缓存淘汰算法之LFU
1. LFU类
1.1. LFU
1.1.1. 原理
LFU(Least Frequently Used)算法根据数据的历史访问频率来淘汰数据,其核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。
1.1.2. 实现
LFU的每个数据块都有一个引用计数,所有数据块按照引用计数排序,具有相同引用计数的数据块则按照时间排序。
具体实现如下: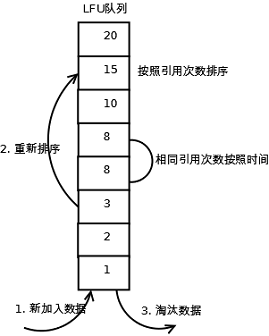
1. 新加入数据插入到队列尾部(因为引用计数为1);
2. 队列中的数据被访问后,引用计数增加,队列重新排序;
3. 当需要淘汰数据时,将已经排序的列表最后的数据块删除。
1.1.3. 分析
l 命中率
一般情况下,LFU效率要优于LRU,且能够避免周期性或者偶发性的操作导致缓存命中率下降的问题。但LFU需要记录数据的历史访问记录,一旦数据访问模式改变,LFU需要更长时间来适用新的访问模式,即:LFU存在历史数据影响将来数据的“缓存污染”效用。
l 复杂度
需要维护一个队列记录所有数据的访问记录,每个数据都需要维护引用计数。
l 代价
需要记录所有数据的访问记录,内存消耗较高;需要基于引用计数排序,性能消耗较高。
1.2. LFU*
1.2.1. 原理
基于LFU的改进算法,其核心思想是“只淘汰访问过一次的数据”。
1.2.2. 实现
LFU*数据缓存实现和LFU一样,不同的地方在于淘汰数据时,LFU*只淘汰引用计数为1的数据,且如果所有引用计数为1的数据大小之和都没有新加入的数据那么大,则不淘汰数据,新的数据也不缓存。
1.2.3. 分析
l 命中率
和LFU类似,但由于其不淘汰引用计数大于1的数据,则一旦访问模式改变,LFU*无法缓存新的数据,因此这个算法的应用场景比较有限。
l 复杂度
需要维护一个队列,记录引用计数为1的数据。
l 代价
相比LFU要低很多,不需要维护所有数据的历史访问记录,只需要维护引用次数为1的数据,也不需要排序。
1.3. LFU-Aging
1.3.1. 原理
基于LFU的改进算法,其核心思想是“除了访问次数外,还要考虑访问时间”。这样做的主要原因是解决LFU缓存污染的问题。
1.3.2. 实现
虽然LFU-Aging考虑时间因素,但其算法并不直接记录数据的访问时间,而是通过平均引用计数来标识时间。
LFU-Aging在LFU的基础上,增加了一个最大平均引用计数。当当前缓存中的数据“引用计数平均值”达到或者超过“最大平均引用计数”时,则将所有数据的引用计数都减少。减少的方法有多种,可以直接减为原来的一半,也可以减去固定的值等。
1.3.3. 分析
l 命中率
LFU-Aging的效率和LFU类似,当访问模式改变时,LFU-Aging能够更快的适用新的数据访问模式,效率要高。
l 复杂度
在LFU的基础上增加平均引用次数判断和处理。
l 代价
和LFU类似,当平均引用次数超过指定阈值(Aging)后,需要遍历访问列表。
1.4. LFU*-Aging
1.4.1. 原理
LFU*和LFU-Aging的合成体。
1.4.2. 实现
略。
1.4.3. 分析
l 命中率
和LFU-Aging类似。
l 复杂度
比LFU-Aging简单一些,不需要基于引用计数排序。
l 代价
比LFU-Aging少一些,不需要基于引用计数排序。
1.5. Window-LFU
1.5.1. 原理
Windows-LFU是LFU的一个改进版,差别在于Window-LFU并不记录所有数据的访问历史,而只是记录过去一段时间内的访问历史,这就是Window的由来,基于这个原因,传统的LFU又被称为“Perfect-LFU”。
1.5.2. 实现
与LFU的实现基本相同,差别在于不需要记录所有数据的历史访问数据,而只记录过去一段时间内的访问历史。具体实现如下: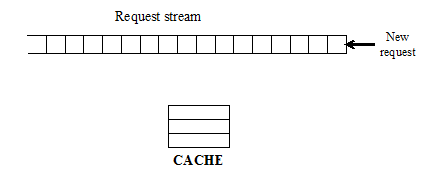
1)记录了过去W个访问记录;
2)需要淘汰时,将W个访问记录按照LFU规则排序淘汰
举例如下:
假设历史访问记录长度设为9,缓存大小为3,图中不同颜色代表针对不同数据块的访问,同一颜色代表针对同一数据的多次访问。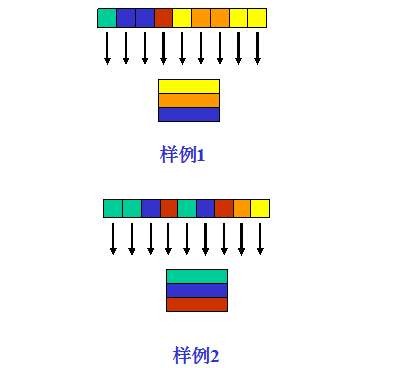
样例1:黄色访问3次,蓝色和橘色都是两次,橘色更新,因此缓存黄色、橘色、蓝色三个数据块
样例2:绿色访问3次,蓝色两次,暗红两次,蓝色更新,因此缓存绿色、蓝色、暗红三个数据块
1.5.3. 分析
l 命中率
Window-LFU的命中率和LFU类似,但Window-LFU会根据数据的访问模式而变化,能够更快的适应新的数据访问模式,”缓存污染“问题不严重。
l 复杂度
需要维护一个队列,记录数据的访问流历史;需要排序。
l 代价
Window-LFU只记录一部分的访问历史记录,不需要记录所有的数据访问历史,因此内存消耗和排序消耗都比LFU要低。
1.6. LFU类算法对比
由于不同的访问模型导致命中率变化较大,此处对比仅基于理论定性分析,不做定量分析。
|
对比点 |
对比 |
|
命中率 |
Window-LFU/LFU-Aging > LFU*-Aging > LFU > LFU* |
|
复杂度 |
LFU-Aging > LFU> LFU*-Aging >Window-LFU > LFU* |
|
代价 |
LFU-Aging > LFU > Window-LFU > LFU*-Aging > LFU* |
缓存淘汰算法之LFU的更多相关文章
- 常用缓存淘汰算法(LFU、LRU、ARC、FIFO、MRU)
缓存算法是指令的一个明细表,用于决定缓存系统中哪些数据应该被删去. 常见类型包括LFU.LRU.ARC.FIFO.MRU. 最不经常使用算法(LFU): 这个缓存算法使用一个计数器来记录条目被访问的频 ...
- 缓存淘汰算法(LFU、LRU、ARC、FIFO、MRU)分析
缓存算法是指令序列,用于决定缓存系统中哪些数据应该被删去. 常见类型包括LFU.LRU.ARC.FIFO.MRU. 一.最不经常使用算法(Least Frequently Used-LFU): 它是基 ...
- 图解缓存淘汰算法二之LFU
1.概念分析 LFU(Least Frequently Used)即最近最不常用.从名字上来分析,这是一个基于访问频率的算法.与LRU不同,LRU是基于时间的,会将时间上最不常访问的数据淘汰;LFU为 ...
- 昨天面试被问到的 缓存淘汰算法FIFO、LRU、LFU及Java实现
缓存淘汰算法 在高并发.高性能的质量要求不断提高时,我们首先会想到的就是利用缓存予以应对. 第一次请求时把计算好的结果存放在缓存中,下次遇到同样的请求时,把之前保存在缓存中的数据直接拿来使用. 但是, ...
- 04 | 链表(上):如何实现LRU缓存淘汰算法?
今天我们来聊聊“链表(Linked list)”这个数据结构.学习链表有什么用呢?为了回答这个问题,我们先来讨论一个经典的链表应用场景,那就是+LRU+缓存淘汰算法. 缓存是一种提高数据读取性能的技术 ...
- 数据结构与算法之美 06 | 链表(上)-如何实现LRU缓存淘汰算法
常见的缓存淘汰策略: 先进先出 FIFO 最少使用LFU(Least Frequently Used) 最近最少使用 LRU(Least Recently Used) 链表定义: 链表也是线性表的一种 ...
- 缓存淘汰算法之FIFO
前段时间去网易面试,被这个问题卡住,先做总结如下: 常用缓存淘汰算法 FIFO类:First In First Out,先进先出.判断被存储的时间,离目前最远的数据优先被淘汰. LRU类:Least ...
- 链表:如何实现LRU缓存淘汰算法?
缓存淘汰策略: FIFO:先入先出策略 LFU:最少使用策略 LRU:最近最少使用策略 链表的数据结构: 可以看到,数组需要连续的内存空间,当内存空间充足但不连续时,也会申请失败触发GC,链表则可 ...
- 《数据结构与算法之美》 <04>链表(上):如何实现LRU缓存淘汰算法?
今天我们来聊聊“链表(Linked list)”这个数据结构.学习链表有什么用呢?为了回答这个问题,我们先来讨论一个经典的链表应用场景,那就是 LRU 缓存淘汰算法. 缓存是一种提高数据读取性能的技术 ...
随机推荐
- JAVA加密解密DES对称加密算法
下面用DES对称加密算法(设定一个密钥,然后对所有的数据进行加密)来简单举个例子. 首先,生成一个密钥KEY. 我把它保存到key.txt中.这个文件就象是一把钥匙.谁拥有它,谁就能解开我们的类文件. ...
- 51nod 1489 蜥蜴和地下室
题目来源: CodeForces 基准时间限制:1 秒 空间限制:131072 KB 分值: 10 难度:2级算法题 哈利喜欢玩角色扮演的电脑游戏<蜥蜴和地下室>.此时,他正在扮演一个魔术 ...
- 2018.3.16 Ubuntu 解决中文乱码问题
一.乱码的样子类似: °²Àï¿ü ÒÁ¸ñÀ³Ï£ÑÇ˹,°²Àï¿ü ÒÁ¸ñÀ³Ï£ÑÇ˹ 这种乱码称为Gedit中文乱码 打开部分Windows下的txt文本文件的时候,中文显示为乱码.但 ...
- 单核CPU并发与非并发测试
多线程运行程序的目的一般是提高程序运行效率并且能够提高硬件的利用率比如多核CPU,但是如果我们只有单核CPU并发运行程序会怎样呢? 我以两个环境作为对比: 环境A(我本机8c) 环境B(我的云服务器1 ...
- centos7-httpd服务器
Apache WEB服务器入门简介: Apache HTTP Server是Apache软件基金会的一个开源的网页服务器,可以运行在几乎所有广泛使用的计算机平台上,由于其跨平台和安全性被广泛使用,是目 ...
- CPP-基础:类的静态成员
一 静态数据成员: 类体中的数据成员的声明前加上static关键字,该数据成员就成为了该类的静态数据成员.和其他数据成员一样,静态数据成员也遵守public/protected/private访问规 ...
- 剑指offer题目分类
1. 链表 1. 从尾到头打印链表 2. 链表中倒数第k个结点 3. 反转链表 4. 合并两个排序的链表 5. 复杂链表的复制 6. 复杂链表的复制 7. 两个链表的第一个公共结点 8. 链表中环的入 ...
- new和delete的动态分配。
c++对象模型 视频的实际操作 note: 1.虚函数有虚指针,所以是4,不管有几个虚函数, 都只有一个vptr来存放调用的虚函数的地址. 2.子类的内存是父类内存的加自己的数据内存. 3.clas ...
- cephfs 挂载 卸载
#挂载 sudo ceph-fuse -m 10.1.xx.231:6789,10.1.xx.232:6789,10.1.xx.233:6789 -r /MySQL-BK /data/backup # ...
- Docker自学纪实(一)Docker介绍
先简单了解一下,做个记录,以便不时之需. Docker简介:Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从Apache2.0协议开源. Docker 可以让开发者打包他们的应用以及依 ...