost)
return avg_cost
# 生成数据集
def gen_data():
return {"x": np.random.random(size=(128, 32)).astype('float32'),
"y": np.random.randint(2, size=(128, 1)).astype('int64')}
input_x = fluid.layers.data(name="x", shape=[32], dtype='float32')
input_y = fluid.layers.data(name="y", shape=[1], dtype='int64')
# 定义损失
cost = mlp(input_x, input_y)
# 定义优化器
optimizer = fluid.optimizer.SGD(learning_rate=0.01)
optimizer.minimize(cost)
place = fluid.CPUPlace()
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
step = 100
# 进行训练
for i in range(step):
cost_val = exe.run(feed=gen_data(),
fetch_list=[cost.name])
print("step%d cost=%f" % (i, cost_val[0]))
# 模型保存
model_path = "./"
if os.path.exists(model_path):
fluid.io.save_persistables(exe, model_path)2.3.1 单机单卡改多机多卡操作流程
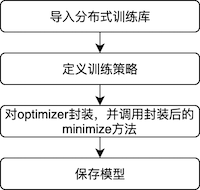
将单机单卡训练模式改成多机多卡训练模式的操作流程如下:
1、导入分布式训练库。
2、定义训练策略和集群环境定义。
3、对optimizer封装,并调用封装后的minimize方法。
4、保存模型。主要用于保存分布式训练的模型。
2.3.2 单机单卡改多机多卡操作步骤
将单机单卡程序改成多机多卡的具体处理步骤如下所述。
1、导入分布式训练库
这里主要引入分布式Fleet API。 Fleet的设计在易于使用和算法可扩展性之间进行了权衡,并且非常高效。首先,用户可以在十行代码中从本地机器桨式代码转换为分布式代码。其次,可以通过Fleet API设置分布式策略,从而轻松定义不同的算法。
from paddle.fluid.incubate.fleet.collective import fleet, DistributedStrategy
from paddle.fluid.incubate.fleet.base import role_maker2、定义训练策略和集群环境定义
这里需要定义分布式训练的相应策略,用于控制选取何种分布式方式以及相应的参数。详细的训练策略设定详见多机性能调优。 集群环境这里推荐使用PaddleCloudRoleMaker并使用paddle.distributed.launch启动程序;这样,PaddleCloudRoleMaker可自动获取训练集群相关信息。详情见下节如何运行多机多卡程序。
dist_strategy = DistributedStrategy()
role = role_maker.PaddleCloudRoleMaker(is_collective=True)
fleet.init(role)3、对optimizer封装,并调用封装后的minimize方法
这里主要将单机单卡的minimize方法转换为多机多卡的minimize方法。调用第二步封装后的optimizer的minimize方法。这里将optimizer转换为distributed_optimizer,其主要是对单机的optimizer增加了_transpile()的实现,对main_program进行转换(比如插入一些分布式的op等),主要是基于NCCL通信协议,实现梯度同步。
optimizer = fleet.distributed_optimizer(optimizer, strategy=dist_strategy)
optimizer.minimize(cost, fluid.default_startup_program())4、保存模型
使用fleet.save_persistables 或fleet.inference_model保存模型。
if os.path.exists(model_path):
fleet.save_persistables(exe, model_path)2.3.4 单机单卡改多机多卡代码示例
将单机单卡训练改成多机多卡训练的代码train_with_fleet.py示例如下。
# -*- coding: utf-8 -*-
import os
import numpy as np
import paddle.fluid as fluid
# 区别1: 导入分布式训练库
from paddle.fluid.incubate.fleet.collective import fleet, DistributedStrategy
from paddle.fluid.incubate.fleet.base import role_maker
# 定义网络
def mlp(input_x, input_y, hid_dim=1280, label_dim=2):
fc_1 = fluid.layers.fc(input=input_x, size=hid_dim, act='tanh')
fc_2 = fluid.layers.fc(input=fc_1, size=hid_dim, act='tanh')
prediction = fluid.layers.fc(input=[fc_2], size=label_dim, act='softmax')
cost = fluid.layers.cross_entropy(input=prediction, label=input_y)
avg_cost = fluid.layers.mean(x=cost)
return avg_cost
# 生成数据集
def gen_data():
return {"x": np.random.random(size=(128, 32)).astype('float32'),
"y": np.random.randint(2, size=(128, 1)).astype('int64')}
input_x = fluid.layers.data(name="x", shape=[32], dtype='float32')
input_y = fluid.layers.data(name="y", shape=[1], dtype='int64')
# 定义损失
cost = mlp(input_x, input_y)
optimizer = fluid.optimizer.SGD(learning_rate=0.01)
# 区别2: 定义训练策略和集群环境定义
dist_strategy = DistributedStrategy()
role = role_maker.PaddleCloudRoleMaker(is_collective=True)
fleet.init(role)
# 区别3: 对optimizer封装,并调用封装后的minimize方法
optimizer = fleet.distributed_optimizer(optimizer, strategy=DistributedStrategy())
optimizer.minimize(cost, fluid.default_startup_program())
train_prog = fleet.main_program
# 获得当前gpu的id号
gpu_id = int(os.getenv("FLAGS_selected_gpus", "0"))
print(gpu_id)
place = fluid.CUDAPlace(gpu_id)
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
step = 100
for i in range(step):
cost_val = exe.run(program=train_prog, feed=gen_data(), fetch_list=[cost.name])
print("step%d cost=%f" % (i, cost_val[0]))
# 区别4: 模型保存
model_path = "./"
if os.path.exists(model_path):
fleet.save_persistables(exe, model_path)运行结果会在mylog文件夹中得到8个log日志,分别对应8张卡的运行结果。

以workerlog.0日志为例,会打印出该卡的运行结果。
2.4 如何运行多机多卡程序
多机多卡程序的运行一般依赖于相应的集群,不同集群环境,相应的运行方法有所不同。下面主要针对用户自定义集群和PaddleCloud集群来说明程序的运行方式。
说明
更多API使用实例以及更复杂的模型,可以参考 https://github.com/PaddlePaddle/Fleet
方式一:使用用户自定义集群
注意:
对于其它集群,用户需要知道集群中所有节点的IP地址。
需要使用paddle.distributed.launch模块启动训练任务,可以通过如下命令查看paddle.distributed.launch模块的使用方法。
python -m paddle.distributed.launch --help
用户只需要配置以下参数:
--cluster_node_ips: 集群中所有节点的IP地址列表,以','分隔,例如:192.168.1.2,192.168.1.3。
--node_ip: 当前节点的IP地址。
--started_port:起始端口号,假设起始端口号为51340,并且节点上使用的GPU卡数为4,那么GPU卡上对应训练进程的端口号分别为51340、51341和51342。务必确保端口号可用。
--selected_gpus:使用的GPU卡。
我们假设用户使用的训练集群包含两个节点(机器),IP地址分别为192.168.1.2和192.168.1.3,并且每个节点上使用的GPU卡数为4,那么在两个节点的终端上分别运行如下任务。
192.168.1.2节点
python -m paddle.distributed.launch \
--cluster_node_ips=192.168.1.2,192.168.1.3 \
--node_ip=192.168.1.2 \
--started_port=6170 \
--selected_gpus=0,1,2,3 \
train_with_fleet.py
192.168.1.3节点
python -m paddle.distributed.launch \
--cluster_node_ips=192.168.1.2,192.168.1.3 \
--node_ip=192.168.1.3 \
--started_port=6170 \
--selected_gpus=0,1,2,3 \
train_with_fleet.py
注意:
对于想在单机多卡运行程序的用户,可以直接采用默认参数运行多卡程序。命令是:
config="--selected_gpus=0,1,2,3,4,5,6,7 --log_dir mylog"
python -m paddle.distributed.launch ${config} train.py方式二:使用PaddleCloud集群
针对百度内部用户,可以使用PaddleCloud集群运行多机多卡程序。关于如何使用PaddleCloud,请参考PaddleCloud官网:PaddleCloud官网。
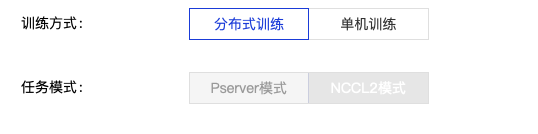
注意:
对于PaddleCloud分布式训练,训练方式需要选择“分布式训练”,任务模式需要选择“NCCL2模式”,如下图所示。
当采用客户端提交任务的方式时,需要通过以下命令行指定运行模式为“NCCL2模式”。
paddlecloud job \
... \
--is-standalone 0 \
--distribute-job-type NCCL2
需要将运行命令配置为如下命令:
start_cmd="python -m paddle.distributed.launch --use_paddlecloud --seletected_gpus='0,1,2,3,4,5,6,7' train_with_fleet.py --model=ResNet50 --data_dir=./ImageNet"
paddlecloud job \
--start-cmd "${start_cmd}" \
... \
--is-standalone 0 \
--distribute-job-type NCCL22.5 多机多卡模式下的性能调优
针对单机单卡改造成多机多卡第二步中的训练策略,使用默认的设置一般情况下可能无法达到最优的计算性能。
2.5.1 常见的性能调优设置
介绍一些提高分布式性能的调优设置。
设置环境变量
| 调节项 | 可选值 | 说明 |
|---|---|---|
| FLAGS_sync_nccl_allreduce | 0,1 | 是否同步AllReduce操作。1表示开启,每次调用等待AllReduce同步。 |
| FLAGS_fraction_of_gpu_memory_to_use | 0~1之间的float值 | 预先分配显存的占比。 |
| NCCL_IB_DISABLE | 0,1 | 是否启用RDMA多机通信。如果机器硬件支持,可以设置1,开启RDMA支持。 |
说明:
- FLAGS_sync_nccl_allreduce:配置 FLAGS_sync_nccl_allreduce=1,让每次allreduce操作都等待完成,可以提升性能,详细原因和分析可以参考:https://github.com/PaddlePaddle/Paddle/issues/15049
- FLAGS_fraction_of_gpu_memory_to_use:设置的范围是0.0~1.0。比如,配置FLAGS_fraction_of_gpu_memory_to_use=0.95 ,0.95是指95%的显存会预先分配。注意,设置成0.0会让每次显存分配都调用cudaMalloc,这样会极大的降低训练性能。
- NCCL_IB_DISABLE:在使用NCCL2模式训练时,会默认尝试开启RDMA通信。如果系统不支持,则会自动降级为使用TCP通信。可以通过打开环境变量NCCL_DEBUG=INFO查看NCCL是否选择了开启RDMA通信。如果需要强制使用TCP方式通信,可以设置 NCCL_IB_DISABLE=1 。
2.5.2 设置训练策略
训练参数设置表
| 选项 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| num_threads | int | 1 | CPU线程数 |
| nccl_comm_num | int | 1 | nccl通信器数量 |
| fuse_all_reduce_ops | bool | False | 多机多卡训练时,将AllReduce操作进行融合 |
| use_hierarchical_allreduce | bool | False | 分级式reduce |
| num_iteration_per_drop_scope | int | 1 | scope drop频率,设置每隔几个batch的迭代之后执行一次清理scope |
| fetch_frequency | int | 1 | fetch的刷新频率 |
说明:
- 设置合适的CPU线程数num_threads和nccl通信器数量 nccl_comm_num :飞桨使用“线程池”模型调度并执行OP,OP在启动GPU计算之前,通常需要CPU的协助,然而如果OP本身占用时间很小,“线程池”模型下又会带来额外的调度开销。使用多进程模式时,如果神经网络的计算图节点间有较高的并发度,即使每个进程只在一个GPU上运行,使用多个线程可以更大限度的提升GPU利用率。NCCL通信器数量 nccl_comm_num 可以加快GPU之间的通信效率。
- AllReduce融合fuse_all_reduce_ops:默认情况下会将同一layer中参数的梯度的AllReduce操作合并成一个。比如,对于fluid.layers.fc中有Weight和Bias两个参数,打开该选项之后,原本需要两次AllReduce操作,现在只用一次AllReduce 操作。此外,为支持更大粒度的参数梯度融合,Paddle提供了 FLAGS_fuse_parameter_memory_size 和 FLAGS_fuse_parameter_groups_size 两个环境变量选项。用户可以指定融合AllReduce操作之后,每个AllReduce操作的梯度字节数。比如,希望每次AllReduce调用传输16MB的梯度,export FLAGS_fuse_parameter_memory_size=16 ,经验值为总通信量的十分之一。可以指定每次AllReduce操作的最大层数,即到达该层数就进行AllReduce,如指定50层 export FLAGS_fuse_parameter_groups_size=50 。注意:目前不支持sparse参数梯度。
- 使用分级式reduce use_hierarchical_allreduce:对于多机模式,针对小数据量的通信,Ring AllReduce通信效率低,采用Hierarchical AllReduce可以解决该问题。
- 降低scope drop频率 num_iteration_per_drop_scope 和fetch频率 fetch_frequency:减少scope drop和fetch频率,可以减少频繁的变量内存申请、释放和拷贝,从而提升性能。
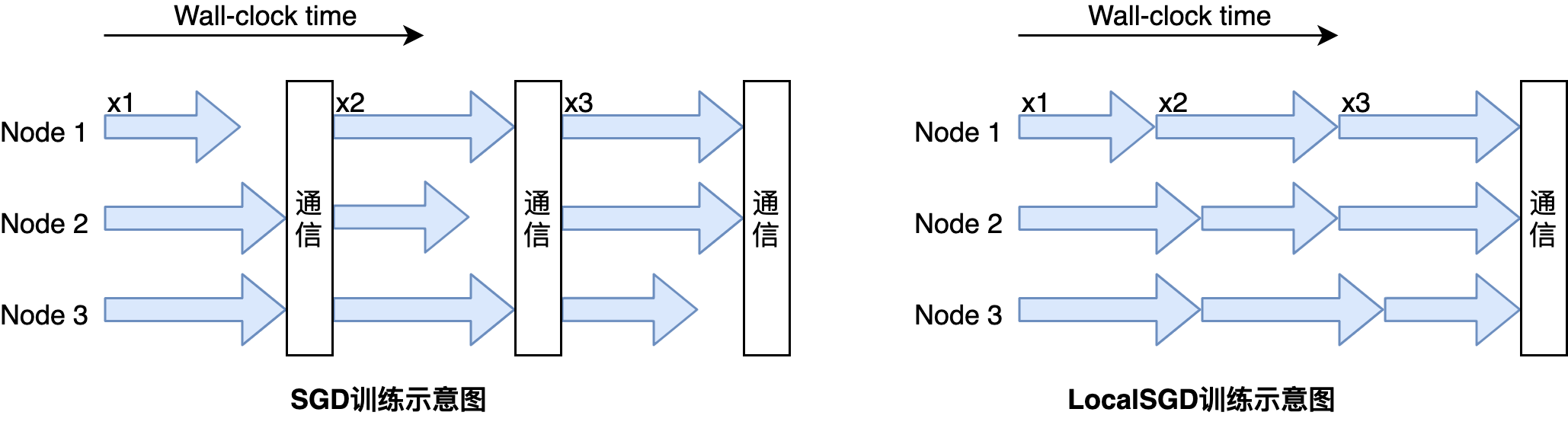
2.5.3 设置训练方式
GPU多机多卡同步训练过程中存在慢trainer现象,即每步中训练快的trainer的同步通信需要等待训练慢的trainer。 由于每步中慢trainer的rank具有随机性, 因此我们使用局部异步训练的方式——LocalSGD, 通过多步异步训练(无通信阻塞)实现慢trainer时间均摊, 从而提升同步训练性能,如下图所示:
Local SGD训练方式主要有三个参数,分别是:
| 选项 | 类型 | 可选值 | 说明 |
|---|---|---|---|
| use_local_sgd | bool | False/True | 是否开启Local SGD,默认不开启 |
| local_sgd_is_warm_steps | int | 大于0 | 训练多少轮之后才使用Local SGD方式训练 |
| local_sgd_steps | int | 大于0 | Local SGD的步长 |
说明
- Local SGD的warmup步长local_sgd_is_warm_steps影响最终模型的泛化能力,一般需要等到模型参数稳定之后在进行Local SGD训练,经验值可以将学习率第一次下降时的epoch作为warmup步长,之后再进行Local SGD训练。
- Local SGD步长local_sgd_steps ,一般该值越大,通信次数越少,训练速度越快,但随之而来的时模型精度下降。经验值设置为2或者4。具体的Local SGD的训练代码可以参考: https://github.com/PaddlePaddle/Fleet/tree/develop/examples/local_sgd/resnet
- Local SGD训练方式在Imagenet数据集,ResetNet50网络上,4机32卡,有8%~10%的速度提升。
2.5.4 性能调优代码示例
使用相应的分布式策略之后的多机多卡的代码示例如下。
# -*- coding: utf-8 -*-
import os
import numpy as np
import paddle.fluid as fluid
from paddle.fluid.incubate.fleet.collective import fleet, DistributedStrategy
from paddle.fluid.incubate.fleet.base import role_maker
# 调优策略的部分参数设置
# 建议多机设置为2,单机设置为1
nccl_comm_num = 2
# 建议多机设置为nccl_comm_num+1,单机设置为1
num_threads = 3
# scope drop频率
num_iteration_per_drop_scope = 30
#AllReduce是否融合
fuse_all_reduce_ops = True
# 刷新频率
fetch_frequency = 2
def mlp(input_x, input_y, hid_dim=1280, label_dim=2):
fc_1 = fluid.layers.fc(input=input_x, size=hid_dim, act='tanh')
fc_2 = fluid.layers.fc(input=fc_1, size=hid_dim, act='tanh')
prediction = fluid.layers.fc(input=[fc_2], size=label_dim, act='softmax')
cost = fluid.layers.cross_entropy(input=prediction, label=input_y)
avg_cost = fluid.layers.mean(x=cost)
return avg_cost
def gen_data():
return {"x": np.random.random(size=(128, 32)).astype('float32'),
"y": np.random.randint(2, size=(128, 1)).astype('int64')}
input_x = fluid.layers.data(name="x", shape=[32], dtype='float32')
input_y = fluid.layers.data(name="y", shape=[1], dtype='int64')
cost = mlp(input_x, input_y)
optimizer = fluid.optimizer.SGD(learning_rate=0.01)
role = role_maker.PaddleCloudRoleMaker(is_collective=True)
fleet.init(role)
dist_strategy = DistributedStrategy()
dist_strategy.nccl_comm_num = nccl_comm_num
exec_strategy = fluid.ExecutionStrategy()
exec_strategy.num_threads = num_threads
exec_strategy.num_iteration_per_drop_scope = num_iteration_per_drop_scope
dist_strategy.exec_strategy = exec_strategy
dist_strategy.fuse_all_reduce_ops = fuse_all_reduce_ops
optimizer = fleet.distributed_optimizer(optimizer, strategy=dist_strategy)
optimizer.minimize(cost, fluid.default_startup_program())
train_prog = fleet.main_program
gpu_id = int(os.getenv("FLAGS_selected_gpus", "0"))
place = fluid.CUDAPlace(gpu_id)
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
step = 100
for i in range(step):
# fetch频率
if i % fetch_frequency == 0:
cost_val = exe.run(program=train_prog, feed=gen_data(), fetch_list=[cost.name])
print("step%d cost=%f" % (i, cost_val[0]))
else:
cost_val = exe.run(program=train_prog, feed=gen_data())【一】分布式训练---单机多卡多机多卡(飞桨paddle1.8)的更多相关文章
- TensorFlow分布式部署【多机多卡】
让TensorFlow们飞一会儿 前一篇文章说过了TensorFlow单机多卡情况下的分布式部署,毕竟,一台机器势单力薄,想叫兄弟们一起来算神经网络怎么办?我们这次来介绍一下多机多卡的分布式部署. 其 ...
- Pytorch使用分布式训练,单机多卡
pytorch的并行分为模型并行.数据并行 左侧模型并行:是网络太大,一张卡存不了,那么拆分,然后进行模型并行训练. 右侧数据并行:多个显卡同时采用数据训练网络的副本. 一.模型并行 二.数据并行 数 ...
- 『TensorFlow』分布式训练_其三_多机分布式
本节中的代码大量使用『TensorFlow』分布式训练_其一_逻辑梳理中介绍的概念,是成熟的多机分布式训练样例 一.基本概念 Cluster.Job.task概念:三者可以简单的看成是层次关系,tas ...
- windows下使用pytorch进行单机多卡分布式训练
现在有四张卡,但是部署在windows10系统上,想尝试下在windows上使用单机多卡进行分布式训练,网上找了一圈硬是没找到相关的文章.以下是踩坑过程. 首先,pytorch的版本必须是大于1.7, ...
- 『TensorFlow』分布式训练_其一_逻辑梳理
1,PS-worker架构 将模型维护和训练计算解耦合,将模型训练分为两个作业(job): 模型相关作业,模型参数存储.分发.汇总.更新,有由PS执行 训练相关作业,包含推理计算.梯度计算(正向/反向 ...
- [源码解析] 深度学习分布式训练框架 horovod (3) --- Horovodrun背后做了什么
[源码解析] 深度学习分布式训练框架 horovod (3) --- Horovodrun背后做了什么 目录 [源码解析] 深度学习分布式训练框架 horovod (3) --- Horovodrun ...
- [源码解析] 深度学习分布式训练框架 horovod (12) --- 弹性训练总体架构
[源码解析] 深度学习分布式训练框架 horovod (12) --- 弹性训练总体架构 目录 [源码解析] 深度学习分布式训练框架 horovod (12) --- 弹性训练总体架构 0x00 摘要 ...
- [源码解析] 深度学习分布式训练框架 horovod (16) --- 弹性训练之Worker生命周期
[源码解析] 深度学习分布式训练框架 horovod (16) --- 弹性训练之Worker生命周期 目录 [源码解析] 深度学习分布式训练框架 horovod (16) --- 弹性训练之Work ...
- [源码解析] 深度学习分布式训练框架 horovod (18) --- kubeflow tf-operator
[源码解析] 深度学习分布式训练框架 horovod (18) --- kubeflow tf-operator 目录 [源码解析] 深度学习分布式训练框架 horovod (18) --- kube ...
- [源码解析] 模型并行分布式训练Megatron (2) --- 整体架构
[源码解析] 模型并行分布式训练Megatron (2) --- 整体架构 目录 [源码解析] 模型并行分布式训练Megatron (2) --- 整体架构 0x00 摘要 0x01 启动 1.1 分 ...
随机推荐
- docker中安装的mysql无法远程连接问题解决
背景: 在ubuntu1804的docker中安装了mysql,版本是5.7.34.因为有复杂的数据要插入到数据库中,所以从宿主机通过pycharm和DBeaver连接,但是一直报错: Can not ...
- Android RxJava 异常时堆栈信息显示不全(不准确),解决方案都在这里了
现象 大家好,我是徐公,今天为大家带来的是 RxJava 的一个血案,一行代码 return null 引发的. 前阵子,组内的同事反馈说 RxJava 在 debug 包 crash 了,捕获到的异 ...
- AtCoder Beginner Contest 188 题解
AtCoder Beginner Contest 188 A,B很简单就不多说 C - ABC Tournament 找出前一半的最大值和后一半的最大值,二者中较小的那一个对应的序号就是最后的答案. ...
- Codeforces Round #689 (Div. 2, based on Zed Code Competition) 个人题解
1461A. String Generation void solve() { int n, k; cin >> n >> k; for (int i = 1; i <= ...
- Deployment 和 StatefulSets 概述
这篇概述是看文章提到的一段话 xxx is not targeted to be horizontally scalable 引发的,遂整理记录在这里. 起因是有两个应用,一个是无状态的,可以 hor ...
- idea相关配置及插件安装
对idea相关的配置及好用的插件进行总结下. 一.idea 破解码及配置:https://www.jb51.net/softs/672190.html 二.idea插件: 1.findBugs-ide ...
- DFT Architecture
Design For Test 在实际生产过程中产生的physical defect是导致芯片功能出错的根本原因 如何根据结构产生测试向量呢?主要考虑physical defect physical ...
- 06-逻辑仿真工具VCS-Debug
逻辑仿真工具VCS verdi只进行debug进行使用,不进行编译,只进行产生波形之后的debug 仿真速度和代码质量有关系,选项也会影响仿真速度,行为级>RTL>门级 信号的可见性和可追 ...
- P5728 【深基5.例5】旗鼓相当的对手
1.题目介绍 2.题解 2.1 二维数组 思路 主要熟悉vector创建二维数组的方法 vector<vector> ans(N,vector(3)); 这里第一个元素表明数组大小,第二个 ...
- IDEA控制台输出中文乱码
1.问题 如下图,我使用的文件编码格式为UFT-8,这里会出现中文乱码的问题. 且我并不方便直接修改全局文件编码格式,有可能会造成未知错误. 2.解决 参考链接:IDEA 控制台中文乱码 4 种解决方 ...