Paper | Non-Local ConvLSTM for Video Compression Artifact Reduction
【这是MFQE 2.0的第一篇引用,也是博主学术生涯的第一篇引用。最重要的是,这篇文章确实抓住了MFQE方法的不足之处,而不是像其他文章,随意改改网络罢了。虽然引的是arXiv版本,但是很开心!欢迎大家引用TPAMI版本!】
在MFQE的基础上,作者提出了一个问题:“好”帧里的块的质量就好吗?“差”帧里的块的质量就差吗?显然不一定,因为帧的好/坏是由整张图像的综合质量决定的(如PSNR)。
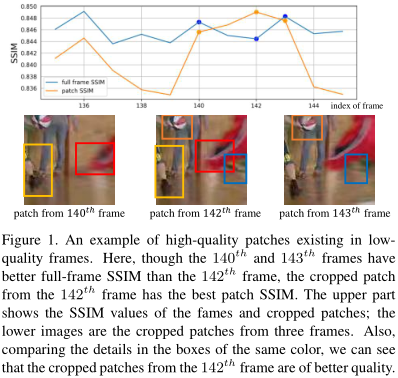
为了解决这个问题,作者提出用non-local结合ConvLSTM的思路。众所周知,NL是很耗时的,因此作者提出了一种近似计算帧间相似性的方法,从而加速NL过程。由于使用了ConvLSTM,因此本方法不再需要精确的MC。
1. 方法
1.1 框图
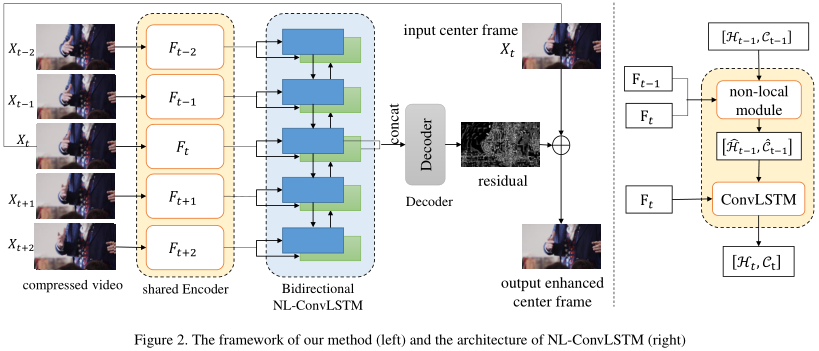
图画得很清楚。这是一个典型的Conv-LSTM,会连续输入多帧的卷积特征。在输出端,当前帧对应的双向隐藏层特征被拼接,进一步处理,最后作为残差与输入相加,即得到输出。
关键在于Conv-LSTM细胞的改进。由于去掉了MC组分,因此如果存在较大的运动位移,LSTM对运动的建模很可能失败。为此,作者引入了NL机制来建模运动位移。但是注意,这里的NL用来捕捉特征图间像素的相似性,而不是特征图内像素的相似性。因此,上一特征图\(F_t\)也要输入NL模块,但不输入Conv-LSTM细胞!
1.2 NL流程
我们具体讲一下改进后Conv-LSTM的工作流程。以下都以单向举例。
首先,ConvLSTM的经典输入输出格式是:输入当前特征图\(F_t\)、上一时刻隐藏层状态\(H_{t-1}\)和上一时刻细胞状态\(C_{t-1}\),输出当前时刻的隐藏层状态\(H_{t}\)和细胞状态\(C_{t}\):
\[
[H_{t}, C_{t}] = \text{ConvLSTM} (F_t, [H_{t-1}, C_{t-1}])
\]
为了让LSTM更好地建模运动位移,尤其是大尺度运动,作者在Conv-LSTM前引入NL技术,但是是特征图间的NL:
\[
S_t = \text{NL} (F_{t-1}, F_{t})
\]
\(S_t\)代表像素相似性,计算公式为:
\[
D_t(i,j) = \Vert F_{t-1} (i) - F_t (j) \Vert_2
\]
\[
S_t(i,j) = \frac{\exp (-D_t(i,j) / \beta)}{\sum_i \exp ((-D_t(i,j) / \beta)}
\]
其中,\(S_t(i,j)\)说的是 \(t-1\)特征图的第\(i\)个元素 与 当前\(t\)特征图的第\(j\)个元素 的相似度。显然要求关于\(i\)求和为1,因此用分母归一化。
NL的第二步,就是基于计算出的相似度,执行扭曲:
\[
[\hat{H}_{t}, \hat{C}_{t}] = \text{NLWarp} ([H_{t-1}, C_{t-1}], S_t)
\]
具体操作很简单:
\[
[\hat{H}_{t}, \hat{C}_{t}] = [\hat{H}_{t-1} \cdot S_t, \hat{C}_{t-1} \cdot S_t]
\]
【论文中的公式(4)有误,时刻写错了?】
1.3 加速版NL
如果严格按照以上步骤算,运动复杂度会很高。为此,作者引入了两步NL方法来近似 欧几里得距离\(D_t\) 和 特征图间像素相似度\(S_t\)。
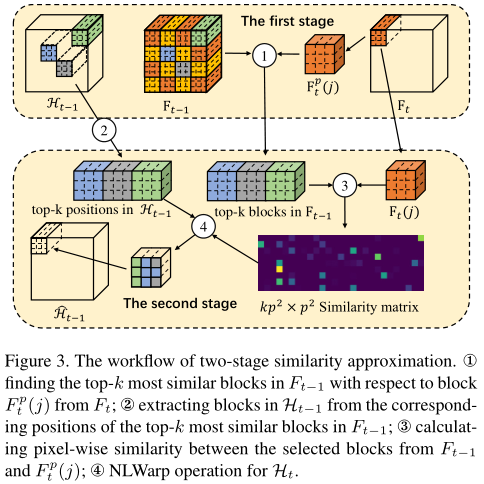
首先,对输入的特征图\(F_{t-1}\)和\(F_t\),我们作\(p \times p\)的平均池化,得到\(F^p_{t-1}\)和\(F_t^p\)。实验取\(p = 10\)。
然后我们再算它们的欧几里得距离矩阵\(D_t^p\)。此时,我们就能得到最相关的k个点。实验取\(k = 4\)。
这k个点对应原\(F_{t-1}\)的\(k \times p^2\)个点。后续操作就和上面一致了。
换句话说,这里有两点加速:(1)并不考虑所有点的相互关系,而只考虑前k个(其他的S为0);(2)先池化,在低维度上计算相似度。一个点代表一个块。
2. 实验
表2的前两列说明:输入多帧比输入单帧效果更好。作者还尝试了输入前后共20帧,结果比表2第4列还好。
作者尝试将NL换成了MC,结果不如NL,在dpsnr上差了20%。
NL找到的相似块也比较准。参见论文图4,红框是黄框的检测相似框。
Conv-LSTM耗时很猛,比对比算法高出好几倍,是MFQE 1.0的6-7倍。原因是要处理相邻多帧。但作者的加速已经很有效了,比原始NL加速了4倍。
3. 总结
本文对Fig1中阐释的问题进行了一定程度的处理。原因是:1、光流很难顾及全局关系,但相关度矩阵很擅长处理远距离关系。这就类似于GNN相比于传统CNN的优势。2、输入更多的相邻帧。
因此,本文的核心贡献是:在用Conv-LSTM建模时序和空域关系的同时,加入NL辅助完成了类似MC的功能。
Paper | Non-Local ConvLSTM for Video Compression Artifact Reduction的更多相关文章
- Paper | One-to-Many Network for Visually Pleasing Compression Artifacts Reduction
目录 故事 网络设计 网络前端 升采样中的平移-均值化 网络度量 训练 发表于2017年CVPR. 目标:JPEG图像去压缩失真. 主要内容: 同时使用感知损失.对抗损失和JPEG损失(已知量化间隔, ...
- DeepCoder: A Deep Neural Network Based Video Compression
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! Abstract: 在深度学习的最新进展的启发下,我们提出了一种基于卷积神经网络(CNN)的视频压缩框架DeepCoder.我们分别对预测 ...
- Paper | A Pseudo-Blind Convolutional Neural Network for the Reduction of Compression Artifacts
目录 非盲增强网络结构 训练目标 压缩系数预测子网络 网络结构 根据块QP判决结果得到帧QP预测结果 保持时序连续性 实验 发表在2019年TCSVT. 本文提出了一个兼具 预测压缩系数 和 非盲去压 ...
- Paper | Compression artifacts reduction by a deep convolutional network
目录 1. 故事 2. 方法 3. 实验 这是继SRCNN(超分辨)之后,作者将CNN的战火又烧到了去压缩失真上.我们看看这篇文章有什么至今仍有启发的故事. 贡献: ARCNN. 讨论了low-lev ...
- CVPR 2017 Paper list
CVPR2017 paper list Machine Learning 1 Spotlight 1-1A Exclusivity-Consistency Regularized Multi-View ...
- Video processing systems and methods
BACKGROUND The present invention relates to video processing systems. Advances in imaging technology ...
- paper 27 :图像/视觉显著性检测技术发展情况梳理(Saliency Detection、Visual Attention)
1. 早期C. Koch与S. Ullman的研究工作. 他们提出了非常有影响力的生物启发模型. C. Koch and S. Ullman . Shifts in selective visual ...
- SCI&EI 英文PAPER投稿经验【转】
英文投稿的一点经验[转载] From: http://chl033.woku.com/article/2893317.html 1. 首先一定要注意杂志的发表范围, 超出范围的千万别投,要不就是浪费时 ...
- ### Paper about Event Detection
Paper about Event Detection. #@author: gr #@date: 2014-03-15 #@email: forgerui@gmail.com 看一些相关的论文. 1 ...
随机推荐
- 关于group by的用法 原理
转载: https://blog.csdn.net/u014717572/article/details/80687042. 写在前面的话:用了好久group by,今天早上一觉醒来,突然感觉grou ...
- ASP.NET Core 集成测试中模拟登录用户的一种姿势
不管哪种用户验证方式,最终都是在验证成功后设置 HttpContext.User ,后续处理环节通过 HttpContext.User 获取用户信息.如果能直接修改 HttpContext.User ...
- 1+x证书web前端开发jquery专项练习测试题
javascript程序设计-题库 1.下面哪一种不属于Jquery的选择器? A. 基本选择器 B. 层次选择器 C. 表单选择器 D. 节点选择器 答案: D 2.如果需要匹配包含文本的元素,用下 ...
- Mac(PC)连接虚拟机MySQL失败
解决: 首先登陆虚拟机的MySQL use mysql; select host,user from user; 可以看到,默认的mysql只允许本机访问 将host设置为通配符模式%,Host设置为 ...
- SSD与HDD、HHD的区别
SSD与HDD.HHD的区别 HDD机械硬盘 SSD固态硬盘 HHD混合硬盘
- 前端之本地存储和jqueryUI
本地存储 本地存储分为cookie,以及新增的localStorage和sessionStorage 1.cookie 存储在本地,容量最大4k,在同源的http请求时携带传递,损耗带宽,可设置访问路 ...
- Web前端基础(6):CSS(三)
1. 定位 定位有三种:相对定位.绝对定位.固定定位 1.1 相对定位 现象和使用: 1.如果对当前元素仅仅设置了相对定位,那么与标准流的盒子什么区别. 2.设置相对定位之后,我们才可以使用四个方向的 ...
- Python3中13个实例汇总
1.Python数字求和 # -*- codingLuft-8 -*- #Filename: test.py #author by:Leq #用户输入数字 num1 = input("输入第 ...
- katalon studio升级到6.3.3版本后如何生成测试报告
背景: katalon studio 6.3.0版本开始,默认不会生成测试报告,因此,原先自动化运行结果的邮件也就不会包含测试报告附件. 解决方法如下: 通过插件[basic reports]生成测试 ...
- js将4个字节型字符串转为Float
function convertFloat(byteStr) { var buffer = str2ArrayBuffer(byteStr, 4); var dataView = new DataVi ...