Django查询数据库性能优化
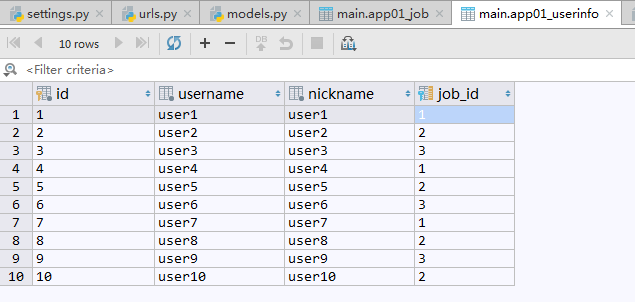
现在有一张记录用户信息的UserInfo数据表,表中记录了10个用户的姓名,呢称,年龄,工作等信息.
models文件
from django.db import models
class Job(models.Model):
title=models.CharField(max_length=32)
class UserInfo(models.Model):
username=models.CharField(max_length=32)
nickname=models.CharField(max_length=32)
job=models.ForeignKey(to="Job",to_field="id",null=True)
数据表中记录:
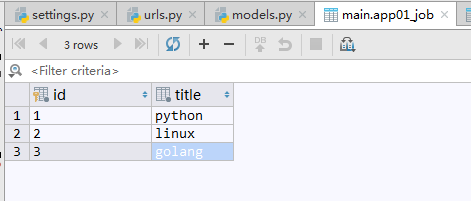
另一张数据表记录用户工作的Job表,关联用户的工作字段.
要查出每个用户的用户名,呢称和工作等信息
def index(request):
user_list=models.UserInfo.objects.all()
print(user_list.query) # 打印查询时使用的语句
print(type(user_list)) # 打印查询结果的数据类型
for user in user_list:
print("%s-->%s-->%s" %(user.username,user.nickname,user.job.title))
return render(request,'index.html')
打印信息:
SELECT "app01_userinfo"."id", "app01_userinfo"."username", "app01_userinfo"."nickname", "app01_userinfo"."job_id" FROM "app01_userinfo"
<class 'django.db.models.query.QuerySet'>
user1-->user1-->python
user2-->user2-->linux
user3-->user3-->golang
user4-->user4-->python
user5-->user5-->linux
user6-->user6-->golang
user7-->user7-->python
user8-->user8-->linux
user9-->user9-->golang
user10-->user10-->linux
在服务端进行这些操作,这些查询语句的性能是很低的,遍历取出这10个用户的姓名,呢称,工作等信息要在两张数据库中执行11次查询操作.
首先只从UserInfo表中查出所有的用户记录,需要执行一次查询操作.
查询Job数据表,每循环一次用户信息的列表,都需要从Job表中查询一次用户的工作信息.
数据表中总共记录了10条用户记录,所以还需要循环10次才能从Job表中查询完成所有用户的工作信息.所以一共需要执行11次数据库查询操作.
那有没有什么好的方法能够提高数据库查询的效率呢???
def index(request):
user_list=models.UserInfo.objects.values("username","nickname","job")
print(user_list.query) # 打印查询时使用的语句
print(type(user_list)) # 打印查询结果的数据类型
print("user_list:",user_list)
for user in user_list:
print(user["username"], user["nickname"], user["job"])
return render(request,'index.html')
运行程序,在服务端后台打印信息:
SELECT "app01_userinfo"."username", "app01_userinfo"."nickname", "app01_userinfo"."job_id" FROM "app01_userinfo"
<class 'django.db.models.query.QuerySet'>
user_list: <QuerySet [{'username': 'user1', 'nickname': 'user1', 'job': 1}, {'username': 'user2', 'nickname': 'user2', 'job': 2}, {'username': 'user3', 'nickname': 'user3', 'job': 3}, {'username': 'user4', 'nickname': 'user4', 'job': 1}, {'username': 'user5', 'nickname': 'user5', 'job': 2}, {'username': 'user6', 'nickname': 'user6', 'job': 3}, {'username': 'user7', 'nickname': 'user7', 'job': 1}, {'username': 'user8', 'nickname': 'user8', 'job': 2}, {'username': 'user9', 'nickname': 'user9', 'job': 3}, {'username': 'user10', 'nickname': 'user10', 'job': 2}]>
user1 user1 1
user2 user2 2
user3 user3 3
user4 user4 1
user5 user5 2
user6 user6 3
user7 user7 1
user8 user8 2
user9 user9 3
user10 user10 2
可以看到,查询的结果user_list依然是一个QuerySet,但这个对象集合内部却是一个字典.
而且这次的查询只执行了两次数据库查询操作.
通过这种方式,只需要两次查询就能得到想要的数据,优化了数据库的查询效率.
Django数据库优化操作之select_related主动联表查询
上面的例子里,取对象集合的时候,难道只能查询当前数据表,不能查询其他数据表吗??
当然不是,在这里还可以使用select_related这个方法.
在第一次查询的时候,在all()后面加上一个select_related来做主动的联表查询.
在创建这两张数据表时,job在UserInfo数据表中是做为一个ForeignKey存在的,所以加上select_related后不仅只查询到了UserInfo数据库的记录,同时也查询了Job数据表中的记录.
def index(request):
user_list=models.UserInfo.objects.all().select_related("job")
print(user_list.query) # 打印查询时使用的语句
print(type(user_list)) # 打印查询结果的数据类型
print("user_list:",user_list)
for user in user_list:
print("%s-->%s-->%s" %(user.username,user.nickname,user.job.title))
return render(request,'index.html')
服务端打印结果
SELECT "app01_userinfo"."id", "app01_userinfo"."username", "app01_userinfo"."nickname", "app01_userinfo"."job_id", "app01_job"."id", "app01_job"."title" FROM "app01_userinfo" LEFT OUTER JOIN "app01_job" ON ("app01_userinfo"."job_id" = "app01_job"."id")
<class 'django.db.models.query.QuerySet'>
user_list: <QuerySet [<UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>]>
user1-->user1-->python
user2-->user2-->linux
user3-->user3-->golang
user4-->user4-->python
user5-->user5-->linux
user6-->user6-->golang
user7-->user7-->python
user8-->user8-->linux
user9-->user9-->golang
user10-->user10-->linux
查看打印出来的查询语句,其中有"FROM "app01_userinfo" LEFT OUTER JOIN "app01_job" ON ("app01_userinfo"."job_id" = "app01_job"."id")"用来做联表查询,只需要一次就可以查询所有的数据了.
同样的,如果还想继续联表,例如在Job表中再加一个外键字段desc,只需要在查询语句中把desc加入进来就可以了
user_list=models.UserInfo.objects.all().select_related("job__desc")
这样一来就把三张表联系起来做联表查询了,但是一定要确保所加的字段为ForeignKey.
如果使用类似models.UserInfo.objects.all()语句进行查询时,不要做跨表查询,只查询当前表中有的数据,否则查询语句的性能会下降很多.
如果想查其他表中的数据,就加上select_related(ForeignKey字段名);
如果想取多个ForeignKey字段的数据,则可以使用select_related(ForeignKey字段1,ForeignKey字段2,...)
联表查询操作性能也会降低,select_related就是用来做主动联表查询的.
Django数据库优化操作之perfetch_related非主动联表查询
perfetch_related方法是既非主动联表查询,又不进行很多查询语句的一种折衷方案
修改视图函数index
def index(request):
user_list=models.UserInfo.objects.all().prefetch_related("job")
print(user_list.query) # 打印查询时使用的语句
print(type(user_list)) # 打印查询结果的数据类型
print("user_list:",user_list)
for user in user_list:
print("%s-->%s-->%s" %(user.username,user.nickname,user.job.title))
return render(request,'index.html')
后端打印结果
SELECT "app01_userinfo"."id", "app01_userinfo"."username", "app01_userinfo"."nickname", "app01_userinfo"."job_id" FROM "app01_userinfo"
<class 'django.db.models.query.QuerySet'>
user_list: <QuerySet [<UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>]>
user1-->user1-->python
user2-->user2-->linux
user3-->user3-->golang
user4-->user4-->python
user5-->user5-->linux
user6-->user6-->golang
user7-->user7-->python
user8-->user8-->linux
user9-->user9-->golang
user10-->user10-->linux
使用prefetch_related方法未联表执行两次查询操作
先查询用户表中的所有数据,把用户表中所有的job_id全部查询出来,并执行去重操作;
结果查询出用户的3种工作,接下来执行"select"语句查询"Job"数据表中的"title"字段
这样一来就只执行了两次数据表的查询操作
在prefetch_related方法中加入一个字段"job",执行了两次数据库查询操作;
如果再加一个字段,则会再多加一次数据为操作操作.
Django数据库优化操作之only方法
def index(request):
user_list=models.UserInfo.objects.all().only("username")
print(user_list.query) # 打印查询时使用的语句
print(type(user_list)) # 打印查询结果的数据类型
print("user_list:",user_list)
for user in user_list:
print("%s-->%s" %(user.username,user.nickname))
return render(request,'index.html')
服务端后台打印信息
SELECT "app01_userinfo"."id", "app01_userinfo"."username" FROM "app01_userinfo"
<class 'django.db.models.query.QuerySet'>
user_list: <QuerySet [<UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>]>
user1-->user1
user2-->user2
user3-->user3
user4-->user4
user5-->user5
user6-->user6
user7-->user7
user8-->user8
user9-->user9
user10-->user10
执行查询操作的时候加上only方法,其查询结果还是一个对象集合,但是从打印出的查询语句可以看到,执行查询操作时只查询了用户的id字段和username字段,并没有查询nickname字段.
但是在后面的循环中,又可以打印用户的nikename信息.为什么呢,因为又执行了一次查询的请求操作.由此得知,查询操作使用了only方法,在only方法中加入哪个查询字段,在后面就使用哪个查询字段.
加only参数是从查询结果中只取某个字段,而另外一个defer方法则是从查询结果中排除某个字段
Django数据库优化操作之defer方法
修改index视图函数
def index(request):
user_list=models.UserInfo.objects.all().defer("username")
print(user_list.query) # 打印查询时使用的语句
print(type(user_list)) # 打印查询结果的数据类型
print("user_list:",user_list)
for user in user_list:
print("%s" % user.nickname)
return render(request,'index.html')
服务端打印信息
SELECT "app01_userinfo"."id", "app01_userinfo"."nickname", "app01_userinfo"."job_id" FROM "app01_userinfo"
<class 'django.db.models.query.QuerySet'>
user_list: <QuerySet [<UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>]>
user1
user2
user3
user4
user5
user6
user7
user8
user9
user10
通过打印的查询语句可以知道,使用defer方法后,只从数据库中查询了用户的id字段和用户的nickname字段操作,并没有查询username字段,由此也可以提高Django查询数据库的性能.
Django查询数据库性能优化的更多相关文章
- SQL Server数据库性能优化之SQL语句篇【转】
SQL Server数据库性能优化之SQL语句篇http://www.blogjava.net/allen-zhe/archive/2010/07/23/326927.html 近期项目需要, 做了一 ...
- mysql数据库性能优化(包括SQL,表结构,索引,缓存)
优化目标减少 IO 次数IO永远是数据库最容易瓶颈的地方,这是由数据库的职责所决定的,大部分数据库操作中超过90%的时间都是 IO 操作所占用的,减少 IO 次数是 SQL 优化中需要第一优先考虑,当 ...
- 数据库性能优化:SQL索引
SQL索引在数据库优化中占有一个非常大的比例, 一个好的索引的设计,可以让你的效率提高几十甚至几百倍,在这里将带你一步步揭开他的神秘面纱. 1.1 什么是索引? SQL索引有两种,聚集索引和非聚集索引 ...
- DB2数据库性能优化介绍
DB2数据库性能优化介绍 作者:chszs,转载需注明.博客主页:http://blog.csdn.net/chszs 前段时间,我从CSDN得到了这本书<DB2数据库性能调整和优化(第2版)& ...
- 数据库性能优化一:SQL索引一步到位
SQL索引在数据库优化中占有一个非常大的比例, 一个好的索引的设计,可以让你的效率提高几十甚至几百倍,在这里将带你一步步揭开他的神秘面纱. 1.1 什么是索引? SQL索引有两种,聚集索引和非聚集索引 ...
- SQL Server 2016 查询存储性能优化小结
SQL Server 2016已经发布了有半年多,相信还有很多小伙伴还没有开始使用,今天我们来谈谈SQL Server 2016 查询存储性能优化,希望大家能够喜欢 作为一个DBA,排除SQL Ser ...
- (转)Db2 数据库性能优化中,十个共性问题及难点的处理经验
(转)https://mp.weixin.qq.com/s?__biz=MjM5NTk0MTM1Mw==&mid=2650629396&idx=1&sn=3ec17927b3d ...
- 基于SSD固态硬盘的数据库性能优化
基于SSD固态硬盘的数据库性能优化 2010-11-08 00:0051cto佚名 关键字:固态硬盘 数据库管理 SSD 企业软件热点文章 Java内存结构与模型结构分析 Oracle触发器的语法 ...
- MySQL 数据库性能优化之缓存参数优化
在平时被问及最多的问题就是关于 MySQL 数据库性能优化方面的问题,所以最近打算写一个MySQL数据库性能优化方面的系列文章,希望对初中级 MySQL DBA 以及其他对 MySQL 性能优化感兴趣 ...
随机推荐
- 再起航,我的学习笔记之JavaScript设计模式14(桥接模式)
桥接模式 桥接模式(Bridge): 在系统沿着多个维度变化的同时,又不增加其复杂度并已达到解耦 从定义上看桥接模式的定义十分难以理解,那么我们来通过示例来演示什么是桥接模式. 现在我们需要做一个导航 ...
- 记录-新建一个web应用的过程与曲折
第一步/ 打开eclipse,菜单栏下,File–New–Other-,打开后找到web–Dynamic Web Project,然后单击Next. 解释一下,Dynamic ,动态的,变化的,Dyn ...
- 程序员也有春天之HTTP/2.0配置
哎呀,一不小心自己的博客也是HTTP/2.0了,前段时间对网站进行了https迁移并上了CDN,最终的结果是这酱紫的(重点小绿锁,安全标示以及HTTP/2.0请求). 科普 随着互联网的快速发展,HT ...
- keepalive之LVS-DR架构
author:JevonWei 版权声明:原创作品 Keepalive实战之LVS-DR 实验目的:构建LVS-DR架构,为了达到LVS的高可用目的,故在LVS-DR的Director端做Keepal ...
- xcode模拟器不显示键盘解决方案
当我们使用Xcode进行开发的时候,并不是所有的时候都需要将代码运行在iPhone,有时候模拟器就可以解决这些问题, 但是当你使用模拟器的时候会发现,在TextFiled中输入信息时,如果你是用模拟器 ...
- Microsoft Visual Studio 打开代码出现乱码解决方案
在用VS编写代码时,文本的字符集可能和编译器的字符集不同,在这种情况下代码会显示出乱码. 解决办法: 在VS的工具->选项里面找到"文本编辑器",勾选“自动检测不带签名的UT ...
- 基于NIOS-II的示波器:PART3 初步功能实现
本文记录了在NIOS II上实现示波器的第三部分. 本文主要包括:硬件部分的BRAM记录波形,计算频率的模块,以及软件部分这两个模块的驱动. 本文所有的硬件以及工程参考来自魏坤示波仪,重新实现驱动并重 ...
- vSphere笔记01~02
Vmware vsphere 虚拟化 云和大数据的底层!!!! 分类 1.开源:openstack:Linux:难(无图形化) nosqleasystack公司 2.企业版本:vsphere sdn! ...
- 【Beta阶段】第七次scrum meeting
Coding/OSChina 地址 1. 会议内容 学号 主要负责的方向 昨日任务 昨日任务完成进度 接下去要做 99 PM 配合100完成联网功能 100% 设置个人中心的设计 100 DEV 开始 ...
- Swing-JMenu菜单用法-入门
菜单是Swing客户端程序不可获取的一个组件.窗体菜单大致由菜单栏.菜单和菜单项三部分组成,如下图所示: 由图可见,对于一个窗体,首先要添加一个JMenuBar,然后在其中添加JMenu,在JMenu ...