CDH hadoop的安装
1
先拷贝tar包到目录底下(tar 包解压 tar zxvf)
2 :
1、使用课程提供的hadoop-2.5.0-cdh5.3.6.tar.gz,上传到虚拟机的/usr/local目录下。(http://archive.cloudera.com/cdh5/cdh/5/)
2、将hadoop包进行解压缩:tar -zxvf hadoop-2.5.0-cdh5.3.6.tar.gz
3、对hadoop目录进行重命名:mv hadoop-2.5.0-cdh5.3.6 hadoop
4、配置hadoop相关环境变量
vi ~/.bashrc
export HADOOP_HOME=/usr/local/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source ~/.bashrc
5、创建/usr/local/data目录(用来存放data目录)
3:配置core-site
(dir/hadoop/etc/hadoop/)
<property>
<name>fs.default.name</name>
<value>hdfs://sparkproject1:9000</value>
</property>
4:配置hdfs-site.xml
<property>
<name>dfs.name.dir</name>
<value>/usr/local/data/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/data/datanode</value>
</property>
<property>
<name>dfs.tmp.dir</name>
<value>/usr/local/data/tmp</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
4.配置map-site.xml(mapreduce配置)
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
5.修改yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>sparkproject1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
6:scp -r hadoop root@sparkproject2:/usr/local/soft
用scp命令把hadoop文件scp到别的机器上
7:把bashrc也拷贝到别的机器上
scp ~/.bashrc root@sparkproject2:~/
(同理拷贝到别的机器上)
8:hdfs格式化
1、格式化namenode:在sparkproject1上执行以下命令,hdfs namenode -format
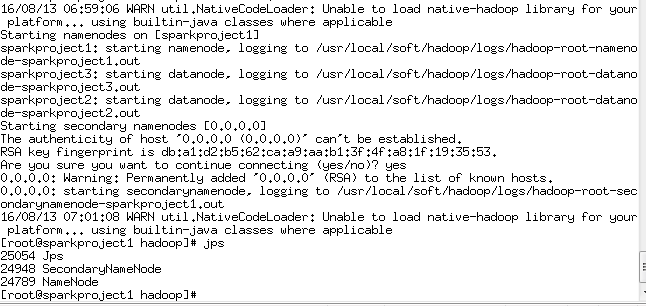
9:start-dfs.sh (yes)
CDH hadoop的安装的更多相关文章
- 使用yum安装CDH Hadoop集群
使用yum安装CDH Hadoop集群 2013.04.06 Update: 2014.07.21 添加 lzo 的安装 2014.05.20 修改cdh4为cdh5进行安装. 2014.10.22 ...
- Hadoop Linux安装
Hadoop Linux安装 步骤流程 1.硬件准备 2.软件准备(推荐CDH) 3.将Hadoop安装包分发到各个节点下 4.安装JDK 5.修改/etc/hosts配置文件 6.设置SSH免密码登 ...
- CDH集群安装&测试总结
0.绪论 之前完全没有接触过大数据相关的东西,都是书上啊,媒体上各种吹嘘啊,我对大数据,集群啊,分布式计算等等概念真是高山仰止,充满了仰望之情,觉得这些东西是这样的: 当我搭建的过程中,发现这些东西是 ...
- 【从零开始学习Hadoop】--1.Hadoop的安装
第1章 Hadoop的安装1. 操作系统2. Hadoop的版本3. 下载Hadoop4. 安装Java JDK5. 安装hadoop6. 安装rsync和ssh7. 启动hadoop8. 测试had ...
- hadoop环境安装及简单Map-Reduce示例
说明:这篇博客来自我的csdn博客,http://blog.csdn.net/lxxgreat/article/details/7753511 一.参考书:<hadoop权威指南--第二版(中文 ...
- hadoop群集安装中碰到的问题
在hadoop群集安装结束后,进行格式测试出现问题如下 格式化 cd /data/hadoop/bin ./hdfs namenode -format 15/01/21 05:21:17 WARN f ...
- 从零开始学习Hadoop--第1章 Hadoop的安装
Hadoop的安装比较繁琐,有如下几个原因:其一,Hadoop有非常多的版本:其二,官方文档不尽详细,有时候更新脱节,Hadoop发展的太快了:其三,网上流传的各种文档,或者是根据某些需求定制,或者加 ...
- Hadoop学习---安装部署
hadoop框架 Hadoop使用主/从(Master/Slave)架构,主要角色有NameNode,DataNode,secondary NameNode,JobTracker,TaskTracke ...
- hadoop分布式安装教程(转)
from:http://www.cnblogs.com/xia520pi/archive/2012/05/16/2503949.html 1.集群部署介绍 1.1 Hadoop简介 Hadoop是Ap ...
随机推荐
- Xcode6.2创建Empty Application
运行Xcode 6,创建一个Single View Application工程. 创建好后,把工程目录下的Main.storyboard和LaunchScreen.xib删除,扔进废纸篓. 打 ...
- linux下格式化硬盘与挂载硬盘
格式化: mkfs -t ext4 /dev/sdb 自动挂载: 编辑/etc/fstab文件 sudo nano /etc/fstab,如下图将设备/dev/sdb硬盘挂载到/home/solr/s ...
- sql面向过程用法
sql可以看成是面向过程的编程语言.该语言中,有string.date.table这样的类型等等 一.操作表 sql相当于一个函数,输入是两个或多个表(A, B, ...) 求集合: 并集 union ...
- greenDao 学习之坑 "java-gen" 目录下的类不能引用
由于公司最近的项目需要频繁地操作数据库,所以选用greenDao. 网上搜了一 大堆教程,我卡在java工程运行后生成的几个类不能引用了. 看了一下区别,教程的java-gen 目录是蓝色的小框框 , ...
- 2013年7月份第1周51Aspx源码发布详情
启睿网络信息服务器实例源码 2013-7-5 [ VS2005 ]功能介绍:睿网络信息服务器,QiRui Net Information Services简称QRNIS,该软件前身系KCIS.当前版 ...
- acm 20140825
为了自己的梦想,一次次的选择坚强.走上acm这条路,怎么也找不到让自己放弃的理由.我喜欢这种竞赛的氛围,我渴望在赛场上飞扬!想想过去的一个学习,自己并没有干点什么有意义的事.acm也没有好好的做!新的 ...
- oracle 之关键字exists
-----------------------------------------------------------------------SQL中EXISTS的用法---------------- ...
- hdu 2049
Ps:WA了无限次...简直做到崩溃..高中学的知识都忘了....这道题就是跟2048差不多.. 从N个人里选M个人,有Cmn种选法,然后就是M的错排*Cnm 代码: #include "s ...
- C# 控件聚焦
/********************************************************************** * C# 控件聚焦 * 说明: * 做界面经常需要将ta ...
- 【转载】GBDT(MART) 迭代决策树入门教程 | 简介
转载地址:http://blog.csdn.net/w28971023/article/details/8240756 GBDT(Gradient Boosting Decision Tree) 又叫 ...