Clock Crossing Adapter传输效率分析 (Latency增加,传输效率降低)
原创By DeeZeng [ Intel FPGA笔记 ]
在用Nios II测试 DDR3时候发现一个现象 (测试为:写全片,读全片+比对)
- 用单独的PLL产生时钟(200MHz)驱动 Nios II, 测试DDR3时间为87s
- 用 DDR3 IP的 afi_clk(200MHz) 驱动 Nios II, 测试DDR3时间为67s
只是换了个时钟为什么影响这么大?相差近 20s
分析发现
- PLL 产生的时钟 和 DDR3 的afi_clk 是两个时钟域
- Qsys interconnect 会在 Avalon MM 不同时钟域 自动插入 Clock Crossing Adapter
- Nios II的读写 和 Clock Crossing Adapter 特性造成传输效率低下
接下来将具体分析一下,为什么测试时间会相差那么大:
一、跨时钟域 Qsys自动插入 Clock Crossing Adapter
1. 当Avalon MM Master 和 Avalon MM Slave 的时钟为不同时钟的时候 (类似Nios II 用pll 200MHz , DDR3 都用了 afi_clk 200MHz)
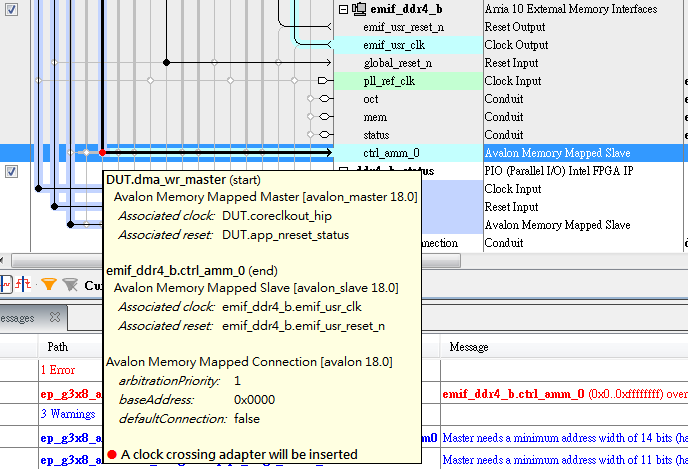
我们将鼠标悬浮在 黑圆点那 可以看到连接信息,并且 红点提示:A Clock Crossing adapter will be inserted
2. 当Avalon MM Master 和 Avalon MM Slave 的时钟为同一个的时候 (类似Nios II 和 DDR3 都用了 afi_clk)
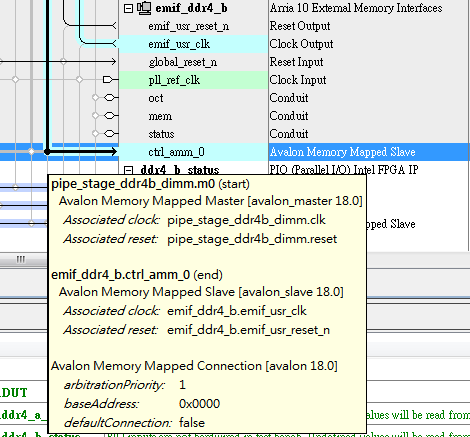
我们将鼠标悬浮在 黑圆点那 可以看到连接信息, 然后不会有Clock Crossing Bridge提示
二、 Clock Crossing Adapter 将增加 多个周期 的 latency
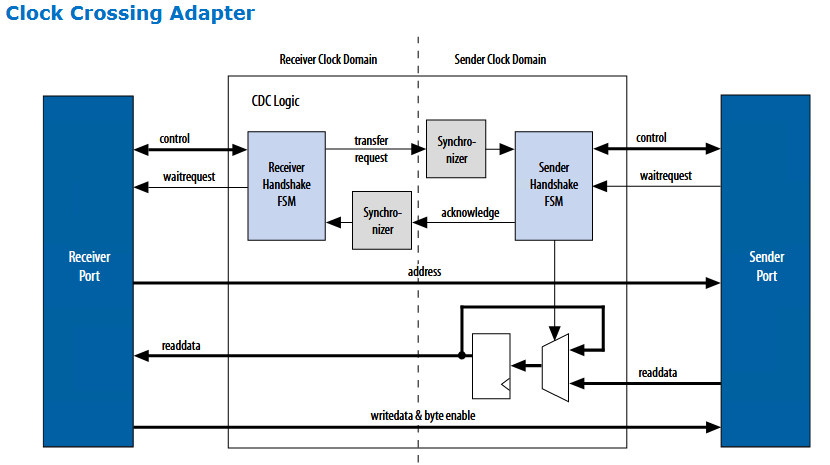

如上两图,可以看出Clock Crossing Adapter的架构 将导致增加几个周期的 latency
三、增加的Latency 对传输效率有什么影响?
1. 低效率的读写操作,雪上加霜
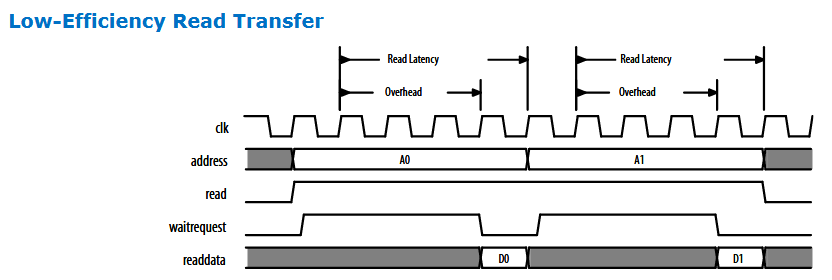
如果本身传输协议就是如上图这种低效的。 动作半天,只读了一个word。 那增加几个latency后效率变得更低下
举例:
如果原来4个周期出一个Word, 那效率是 25%
而加上5个周期 latency后,变为9个周期出一个Word,效率降低为 11%
2. 高效率的读写操作,影响不大
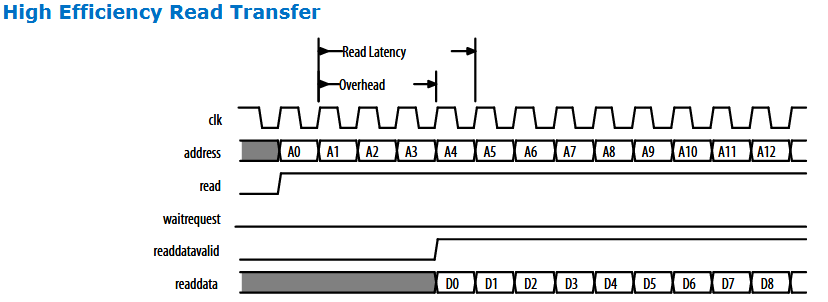
如果本身传输协议就是如上图这种高效的。 burst传输,只是延迟几个周期
举例:
如果原来4个周期出delay,一次传输100个word 耗时 104 ,效率为 96%
而加上5个周期 latency后,变为109个周期出100 Word,效率降低为 92%
四、Nios II 的读写是什么情况呢?
从上面 一 二 三 点分析,我们已经知道测试时间增长的原因:增加的 Timing Crossing Adapter造成传输效率变低了
经查手册,找到一个 Nios II 的 操作时序图(并非Nios II 操作DDR3的) ,操作 latency4个周期 一次操作8个
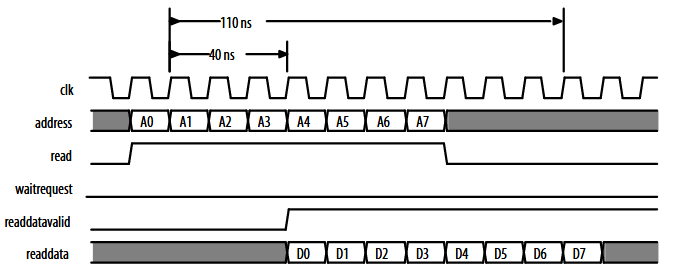
举例:
如果原来4个周期出delay,一次传输8个word 耗时 12,效率为 66%
插入Timing Adapter 假设增加了5个周期 latency后,变为17个周期出8Word,效率降低为 47%
(这里只是举例, Nios II操作DDR3实际并非这种时序。 DDR3 -> DDR -> Quarter Bridge ->,
DDR3的read latency也会随着这些bridge变换。bus变换过程中也增加了Width Adapter等,所以只是简单判断原因 )
所以 测试DDR3为:写全片,读全片+比对。比对耗时一致。读写变慢导致时间差异
这篇博文的目的:
1. 关注带宽和吞吐量的应用,注意一下这些 Clock Crossing Adapter 和 Pipe Bridge 的添加 (注意到 Bridge有可能降低传输效率这回事)
分析 bridge带来 fmax 的提升,和效率降低的权衡。 (其实关键就是尽量burst 提升传输效率)
2. 这篇分析 并不是不建议用 Timing Clock Crossing Adapter (注意到 Bridges 还有很多其他作用)
它还有很多的作用 如
1. 提升fmax
2.调节架构(多个master,多个slave)节省逻辑资源
3. ...
Clock Crossing Adapter传输效率分析 (Latency增加,传输效率降低)的更多相关文章
- 用wireshark抓包分析TCP三次握手、四次挥手以及TCP实现可靠传输的机制
关于TCP三次握手和四次挥手大家都在<计算机网络>课程里学过,还记得当时高超老师耐心地讲解.大学里我遇到的最好的老师大概就是这位了,虽然他只给我讲过<java程序设计>和< ...
- Linux内核NAPI机制分析
转自:http://blog.chinaunix.net/uid-17150-id-2824051.html 简介:NAPI 是 Linux 上采用的一种提高网络处理效率的技术,它的核心概念就是不采用 ...
- Android程序员必知必会的网络通信传输层协议——UDP和TCP
1.点评 互联网发展至今已经高度发达,而对于互联网应用(尤其即时通讯技术这一块)的开发者来说,网络编程是基础中的基础,只有更好地理解相关基础知识,对于应用层的开发才能做到游刃有余. 对于Android ...
- java 网络通信传输层协议——UDP和TCP
本文原文由作者“zskingking”发表于:jianshu.com/p/271b1c57bb0b,本次收录有改动. 1.点评 互联网发展至今已经高度发达,而对于互联网应用(尤其即时通讯网专注的即时通 ...
- WebRTC 源码分析(五):安卓 P2P 连接过程和 DataChannel 使用
从本篇起,我们将迈入新的领域:网络传输.首先我们看看 P2P 连接的建立过程,以及 DataChannel 的使用,最终我们会利用 DataChannel 实现一个 P2P 的文字聊天功能. P2P ...
- 网络流量分析——NPMD关注IT运维、识别宕机和运行不佳进行性能优化。智能化分析是关键-主动发现业务运行异常。科来做APT相关的安全分析
科来 做流量分析,同时也做了一些安全分析(偏APT)——参考其官网:http://www.colasoft.com.cn/cases-and-application/network-security- ...
- 无线网络中的MIMO与OFDM技术原理分析
无线网络中的MIMO与OFDM技术原理分析CNET中国·ZOL 07年08月14日 [原创] 作者: 中关村在线 张伟 从最早的红外线技术到目前被寄予重望的WIFI,无线技术的进步推动我们的网络一步步 ...
- FPGA中的delay与latency
delay和latency都有延迟的意义,在FPGA中二者又有具体的区别. latency出现在时序逻辑电路中,表示数据从输入到输出有效经过的时间,通常以时钟周期为单位. delay出现在组合逻辑电路 ...
- java容器类分析:Collection,List,ArrayList
1. Iterable 与 Iterator Iterable 是个接口,实现此接口使集合对象可以通过迭代器遍历自身元素. public interface Iterable<T> 修饰符 ...
随机推荐
- Python实现按键精灵(二)-找图找色
一.实现功能 判断在指定坐标范围内,是否存在相似度大于n的图片,并返回坐标. 二.基本思路 A=你需要寻找的图片 B=截取当前页面中指定范围的图片 利用opencv 判断A在B中的位置, 在该位置截取 ...
- 玩转java多线程(wait和notifyAll的正确使用姿势)
转载请标明博客的地址 本人博客和github账号,如果对你有帮助请在本人github项目AioSocket上点个star,激励作者对社区贡献 个人博客:https://www.cnblogs.com/ ...
- linux 十五个原理知识点
DNS系统架构与解析原理http协议通信原理TCP/IP的3次握手和四次断开原理MySQL主从同步原理Nginx配合php的fastcgi工作原理Lvs的4种模式工作原理Memcached工作原理(内 ...
- 错误处理之try、catch、finally中的return、throw执行顺序。
今天遇到一个让人无语的代码块 try { bilSheetService.syncUser(bilWebseviceLog, userId, optType); }catch (Exception e ...
- Laravel --- 【转】安装调试利器 Laravel Debugbar
[转]http://www.tuicool.com/articles/qYfmmur 1.简介 Laravel Debugbar 在 Laravel 5 中集成了 PHP Debug Bar ,用于显 ...
- Fiddler如何自动修改请求和响应包
Charles的Map功能可以将某个请求进行重定向,用重定向的内容响应请求的内容.这个功能非常方便.在抓包过程当中,有时候为了调试方便,需要将线上的服务定位到内网.比如我们线上的服务器域名为 api. ...
- QT 资料收集 (不定期添加)
Qt之界面实现技巧 http://blog.sina.com.cn/s/blog_a6fb6cc90101dech.html
- 简单的 自动生成 二维码 PHP 方法
方法一:<style type="text/css">.eweima{ width:200px; height:200px; margin:auto;}</ ...
- 大白话5分钟带你走进人工智能-第31节集成学习之最通俗理解GBDT原理和过程
目录 1.前述 2.向量空间的梯度下降: 3.函数空间的梯度下降: 4.梯度下降的流程: 5.在向量空间的梯度下降和在函数空间的梯度下降有什么区别呢? 6.我们看下GBDT的流程图解: 7.我们看一个 ...
- TPL DataFlow .Net 数据流组件,了解一下
回顾上文 作为单体程序,依赖的第三方服务虽不多,但是2C的程序还是有不少内容可讲: 作为一个常规互联网系统,无外乎就是接受请求.处理请求,输出响应. 由于业务渐渐增长,数据处理的过程会越来越复杂和冗长 ...