【Spark2.0源码学习】-2.一切从脚本说起
- %SPARK_HOME%/sbin/start-master.sh
- %SPARK_HOME%/sbin/start-slaves.sh
- %SPARK_HOME%/sbin/start-all.sh
- %SPARK_HOME%/bin/spark-submit
| spark-config.sh | 初始化环境变量 SPARK_CONF_DIR, PYTHONPATH |
| bin/load-spark-env.sh |
初始化环境变量SPARK_SCALA_VERSION,
调用%SPARK_HOME%/conf/spark-env.sh加载用户自定义环境变量
|
| conf/spark-env.sh | 用户自定义配置 |
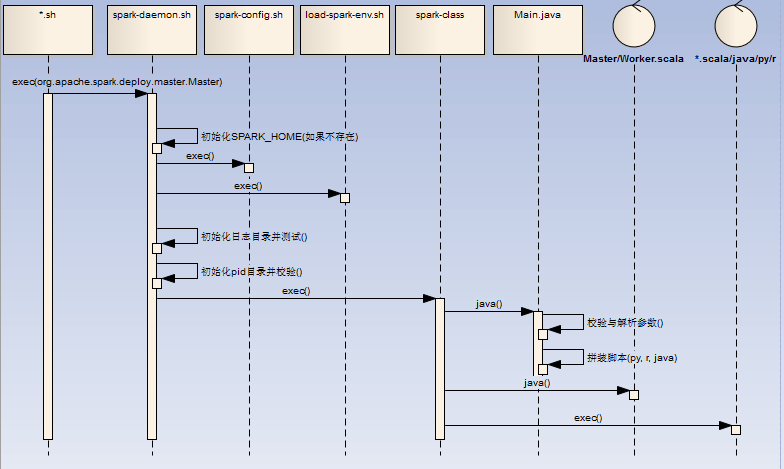
- 初始化 SPRK_HOME,SPARK_CONF_DIR,SPARK_IDENT_STRING,SPARK_LOG_DIR环境变量(如果不存在)
- 初始化日志并测试日志文件夹读写权限,初始化PID目录并校验PID信息
- 调用/bin/spark-class脚本,/bin/spark-class见下
- master调用举例:bin/spark-class --class org.apache.spark.deploy.master.Master --host $SPARK_MASTER_HOST --port $SPARK_MASTER_PORT --webui-port $SPARK_MASTER_WEBUI_PORT $ORIGINAL_ARGS
- 初始化 RUNNER(java),SPARK_JARS_DIR(%SPARK_HOME%/jars),LAUNCH_CLASSPATH信息
- 调用( "$RUNNER" -Xmx128m -cp "$LAUNCH_CLASSPATH" org.apache.spark.launcher.Main "$@")获取最终执行的shell语句
- 执行最终的shell语句(比如:/opt/jdk1.7.0_79/bin/java -cp /opt/spark-2.1.0/conf/:/opt/spark-2.1.0/jars/*:/opt/hadoop-2.6.4/etc/hadoop/ -Xmx1g -XX:MaxPermSize=256m org.apache.spark.deploy.master.Master --host zqh --port 7077 --webui-port 8080),如果是Client,那么可能为r,或者python脚本
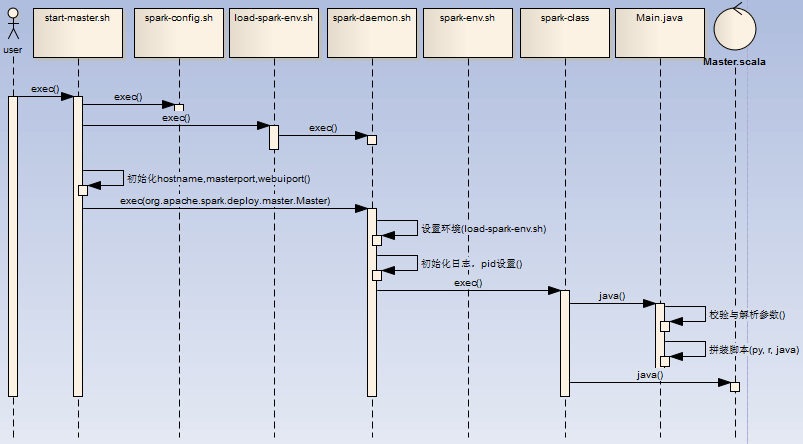
- 用户执行start-master.sh脚本,初始化环境变量SPARK_HOME (如果PATH不存在SPARK_HOME,初始化脚本的上级目录为SPARK_HOME),调用spark-config.sh,调用load-spark-env.sh
- 如果环境变量SPARK_MASTER_HOST, SPARK_MASTER_PORT,SPARK_MASTER_WEBUI_PORT不存在,进行初始化7077,hostname -f,8080
- 调用spark-daemon.sh脚本启动master进程(spark-daemon.sh start org.apache.spark.deploy.master.Master 1 --host $SPARK_MASTER_HOST --port $SPARK_MASTER_PORT --webui-port $SPARK_MASTER_WEBUI_PORT $ORIGINAL_ARGS)
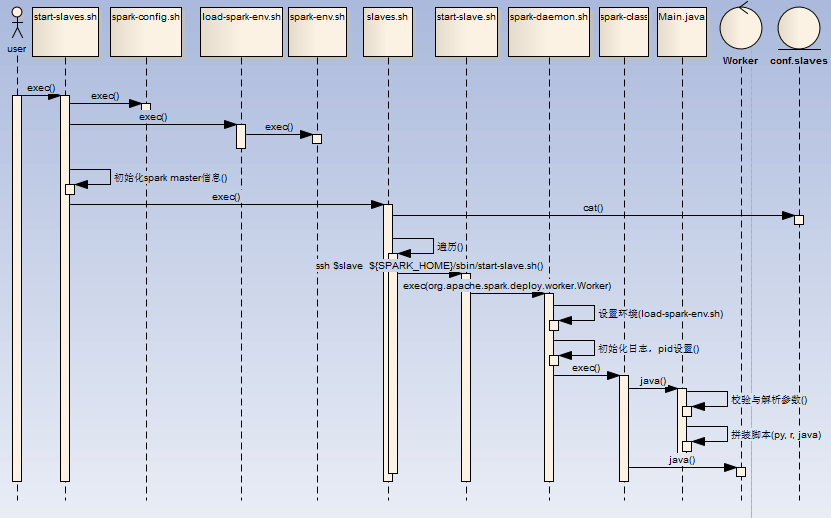
- 用户执行start-slaves.sh脚本,初始化环境变量SPARK_HOME,调用spark-config.sh,调用load-spark-env.sh,初始化Master host/port信息,
- 调用slaves.sh脚本,读取conf/slaves文件并遍历,通过ssh连接到对应slave节点,启动 ${SPARK_HOME}/sbin/start-slave.sh spark://$SPARK_MASTER_HOST:$SPARK_MASTER_PORT
- start-slave.sh在各个节点中,初始化环境变量SPARK_HOME,调用spark-config.sh,调用load-spark-env.sh,根据$SPARK_WORKER_INSTANCES计算WEBUI_PORT端口(worker端口号依次递增 )并启动Worker进程(${SPARK_HOME}/sbin /spark-daemon.sh start org.apache.spark.deploy.worker.Worker $WORKER_NUM --webui-port "$WEBUI_PORT" $PORT_FLAG $PORT_NUM $MASTER "$@")
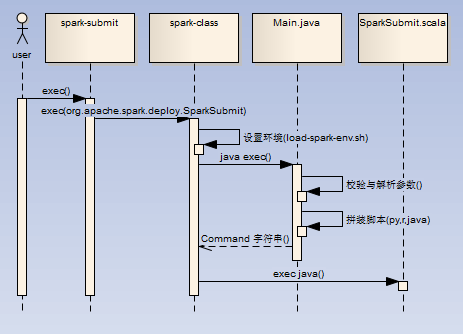
- 直接调用spark-class脚本进行进程创建(./spark-submit --class org.apache.spark.examples.SparkPi --master spark://zqh:7077 ../examples/jars/spark-examples_2.11-2.1.0.jar 10)
- 如果是java/scala任务,那么最终调用SparkSubmit.scala进行任务处理(/opt/jdk1.7.0_79/bin/java -cp /opt/spark-2.1.0/conf/:/opt/spark-2.1.0/jars/*:/opt/hadoop-2.6.4/etc/hadoop/ -Xmx1g -XX:MaxPermSize=256m org.apache.spark.deploy.SparkSubmit --master spark://zqh:7077 --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.1.0.jar 10)
- 公共的环境变量由spark-config.sh,bin/load-spark-env.sh进行统一的处理
- 扩在由conf/spark-env.sh进行配置读取实现
- 守护进程由spark-daemon.sh进行创建,进行相关的log,pid前置处理
- spark-class.sh是公共的处理入口脚本
- Main.java负责对参数的解析组装
- 最后执行组装好的command,其中支持scala/java/python/r
【Spark2.0源码学习】-2.一切从脚本说起的更多相关文章
- 【Spark2.0源码学习】-1.概述
Spark作为当前主流的分布式计算框架,其高效性.通用性.易用性使其得到广泛的关注,本系列博客不会介绍其原理.安装与使用相关知识,将会从源码角度进行深度分析,理解其背后的设计精髓,以便后续 ...
- spark2.0源码学习
[Spark2.0源码学习]-1.概述 [Spark2.0源码学习]-2.一切从脚本说起 [Spark2.0源码学习]-3.Endpoint模型介绍 [Spark2.0源码学习]-4.Master启动 ...
- 【Spark2.0源码学习】-3.Endpoint模型介绍
Spark作为分布式计算框架,多个节点的设计与相互通信模式是其重要的组成部分. 一.组件概览 对源码分析,对于设计思路理解如下: RpcEndpoint: ...
- 【Spark2.0源码学习】-6.Client启动
Client作为Endpoint的具体实例,下面我们介绍一下Client启动以及OnStart指令后的额外工作 一.脚本概览 下面是一个举例: /opt/jdk1..0_79/bin/jav ...
- 【Spark2.0源码学习】-4.Master启动
Master作为Endpoint的具体实例,下面我们介绍一下Master启动以及OnStart指令后的相关工作 一.脚本概览 下面是一个举例: /opt/jdk1..0_79/ ...
- 【Spark2.0源码学习】-5.Worker启动
Worker作为Endpoint的具体实例,下面我们介绍一下Worker启动以及OnStart指令后的额外工作 一.脚本概览 下面是一个举例: /opt/jdk1..0_79/ ...
- 【Spark2.0源码学习】-9.Job提交与Task的拆分
在前面的章节Client的加载中,Spark的DriverRunner已开始执行用户任务类(比如:org.apache.spark.examples.SparkPi),下面我们开始针对于用 ...
- 【Spark2.0源码学习】-10.Task执行与回馈
通过上一节内容,DriverEndpoint最终生成多个可执行的TaskDescription对象,并向各个ExecutorEndpoint发送LaunchTask指令,本节内容将关注Exe ...
- 【Spark2.0源码学习】-7.Driver与DriverRunner
承接上一节内容,Client向Master发起RequestSubmitDriver请求,Master将DriverInfo添加待调度列表中(waitingDrivers),下面针对于Dri ...
随机推荐
- RMI原理及简单示例
分布式对象 在学习 RMI 之前,先来分布式对象(Distributed Object):分布式对象是指一个对象可以被远程系统所调用.对于 Java 而言,即对象不仅可以被同一虚拟机中的其他客户程序( ...
- Robot Framework自动化测试环境部署
文档版本:v1.0 作者:令狐冲 如有问题请发邮件到:1146009864@qq.com 使用Robot Framework框架(以下简称RF)来做自动化测试. 模块化设计 1.所需环境一览表 软件 ...
- Palindrome Linked List leetcode
Given a singly linked list, determine if it is a palindrome. Follow up:Could you do it in O(n) time ...
- wemall app中基于Java获取和保存图片的代码
wemall-mobile是基于WeMall的android app商城,只需要在原商城目录下上传接口文件即可完成服务端的配置,客户端可定制修改.分享其中关于 保存正在下载的图片URL集合和图片三种获 ...
- Jmeter接口压力测试
SOAP百科:Soap简单对象访问协议,是交换数据的一种协议规范,是一种轻量的.简单的.基于XML(标准通用标记语言下的一个子集)的协议,它被设计成在WEB上交换结构化的和固化的信息.webServi ...
- EF批量插入(转)
原作者地址http://blog.csdn.net/zlts000/article/details/46385773 之前做项目的时候,做出来的系统的性能不太好,在框架中使用了EntityFramew ...
- Python快速入门(2)
var = raw_input() 获取用户输入,该函数会将获取的值转化为一个字符串,因此有时需要强制类型转换. if-elif-else: 三元操作符:condition1 if exp else ...
- bzoj3531——树链剖分+动态开点线段树
3531: [Sdoi2014]旅行 Time Limit: 20 Sec Memory Limit: 512 MB Description S国有N个城市,编号从1到N.城市间用N-1条双向道路连 ...
- 关于SQL的一些小知识
在代码中调用存储过程的时,必须先测试存储过程,存储过程测试成功之后再去java中去调用!!@!@#!@!@! 以后自己写的存储过程写一个本地保存一个.!~~~!!(这个很关键) 以后在代码中的SQL都 ...
- Android多渠道打包
项目需要,简单2步实现(由于简单,所以对大量渠道打包不是最优的),比如1000个渠道同时打包的话可能花费的时间会过长.不过目前该方法能满足绝大需求了...根据截图一步一步走: 第一步 设置配置清单文件 ...