【Java IO流】对象的序列化和反序列化
对象的序列化和反序列化
1)对象序列化,就是将Object对象转换成byte序列,反之叫对象的反序列化。
2)序列化流(ObjectOutputStream),是字节的过滤流—— writeObject()方法
反序列化流(ObjectInputStream)—— readObject()方法
3)序列化接口(Serializable)
对象必须实现序列化接口,才能进行序列化,否则将出现异常。
注:这个接口,没有任何方法,只是一个【标准】
一、最基本的序列化和反序列过程
序列化和反序列都是以Object对象进行操作的,这里通过一个简单的案例来给大家演示一下对象序列化和反序列化的过程。
1)新建一个Student类(测试类)
注意:需要实现序列化接口的类才能进行序列化操作!!
@SuppressWarnings("serial")
public class Student implements Serializable{
private String stuno;//id
private String stuna;//姓名
private int stuage;//年龄
public String getStuno() {
return stuno;
}
public void setStuno(String stuno) {
this.stuno = stuno;
}
public String getStuna() {
return stuna;
}
public void setStuna(String stuna) {
this.stuna = stuna;
}
public Student() {
super();
// TODO Auto-generated constructor stub
}
public Student(String stuno, String stuna, int stuage) {
super();
this.stuno = stuno;
this.stuna = stuna;
this.stuage = stuage;
}
@Override
public String toString() {
return "Student [stuno=" + stuno + ", stuna=" + stuna + ", stuage=" + stuage + "]";
}
public int getStuage() {
return stuage;
}
public void setStuage(int stuage) {
this.stuage = stuage;
}
}
2)将Student类的实例序列化成文件
基本操作步骤如下:
- 指定序列化保存的文件
- 构造ObjectOutputStream类
- 构造一个Student类
- 使用writeObject方法序列化
- 使用close()方法关闭流
String file="demo/obj.dat";
//对象的序列化
ObjectOutputStream oos=new ObjectOutputStream(
new FileOutputStream(file));
//把Student对象保存起来,就是对象的序列化
Student stu=new Student("01","mike",18);
//使用writeObject方法序列化
oos.writeObject(stu);
oos.close();
运行结果:可以看到demo目录下生成了obj.dat的序列化文件
3)将文件反序列化读出Student类对象
基本操作步骤如下:
- 指定反序列化的文件
- 构造ObjectInputStream类
- 使用readObject方法反序列化
- 使用close方法关闭流
String file="demo/obj.dat";
ObjectInputStream ois =new ObjectInputStream(
new FileInputStream(file));
//使用readObject()方法序列化
Student stu=(Student)ois.readObject();//强制类型转换
System.out.println(stu);
ois.close();
运行结果:

注意:在文件反序列化时,readObject方法取出的对象默认都是Object类型,必须强制转换为相应的类型。
二、transient及ArrayList源码分析
在日常编程过程中,我们有时不希望一个类所有的元素都被编译器序列化,这时该怎么办呢?
Java提供了一个transient关键字来修饰我们不希望被jvm自动序列化的元素。下面简单来讲解一下这个关键字。
transient 关键字:被transient修饰的元素,该元素不会进行jvm默认的序列化,但可以自己完成这个元素的序列化。
注意:
1)在以后的网络编程中,如果有某些元素不需要传输,那就可以用transient修饰,来节省流量;对有效元素序列化,提高性能。
2)可以使用writeObject自己完成这个元素的序列化。
ArrayList就是用了此方法进行了优化操作。ArrayList最核心的容器Object[] elementData使用了transient修饰,但是在writeObject自己实现对elementData数组的序列化。只对数组中有效元素进行序列化。readObject与之类似。

--------------自己序列化的方式---------------
在要序列化的类中加入两个方法(这两个方法都是从ArrayList源码中提取出来的,比较特殊的两个方法):
private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException{
s.defaultWriteObject();//把jvm能默认序列化的元素进行序列化操作
s.writeInt(stuage);//自己完成被transient修饰的元素的序列化
}
private void readObject(java.io.ObjectInputStream s) throws java.io.IOException,ClassNotFoundException{
s.defaultReadObject();//把jvm能默认反序列化的元素进行反序列化操作
this.stuage=s.readInt();//自己完成stuage的反序列化操作
}
加入这两个方法后,即使被transient修饰的元素也能像刚刚那样进行序列化和反序列化了,jvm会自动使用这两个方法帮助我们完成这动作。
这里又有个问题,为什么还需要手动去完成序列化和反序列化呢,有什么意义呢?
这个问题得再从ArrayList的源码中去分析:


可以看出ArrayList源码中自己序列化的目的:ArrayList底层为数组,自己序列化可以过滤数组中无效的元素,只序列化数组中有效的元素,从而提高性能。
因此,实际编程过程中我们可以根据需要来自己完成序列化以提高性能。
三、序列化中子父类构造函数问题
在类的序列化和反序列化中,如果存在子类和父类的关系时,序列化和反序列化的过程又是怎么样的呢?
这里我写一个测试类来测试子类和父类实现序列化和反序列化时构造函数的实现变化。
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
String file="demo/foo.dat";
ObjectOutputStream oos=new ObjectOutputStream(
new FileOutputStream(file));
Foo2 foo2 =new Foo2();
oos.writeObject(foo2);
oos.flush();
oos.close();
}
}
class Foo implements Serializable{
public Foo(){
System.out.println("foo");
}
}
class Foo1 extends Foo{
public Foo1(){
System.out.println("foo1");
}
}
class Foo2 extends Foo1{
public Foo2(){
System.out.println("foo2");
}
}
运行结果:这是序列化时递归调用了父类的构造函数
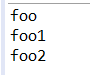
接来下看看反序列化时,是否递归调用父类的构造函数。
ObjectInputStream ois=new ObjectInputStream(
new FileInputStream(file));
Foo2 foo2=(Foo2)ois.readObject();
ois.close();
运行结果:控制台没有任何输出。
那么这个结果是否证明反序列化过程中父类的构造函数就是始终不调用的呢?
然而不能证明!!
因为再看下面这个不同的测试例子:
class Bar {
public Bar(){
System.out.println("bar");
}
}
class Bar1 extends Bar implements Serializable{
public Bar1(){
System.out.println("bar1");
}
}
class Bar2 extends Bar1{
public Bar2(){
System.out.println("bar2");
}
}
我们用这个例子来测试序列化和反序列化。
序列化结果:

反序列化结果:没实现序列化接口的父类被显示调用构造函数

【反序列化时】,向上递归调用构造函数会从【可序列化的一级父类结束】。即谁实现了可序列化(包括继承实现的),谁的构造函数就不会调用。
总结:
1)父类实现了serializable接口,子类继承就可序列化。
子类在反序列化时,父类实现了序列化接口,则不会递归调用其构造函数。
2)父类未实现serializable接口,子类自行实现可序列化
子类在反序列化时,父类没有实现序列化接口,则会递归调用其构造函数。
【Java IO流】对象的序列化和反序列化的更多相关文章
- Java—IO流 对象的序列化和反序列化
序列化的基本操作 1.对象序列化,就是将Object转换成byte序列,反之叫对象的反序列化. 2.序列化流(ObjectOutputStream),writeObject 方法用于将对象写入输出流中 ...
- Java——IO流 对象的序列化和反序列化流ObjectOutputStream和ObjectInputStream
对象的输入输出流 : 主要的作用是用于写入对象信息与读取对象信息. 对象信息一旦写到文件上那么对象的信息就可以做到持久化了 对象的输出流: ObjectOutputStream 对象的输入流: Ob ...
- Java基础-IO流对象之序列化(ObjectOutputStream)与反序列化(ObjectInputStream)
Java基础-IO流对象之序列化(ObjectOutputStream)与反序列化(ObjectInputStream) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.对象的序 ...
- Java IO流对象、多线程
Input(读) Output(写)操作 File类 import java.io.File; 将操作系统中的文件.目录(文件夹).路径.封装成File对象 提供方法,操作系统中的内容.File与系统 ...
- 慕课网_文件传输基础——Java IO流
第1章 文件的编码 1-1 文件的编码 (15:07) 第2章 File 类的使用 2-1 File 类常用 API 介绍 (10:50) import java.io.File; import ja ...
- Java对象的序列化与反序列化
序列化与反序列化 序列化 (Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程.一般将一个对象存储至一个储存媒介,例如档案或是记亿体缓冲等.在网络传输过程中,可以是字节或是 ...
- java IO流详解
流的概念和作用 学习Java IO,不得不提到的就是JavaIO流. 流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象.即数据在两设备间的传输称为流,流的本质是数据传输,根据数据传输 ...
- Java IO流详尽解析
流的概念和作用 学习Java IO,不得不提到的就是JavaIO流. 流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象.即数据在两设备间的传输称为流,流的本质是数据传输,根据数据传输 ...
- Java IO流详尽解析(转)
流的概念和作用 学习Java IO,不得不提到的就是JavaIO流. 流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象.即数据在两设备间的传输称为流,流的本质是数据传输,根据数据传输 ...
- Java IO流详解(一)——简单介绍
文件在程序中是以流的形式来传输的.所以用Java来传输文件就得使用到Java IO流. 1.流的概念和作用 流:代表任何有能力产出数据的数据源对象或者是有能力接受数据的接收端对象<Thinkin ...
随机推荐
- Final 关键字
1.涵义 最一般的意思就是声明 "这个东西不能改变".之所以要禁止改变,可能是考虑到两方面的因素:设计或效率. final 关键字可以用来修饰变量.方法和类,修饰变量表示变量不能被 ...
- VsCode 附加Chorme调试TS方法
命令行进入:[谷歌浏览器安装目录/]/chrome.exe --remote-debugging-port=9222 关闭所有窗口并结束Chorme进程(如果无法附加调试做此操作,可以正常调试请忽略. ...
- mysql 忘记root密码,重置密码,及重置密码后权限问题不能登录的解决方案
由于一段时间没有使用MySQL,忘记了root登录密码. 决定重置下密码,搜索帮助. 参考文档: http://blog.csdn.net/odailidong/article/details/507 ...
- Linux改变语言设置的命令
--Linux语言设置--------------2013/09/22Linux中语言的设置和本地化设置真是一个很繁琐的事情,时不时的会出现乱码的情况,在这篇文章中讨论的是shell中出现乱码的一些解 ...
- Android Tv 中的按键事件 KeyEvent 分发处理流程
这次打算来梳理一下 Android Tv 中的按键点击事件 KeyEvent 的分发处理流程.一谈到点击事件机制,网上资料已经非常齐全了,像什么分发.拦截.处理三大流程啊:或者 dispatchTou ...
- 第一天的php体验
第一次了解php.以前对于程序猿的认知是很片面的.因为没有了解过.今天通过一天的了解交流,有了新的认知.对于这个主要应用于前端的语言还是很有兴趣的.毕竟可以亲眼看到自己做出来的网页,心里的成就感肯定满 ...
- Python 字典和集合
泛映射类型 collections.abc 模块中有 Mapping 和 MutableMapping 这两个抽象基类,它们的作用是为 dict 和其他类似的类型定义形式接口(在Python 2.6 ...
- Relationship between frequency domain and spatial domain in digital images
今天又复习了一遍<<Digital Image Processing>>的第四章,为了加深对频域的理解,我自己用PS画了一张图.如下: 然后做FFT,得到频谱图如下: 从左到右 ...
- 质量体系 CMMI
CMMI初识 CMM-Capability Maturity Model,能力成熟度模型.CMMI-Capability Maturity Model Integration,能力成熟度模型集成. C ...
- 遇到local variable 'e' referenced before assignment这样的问题应该如何解决
问题:程序报错:local variable 'e' referenced before assignment 解决:遇到这样的问题,说明你在声明变量e之前就已经对其进行了调用,定位到错误的地方,对变 ...