word2vec改进之Negative Sampling
训练网络时往往会对全部的神经元参数进行微调,从而让训练结果更加准确。但在这个网络中,训练参数很多,每次微调上百万的数据是很浪费计算资源的。那么Negative Sampling方法可以通过每次调整很小的一部分权重参数,从而代替全部参数微调的庞大计算量。
词典D中的词在语料C中出现的次数有高有低,对于那些高频词,我们希望它被选为负样本的概率比较大,对于那些低频词,我们希望它被选中的概率比较小,这是我们对于负采样过程的一个大致要求,本质上可以认为是一个带权采样的问题。
一、基于Negative Sampling的CBOW模型
输入:基于CBOW的语料训练样本,词向量的维度大小Mcount,CBOW的上下文大小2c,步长η, 负采样的个数neg
输出:词汇表每个词对应的模型参数θ,所有的词向量xw
1. 随机初始化所有的模型参数θ,所有的词向量w
2. 对于每个训练样本(context(w0),w0),负采样出neg个负例中心词wi,i=1,2,...neg
3. 进行梯度上升迭代过程,对于训练集中的每一个样本(context(w0),w0,w1,...wneg)做如下处理:

d) 如果梯度收敛,则结束梯度迭代,否则回到步骤3继续迭代。
二、基于Negative Sampling的Skip-Gram模型
输入:基于Skip-Gram的语料训练样本,词向量的维度大小Mcount,Skip-Gram的上下文大小2c,步长η, , 负采样的个数neg。
输出:词汇表每个词对应的模型参数θ,所有的词向量xw
1. 随机初始化所有的模型参数θ,所有的词向量w
2. 对于每个训练样本(context(w0),w0),负采样出neg个负例中心词wi,i=1,2,...neg
3. 进行梯度上升迭代过程,对于训练集中的每一个样本(context(w0),w0,w1,...wneg)做如下处理:
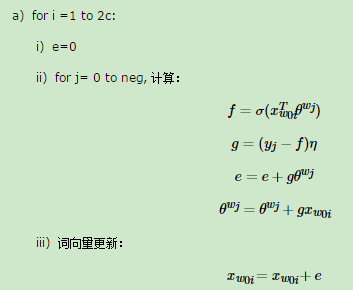
b)如果梯度收敛,则结束梯度迭代,算法结束,否则回到步骤a继续迭代。
参考内容:
https://www.cnblogs.com/pinard/p/7249903.html
word2vec改进之Negative Sampling的更多相关文章
- word2vec原理(三) 基于Negative Sampling的模型
word2vec原理(一) CBOW与Skip-Gram模型基础 word2vec原理(二) 基于Hierarchical Softmax的模型 word2vec原理(三) 基于Negative Sa ...
- word2vec 中的数学原理具体解释(五)基于 Negative Sampling 的模型
word2vec 是 Google 于 2013 年开源推出的一个用于获取 word vector 的工具包,它简单.高效,因此引起了非常多人的关注. 因为 word2vec 的作者 Tomas ...
- DL4NLP——词表示模型(三)word2vec(CBOW/Skip-gram)的加速:Hierarchical Softmax与Negative Sampling
上篇博文提到,原始的CBOW / Skip-gram模型虽然去掉了NPLM中的隐藏层从而减少了耗时,但由于输出层仍然是softmax(),所以实际上依然“impractical”.所以接下来就介绍一下 ...
- 词表征 2:word2vec、CBoW、Skip-Gram、Negative Sampling、Hierarchical Softmax
原文地址:https://www.jianshu.com/p/5a896955abf0 2)基于迭代的方法直接学 相较于基于SVD的方法直接捕获所有共现值的做法,基于迭代的方法一次只捕获一个窗口内的词 ...
- Notes on Noise Contrastive Estimation and Negative Sampling
Notes on Noise Contrastive Estimation and Negative Sampling ## 生成负样本 在常见的关系抽取应用中,我们经常需要生成负样本来训练一个好的系 ...
- 论文解读(SelfGNN)《Self-supervised Graph Neural Networks without explicit negative sampling》
论文信息 论文标题:Self-supervised Graph Neural Networks without explicit negative sampling论文作者:Zekarias T. K ...
- [DeeplearningAI笔记]序列模型2.7负采样Negative sampling
5.2自然语言处理 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.7 负采样 Negative sampling Mikolov T, Sutskever I, Chen K, et a ...
- word2vec改进之Hierarchical Softmax
首先Hierarchical Softmax是word2vec的一种改进方式,因为传统的word2vec需要巨大的计算量,所以该方法主要有两个改进点: 1. 对于从输入层到隐藏层的映射,没有采取神经网 ...
- 【计算语言学实验】基于 Skip-Gram with Negative Sampling (SGNS) 的汉语词向量学习和评估
一.概述 训练语料来源:维基媒体 https://dumps.wikimedia.org/backup-index.html 汉语数据 用word2vec训练词向量,并用所学得的词向量,计算 pku_ ...
随机推荐
- Post Man 调用CRMAPI
官方文档 https://docs.microsoft.com/en-us/dynamics365/customer-engagement/developer/webapi/setup-postman ...
- java中如何创建带路径的文件
请教各位大侠了,java中如何创建带路径的文件,说明下 这个路径不存在 ------回答--------- ------其他回答(2分)--------- Java code File f = new ...
- java后台获取cookie里面值得方法
String admissionNo = ""; //得到所有的cookies Cookie[] cookies = this.getRequest().getCookies(); ...
- UITabBar 设置选中、未选中状态下title的字体颜色
一.如果只是设置选中状态的字体颜色,使用 tintColor 就可以达到效果 self.tabBar.tintColor = [UIColor redColor]; 二.但如果要将未选中状态和选中状 ...
- Yii的缓存机制之页面缓存
页面缓存是不能通过片段缓存来实现的,因为布局和内容不能同时缓存.只能通过过滤器来生成缓存. 实现方法: 在控制器里使用过滤器来实现 function filters (){ return array( ...
- gitblit安装使用
1.下载地址 http://www.gitblit.com/ 2.安装jdk(自行安装) 3.解压gitblit # tar -zxvf gitblit-1.8.0.tar.gz 4.配置# cd g ...
- 关于Spring MVC分页
使用Pageable接口,首先要实例化. 在servlet-context.xml中配置 <annotation-driven> <!-- 分页参数 --> <argum ...
- PS 图像滤镜— — USM 锐化
这个算法的原理很简单,就是先用高斯模糊获取图像的低频信息,然后用原图减去高斯模糊之后的图,得到图像的高频信息,再将原图与高频信息融合,进一步增强原图的高频信息,看起来,图像的边缘显得特别的sharp. ...
- POJ1236 Network of Schools (强连通分量,注意边界)
A number of schools are connected to a computer network. Agreements have been developed among those ...
- 「LOJ#10043」「一本通 2.2 例 1」剪花布条 (KMP
题目描述 原题来自:HDU 2087 一块花布条,里面有些图案,另有一块直接可用的小饰条,里面也有一些图案.对于给定的花布条和小饰条,计算一下能从花布条中尽可能剪出几块小饰条来呢? 输入格式 输入数据 ...