Spark源码分析 之 Driver和Excutor是怎么跑起来的?(2.2.0版本)
今天抽空回顾了一下Spark相关的源码,本来想要了解一下Block的管理机制,但是看着看着就回到了SparkContext的创建与使用。正好之前没有正式的整理过这部分的内容,这次就顺带着回顾一下。
更多内容参考:我的大数据之路
Spark作为目前最流行的大数据计算框架,已经发展了几个年头了。版本也从我刚接触的1.6升级到了2.2.1。由于目前工作使用的是2.2.0,所以这次的分析也就从2.2.0版本入手了。
涉及的内容主要有:
- Standalone模式中的Master与Worker
- client、driver、excutor的关系
下面就按照顺序依次介绍一下。
Master与Worker
在最开始编程的时候,很少会涉及分布式,因为数据量也不大。后来随着硬件的发展cpu的瓶颈,开始流行多线程编程,基于多线程来加快处理速度;再后来,衍生出了网格计算、CPU与GPU的异构并行计算以及当时流行的mapreduce分布式计算。但是mapreduce由于存储以及计算流程的限制,spark开始流行起来。Spark凭借内存计算、强大的DAG回溯能力,快速的占领并行计算的风口。
那么并行计算肯定是需要分布式集群的,常见的集群管理方式,有Master-Slave模式、P2P模式等等。
比如Mysql的主从复制,就是Master-Slave模式;Elasticsearch的分片管理就是P2P模式。在Spark中有不同的部署方式,但是计算的模式都是Master-Slave模式,只不过Slave换了名字叫做worker而已。集群的部署模式如下所示:
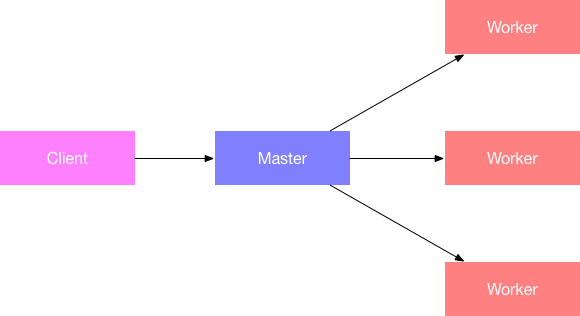
流程就是用户以client的身份向master提交任务,master去worker上面创建执行任务的载体(driver和excutor)。
client、driver、excutor的关系
Master和Worker是服务器的部署角色,程序从执行上,则分成了client、driver、excutor三种角色。按照模式的不同,client和driver可能是同一个。以2.2.0版本的standalone模式来说,他们三个是独立的角色。client用于提交程序,初始化一些环境变量;driver用于生成task并追踪管理task的运行;excutor负责最终task的执行。
源码探索
总的流程可以总结为下面的一张图:
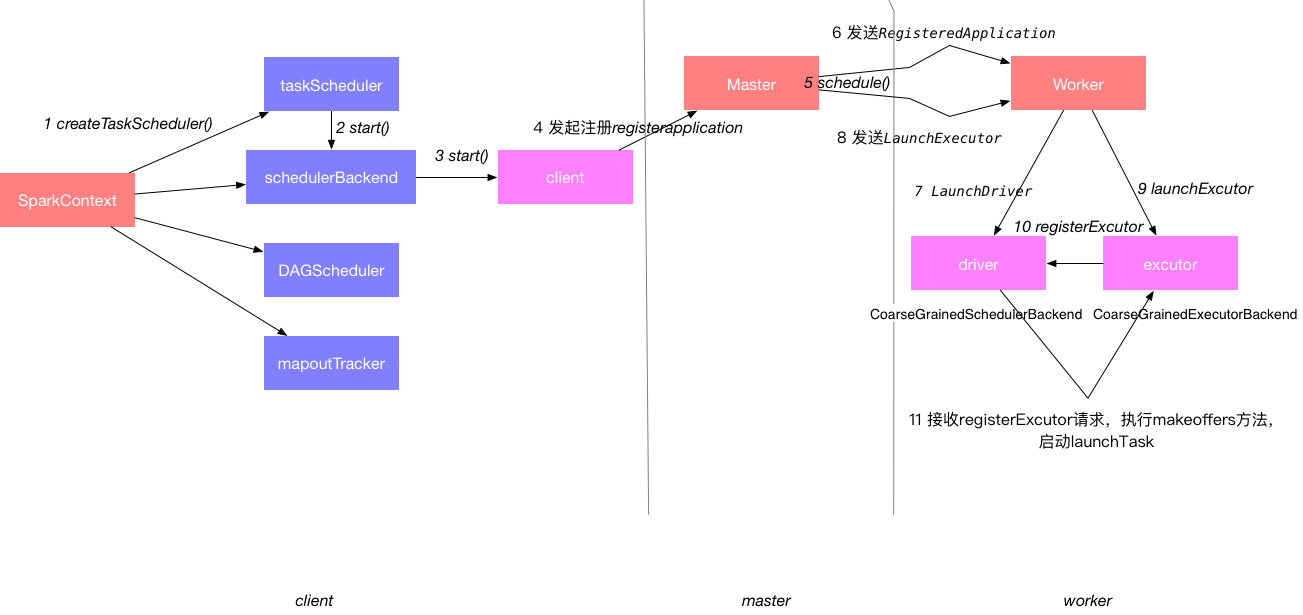
通过查看源码,来看一下
1 SparkContext创建调度器
在创建SparkContext的时候会创建几个核心的模块:
- DAGScheduler 面向job的调度器
- TaskScheduler 不同的集群模式,有不同的实现方式,如standalone下的taskschedulerImpl
- SchedulerBackend 不同的集群模式下,有不同的实现方式,如standalone下的StandaloneSchedulerBackend.负责向master发起注册
// 创建并启动调度器
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
_schedulerBackend = sched
_taskScheduler = ts
_dagScheduler = new DAGScheduler(this)
...
// 启动调度器
_taskScheduler.start()
在createTaskSchduler中,根据master的不同,选择不同的实现方式,主要是在backend的实现上有差异:
master match {
case "local" =>
...
case LOCAL_N_REGEX(threads) =>
...
case LOCAL_N_FAILURES_REGEX(threads, maxFailures) =>
...
case SPARK_REGEX(sparkUrl) =>
// 创建调度器
val scheduler = new TaskSchedulerImpl(sc)
val masterUrls = sparkUrl.split(",").map("spark://" + _)
// 创建backend
val backend = new StandaloneSchedulerBackend(scheduler, sc, masterUrls)
// 把backend注入到schduler中
scheduler.initialize(backend)
(backend, scheduler)
case LOCAL_CLUSTER_REGEX(numSlaves, coresPerSlave, memoryPerSlave) =>
...
case masterUrl =>
...
}
我们这里只看一下standalone模式的创建,就是创建了TaskSchedulerImpl和StandaloneSchedulerBackend的对象,另外初始化了调度器,根据配置选择调度模式,默认是FIFO:
def initialize(backend: SchedulerBackend) {
this.backend = backend
schedulableBuilder = {
schedulingMode match {
case SchedulingMode.FIFO =>
new FIFOSchedulableBuilder(rootPool)
case SchedulingMode.FAIR =>
new FairSchedulableBuilder(rootPool, conf)
case _ =>
throw new IllegalArgumentException(s"Unsupported $SCHEDULER_MODE_PROPERTY: " +
s"$schedulingMode")
}
}
schedulableBuilder.buildPools()
}
2 TaskSchedulerImpl执行start方法
其实是执行了backend的start()方法
override def start() {
backend.start()
...
}
3 StandaloneSchedulerBackend执行start方法
这部分代码比较多,可以简化的看:
- 封装command对象
- 封装appDesc对象
- 创建StandaloneAppClient对象
- 执行start()方法
其中command中包含的那个类,就是excutor的实现类。
override def start() {
//初始化参数
...
val command = Command("org.apache.spark.executor.CoarseGrainedExecutorBackend",
args, sc.executorEnvs, classPathEntries ++ testingClassPath, libraryPathEntries, javaOpts)
...
val appDesc = ApplicationDescription(sc.appName, maxCores, sc.executorMemory, command,
webUrl, sc.eventLogDir, sc.eventLogCodec, coresPerExecutor, initialExecutorLimit)
// 注意前面创建了一大堆的配置对象,主要就是那个class等信息
client = new StandaloneAppClient(sc.env.rpcEnv, masters, appDesc, this, conf)
client.start()
...
}
4 发起注册
核心的代码在StanaloneAppClient中,并在start()方法中启动了一个rpc的服务——ClientEndpoint
override def onStart(): Unit = {
try {
registerWithMaster(1)//发起注册
} catch {
...
}
}
registerWithMaster采用了异步发送请求连接master,只要有一个注册成功,其他的都会cancel。这里有时间可以做个小hello world玩玩看。
private def registerWithMaster(nthRetry: Int) {
registerMasterFutures.set(tryRegisterAllMasters())
registrationRetryTimer.set(registrationRetryThread.schedule(new Runnable {
override def run(): Unit = {
if (registered.get) {
registerMasterFutures.get.foreach(_.cancel(true))
registerMasterThreadPool.shutdownNow()
} else if (nthRetry >= REGISTRATION_RETRIES) {
markDead("All masters are unresponsive! Giving up.")
} else {
registerMasterFutures.get.foreach(_.cancel(true))
registerWithMaster(nthRetry + 1)
}
}
}, REGISTRATION_TIMEOUT_SECONDS, TimeUnit.SECONDS))
}
//发起注册
private def tryRegisterAllMasters(): Array[JFuture[_]] = {
...
masterRef.send(RegisterApplication(appDescription, self))
...
}
5 Master接收到请求执行schedule方法
Master是一个常驻的进程,时刻监听别人发过来的消息。刚才client发送了一个RegisterApplication消息,忽略前面创建app的内容,直接执行了schedule方法:
case RegisterApplication(description, driver) =>
// TODO Prevent repeated registrations from some driver
if (state == RecoveryState.STANDBY) {
// ignore, don't send response
} else {
...
schedule()
}
6 Master发送launchDriver
发送lanunchDriver请求
private def schedule(): Unit = {
...
for (driver <- waitingDrivers.toList) { // iterate over a copy of waitingDrivers
...
while (numWorkersVisited < numWorkersAlive && !launched) {
...
if (worker.memoryFree >= driver.desc.mem && worker.coresFree >= driver.desc.cores) {
launchDriver(worker, driver)
...
}
...
}
}
startExecutorsOnWorkers()
}
//向worker发送launchDriver请求
private def launchDriver(worker: WorkerInfo, driver: DriverInfo) {
...
worker.endpoint.send(LaunchDriver(driver.id, driver.desc))
...
}
7 Worker创建DriverRunner
case LaunchDriver(driverId, driverDesc) =>
logInfo(s"Asked to launch driver $driverId")
val driver = new DriverRunner(
conf,
driverId,
workDir,
sparkHome,
driverDesc.copy(command = Worker.maybeUpdateSSLSettings(driverDesc.command, conf)),
self,
workerUri,
securityMgr)
drivers(driverId) = driver
driver.start()
coresUsed += driverDesc.cores
memoryUsed += driverDesc.mem
8 Master发送launchExcutor
第6步中最后有一个startExecutorsOnWorkers方法。
private def startExecutorsOnWorkers(): Unit = {
...
for (app <- waitingApps if app.coresLeft > 0) {
...
for (pos <- 0 until usableWorkers.length if assignedCores(pos) > 0) {
allocateWorkerResourceToExecutors(
app, assignedCores(pos), coresPerExecutor, usableWorkers(pos))
}
}
}
private def allocateWorkerResourceToExecutors(
app: ApplicationInfo,
assignedCores: Int,
coresPerExecutor: Option[Int],
worker: WorkerInfo): Unit = {
...
for (i <- 1 to numExecutors) {
...
launchExecutor(worker, exec)
...
}
}
private def launchExecutor(worker: WorkerInfo, exec: ExecutorDesc): Unit = {
...
worker.endpoint.send(LaunchExecutor(masterUrl,
exec.application.id, exec.id, exec.application.desc, exec.cores, exec.memory))
...
}
9 Worker创建ExcutorRunner
case LaunchExecutor(masterUrl, appId, execId, appDesc, cores_, memory_) =>
if (masterUrl != activeMasterUrl) {
...
} else {
try {
...
val manager = new ExecutorRunner(
appId,
execId,
appDesc.copy(command = Worker.maybeUpdateSSLSettings(appDesc.command, conf)),
cores_,
memory_,
self,
workerId,
host,
webUi.boundPort,
publicAddress,
sparkHome,
executorDir,
workerUri,
conf,
appLocalDirs, ExecutorState.RUNNING)
...
} catch {
...
}
}
至此,Driver和Excutor就启动起来了.....
之后代码是怎么运行的,就且听下回分解把!
参考
- SparkContext http://www.cnblogs.com/jcchoiling/p/6427406.html
- spark worker解密:http://www.cnblogs.com/jcchoiling/p/6433196.html
- 2.2.0源码
- 《Spark内核机制及性能调优》· 王家林
Spark源码分析 之 Driver和Excutor是怎么跑起来的?(2.2.0版本)的更多相关文章
- spark 源码分析之十八 -- Spark存储体系剖析
本篇文章主要剖析BlockManager相关的类以及总结Spark底层存储体系. 总述 先看 BlockManager相关类之间的关系如下: 我们从NettyRpcEnv 开始,做一下简单说明. Ne ...
- spark源码分析以及优化
第一章.spark源码分析之RDD四种依赖关系 一.RDD四种依赖关系 RDD四种依赖关系,分别是 ShuffleDependency.PrunDependency.RangeDependency和O ...
- Spark源码分析(三)-TaskScheduler创建
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3879151.html 在SparkContext创建过程中会调用createTaskScheduler函 ...
- 【转】Spark源码分析之-deploy模块
原文地址:http://jerryshao.me/architecture/2013/04/30/Spark%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%E4%B9%8B- ...
- Spark源码分析:多种部署方式之间的区别与联系(转)
原文链接:Spark源码分析:多种部署方式之间的区别与联系(1) 从官方的文档我们可以知道,Spark的部署方式有很多种:local.Standalone.Mesos.YARN.....不同部署方式的 ...
- Spark 源码分析 -- task实际执行过程
Spark源码分析 – SparkContext 中的例子, 只分析到sc.runJob 那么最终是怎么执行的? 通过DAGScheduler切分成Stage, 封装成taskset, 提交给Task ...
- Spark源码分析 – BlockManager
参考, Spark源码分析之-Storage模块 对于storage, 为何Spark需要storage模块?为了cache RDD Spark的特点就是可以将RDD cache在memory或dis ...
- Spark源码分析 – SchedulerBackend
SchedulerBackend, 两个任务, 申请资源和task执行和管理 对于SparkDeploySchedulerBackend, 基于actor模式, 主要就是启动和管理两个actor De ...
- Spark源码分析 – Deploy
参考, Spark源码分析之-deploy模块 Client Client在SparkDeploySchedulerBackend被start的时候, 被创建, 代表一个application和s ...
随机推荐
- hdoj 1285 确定比赛名次 【拓扑排序】
确定比赛名次 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total Sub ...
- Javascript 进阶 面向对象编程 继承的一个样例
Javascript的难点就是面向对象编程,上一篇介绍了Javascript的两种继承方式:Javascript 进阶 继承.这篇使用一个样例来展示js怎样面向对象编程.以及怎样基于类实现继承. 1. ...
- SAP ABAP编程 Table Control动态隐藏列
在SAP DIALOG设计中,有时候须要动态的隐藏某些列,以下是方法. ***数据定义 CONTROLS: table_control TYPE TABLEVIEW USING SCREEN 0100 ...
- One-Based Arithmetic
One-Based Arithmetic time limit per test 0.5 seconds memory limit per test 256 megabytes input stand ...
- 有限等距性质RIP
参考博客:http://blog.csdn.net/jbb0523/article/details/44565647 压缩感知测量矩阵之有限等距性质(Restricted Isometry Prope ...
- Android(Java) 字符串的常用操作,获取指定字符出现的次数,根据指定字符截取字符串
/*这是第100000份数据,要截取出100000*/ String s="这是第100000份数据"; String s1 = s.substring(s.indexOf(&qu ...
- SoapUI模拟soap接口返回不同响应(通过groovy脚本)
一.创建soap项目,输入wsdl文件,然后生成SOAP Mock Service,再生成测试用例,然后新建新的响应 WSDL文件:MathUtil.wsdl <?xml version=&qu ...
- 查看当前支持的shell,echo -e相关转义符,一个简单shell脚本,dos2unix命令把windows格式转为Linux格式
/etc/shells [root@localhost ~]# more /etc/shells /bin/sh /bin/bash /sbin/nologin /usr/bin/sh /usr/bi ...
- 环链表相关的题目和算法[LeetCode]
这篇文章讨论一下与链表的环相关的题目,我目前遇到的一共有3种题目. 1.判断一个链表是否有环(LeetCode相关题目:https://leetcode.com/problems/linked-lis ...
- ImportError: No module named 'request'
使用系统自带的Python 2.7执行python时出现ImportError: No module named 'request'这样的报错,这是系统自带的Python没有requests库,这里可 ...