Python中字符的编码与解码
1 文本和字节序列
我们都知道字符串,就是由一些字符组成的序列构成串,那么字符又是什么呢?计算机只能识别二进制的东西,那么计算机又为什么会显示我们的汉字,或者是某个字母呢?
由于最早发明使用计算机是美国人,他们为了解决了英语如何在电脑上显示,就制定了一套标准:ASCII ((American Standard Code for Information Interchange): 美国信息交换标准代码),主要用于显示现代英语和其他西欧语言。到目前为止共定义了128个字符,从0-127的二进制数分别对应了相应的字符,这样就将现实中的字符和计算机的二进制联系起来,从而将字符表达显示在计算机上。
随机计算机的普遍,各国有不同的语言,每个国家为了普及计算机的使用,那么如何将各自国家的语言表达在计算机上就成了一个问题。于是,不同的国家都在制定适用自个国家的字符集,比如对于我国来说,就有gbk《汉字内码扩展规范》,它也是将每个字符(字)和计算机的二进制对应起来。那么问题来了,不同的国家使用各自国家的一套规范,在跨国交流时,就会出现文本显示的乱码。于是就有了一套统一的机制Unicode。Unicode(统一码、万国码、单一码),它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
1.1 字符和字节
目前使用的基本是Unicode定义的字符,从Python3的str对象中获取的元素就是Unicode字符。字符的具体表述取决于所用的编码。编码是在码位和字节序列之间转换时使用的算法。使用最多的是utf-8编码,使用该编码,文本文件可以跨平台显示。把码位转换成字节序列的过程是编码;把字节转换成码位的过程是解码。
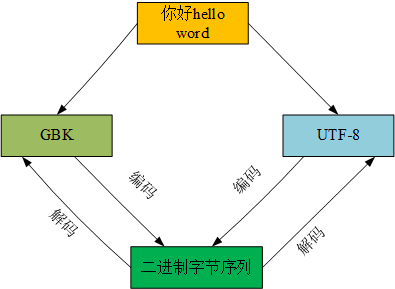
编码时使用的编码算法要与解码时使用的解码算法相同,要不然会出现乱码的现象。
1.2 字符与字节的转换
字符是组成字符串有序序列的单个元素,字符可以用上面的编码来理解。字符串按照不同的字符集编码返回字节序列bytes。

字节序列安装不同的字符集解码返回字符串
1 bytes.decode(encoding="utf-8", errors="strict") -> str
2 bytearray.decode(encoding="utf-8", errors="strict") -> str
1.3 bytes与bytearray
Python中内置了两种基本的二进制序列类型:Python 3 引入的不可变bytes类型和Python 2.6 增加的可变bytearray类型(字节数组)
1.3.1 bytes定义
bytes有以下的定义方法:
| Definition | Function |
| bytes() | 定义空的bytes |
|
bytes(int) |
指定字节的bytes,被0填充 |
| bytes(iteeable_of_ints) | bytes[0,255]的int组成的可迭代对象 |
| bytes(string, encoding[, errors]) | 等价于string.encode() |
| bytes(bytes_or_buffer) |
immutable copy of bytes_or_buffer 从一个字节序列或者buffer复制出 |
| 使用b前缀定义 |
只允许基本ASCII使用字符形式b'abc9'; 使用16进制表示b"\x41\x61" |
1.3.2 bytes操作
和str类型类似,都是不可变类型,所以很多方法都一样。只不过bytes的方法,输入的是bytes,输出的也是bytes。下面看bytes的基本操作:
- b'abcdef'.replace(b'f',b'k')
- b'abc'.find(b'b')
- bytes.fromhex(string) string必须是2个字符的16进制的形式,比如bytes.fromhex('6162 09 6a 6b00'),空格将被忽略
- 'abc'.encode().hex() 返回16进制表示的字符串
- b'abcdef'[2] 返回该字节对应的数,int类型
1.3.3 bytearray定义
| Definition | Function |
| bytearray() | 空bytearray |
| bytearray(int) | 指定字节的bytearray,被0填充 |
| bytearray(iterable_of_ints) | bytearray [0,255]的int组成的可迭代对象 |
| bytearray(string, encoding[, errors]) | bytearray 近似string.encode(),不过返回可变对象 |
| bytearray(bytes_or_buffer) | 从一个字节序列或者buffer复制出一个新的可变的bytearray对象 |
1.3.4 bytearray操作
和bytes类型的方法相同:
- bytearray(b'abcdef').replace(b'f',b'k')
- bytearray(b'abc').find(b'b')
- bytearray.fromhex('6162 09 6a 6b00')
- bytearray('abc'.encode()).hex()
- bytearray(b'abcdef')[2] 返回该字节对应的数,int类型
bytearray是字节型的数组,相当于列表一样,只不过bytearray中存储的是字节形式的序列。它也支持和列表一些相同的操作:
Python中字符的编码与解码的更多相关文章
- Python中进行Base64编码和解码
Base64编码 广泛应用于MIME协议,作为电子邮件的传输编码,生成的编码可逆,后一两位可能有“=”,生成的编码都是ascii字符.优点:速度快,ascii字符,肉眼不可理解缺点:编码比较长,非常容 ...
- python中的URL编码和解码
python中的URL编码和解码:test.py # 引入urllib的request模块 import urllib.request url = 'https://www.douban.com/j/ ...
- python中字符串的编码和解码
1. 常用的编码 ASCII:只能表示一些字母,数字和特殊的字符,占一个字节 GBK:国家简体中文字符集和繁体字符集,兼容ASCII,占两个字节 Unicode:能够表示全世界上所有的字符,Unico ...
- python的str,unicode对象的encode和decode方法, Python中字符编码的总结和对比bytes和str
python_2.x_unicode_to_str.py a = u"中文字符"; a.encode("GBK"); #打印: '\xd6\xd0\xce\xc ...
- 使用 URLDecoder 和 URLEncoder 对中文字符进行编码和解码
原文: https://blog.csdn.net/justloveyou_/article/details/57156039 使用 URLDecoder 和 URLEncoder 对中文字符进行编码 ...
- Python之字符与编码笔记
概述 类型 str 字符串 bytes 字节 bytearray 字节数组 字符串编码架构 字符集:赋值一个编码到某个字符,以便在内存中表示 编码 Ecoding:转换字符到原始字节形式 解码 Dec ...
- java中URL 的编码和解码函数
java中URL 的编码和解码函数java.net.URLEncoder.encode(String s)和java.net.URLDecoder.decode(String s);在javascri ...
- 如何在Python 中使用UTF-8 编码 && Python 使用 注释,Python ,UTF-8 编码 , Python 注释
如何在Python 中使用UTF-8 编码 && Python 使用 注释,Python ,UTF-8 编码 , Python 注释 PIP $ pip install beauti ...
- python中字符编码及unicode和utf-8区别
ascii和unicode是字符集,utf-8是编码集 字符集:为每一个「字符」分配一个唯一的 ID(学名为码位 / 码点 / Code Point) 编码规则:将「码位」转换为字节序列的规则(编码/ ...
随机推荐
- [译]Vulkan教程(14)图形管道基础之固定功能
[译]Vulkan教程(14)图形管道基础之固定功能 Fixed functions 固定功能 The older graphics APIs provided default state for m ...
- SpringCloud gateway (史上最全)
疯狂创客圈 Java 分布式聊天室[ 亿级流量]实战系列之 -25[ 博客园 总入口 ] 前言 ### 前言 疯狂创客圈(笔者尼恩创建的高并发研习社群)Springcloud 高并发系列文章,将为大家 ...
- C语言程序设计100例之(20):过河卒
例20 过河卒 题目描述 如图1,在棋盘的A点有一个过河卒,需要走到目标B点.卒行走规则:可以向下.或者向右.同时在棋盘上的任一点有一个对方的马(如图1的C点),该马所在的点和所有跳跃一步可达的点称 ...
- Latex学习与使用
Table of Contents Latex学习与使用 简介 文档结构 排版 表格 图片 公式 索引 简介 Latex(发音lay-tek)是一个用来产生专业文档的系统,但它并不是一个单词处理器.它 ...
- kubernetes haproxy+keepalive实现master集群高可用
前言 master的HA,实际是apiserver的HA.Master的其他组件controller-manager.scheduler都是可以通过etcd做选举(--leader-elect),而A ...
- react+ant-mobile+lib-flexible构建移动端项目适应设计图尺寸(750)
使用lib-flexible在react中先安装 npm install lib-flexible --save 因为插件使用的是rem适配,所以安装两个插件 npm install postcss- ...
- Oracle - SPM固定执行计划(二)
一.前言 前面文章(https://www.cnblogs.com/ddzj01/p/11365541.html)给大家介绍了当一条sql有多个执行计划时,如何通过spm去绑定其中一条执行计划.本文将 ...
- javaWeb核心技术第十三篇之Ajax
Js--ajax--原理解释 概述:异步刷新网页,不会刷新整个页面. Get原理: <%@ page language="java" contentType="te ...
- java简单实现用语音读txt文档
最近比较无聊,随便翻着博客,无意中看到了有的人用VBS读文本内容,也就是读几句中文,emmm,挺有趣的,实现也很简单,都不需要安装什么环境,直接新建txt文件,输入一些简单的vbs读文本的代码,然后将 ...
- 2015 经典的ImageCaptioning论文
1.Show and Tell: A Neural Image Caption Generator Google团队的成果 整体处理流程: 1)通过CNN提取到图片的特征,简称feature. 2)而 ...