使用LAP数据集进行年龄训练及估计
一、背景
原本是打算按《DEX Deep EXpectation of apparent age from a single image》进行表面年龄的训练,可由于IMDB-WIKI的数据集比较庞大,各个年龄段分布不均匀,难以划分训练集及验证集。后来为了先跑通整个训练过程的主要部分,就直接用LAP数据集,参考caffe的finetune_flickr_style,进行一些参数修改,利用bvlc_reference_caffenet.caffemodel完成年龄估计的finetune。
二、训练数据集准备
1、下载LAP数据集,包括Train、Validation、Test,以及对应的年龄label,http://chalearnlap.cvc.uab.es/dataset/18/description/,需要注册。也可以从我的网盘下载:
链接:https://pan.baidu.com/s/1536TgbR_cCcS7-QHfEAeMw
提取码:xc45
2、将标注好的csv文件转换为caffe识别的txt格式。csv每一行的信息为:图片名、年龄、标准差。训练的时候不需要标准差信息,我们只要将图片名和年龄写入到txt中,并按空格隔开,得到Train.txt如下:
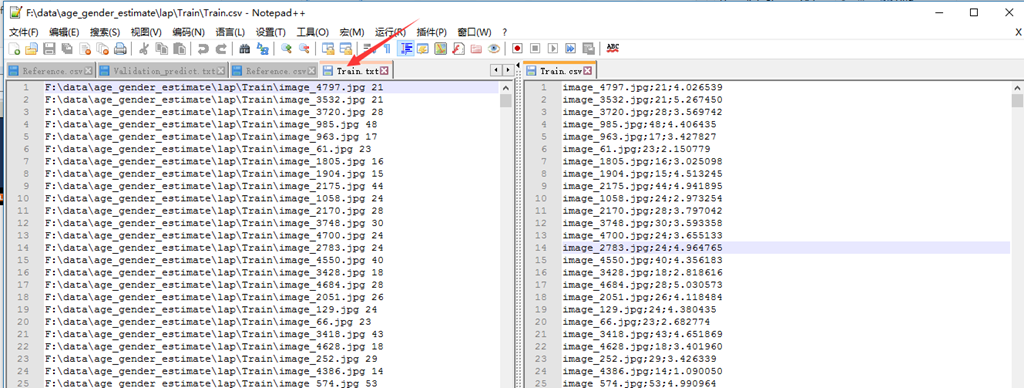
同样,完成验证集cvs文件的转换,得到Validation.txt。
三、模型及相关文件拷贝
1、拷贝预训练好的vgg16模型caffe\models\bvlc_reference_caffenet\bvlc_reference_caffenet.caffemodel至工作目录下,该文件约232M;
2、拷贝caffe\models\finetune_flickr_style文件夹中deploy.prototxt、solver.prototxt、train_val.prototxt至工作目录下;
3、拷贝imageNet的均值文件caffe\data\ilsvrc12\imagenet_mean.binaryproto至工作目录下。
四、参数修改
1、修改train_val.prototxt
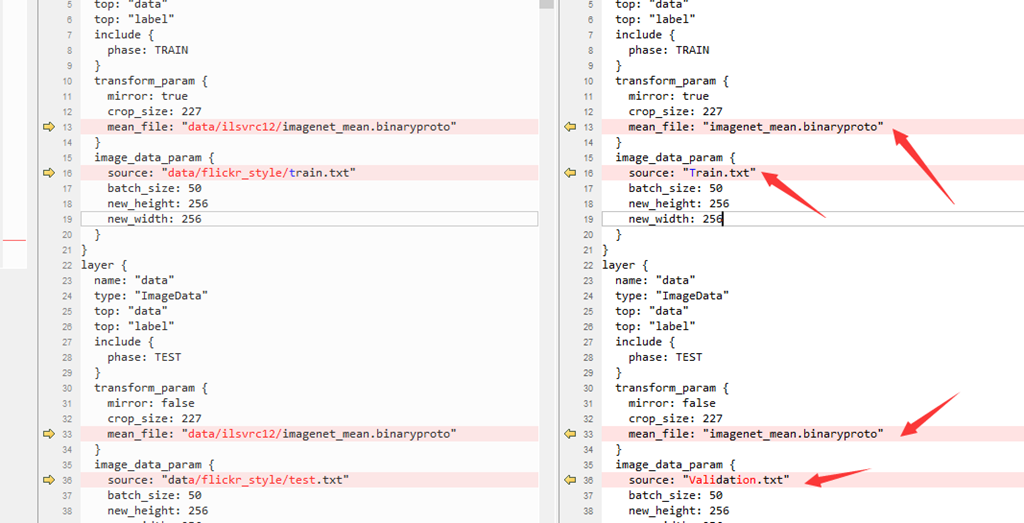
以及最后的输出层个数,因为我们要训练的为[0,100]岁的输出,共101类,所以:

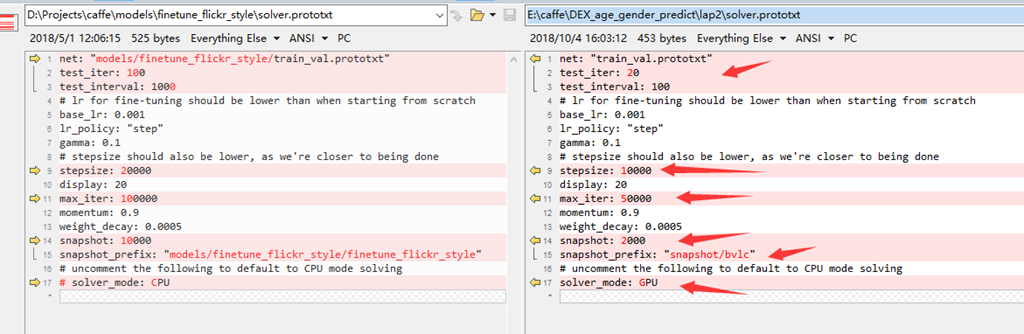
2、修改solver.protxt
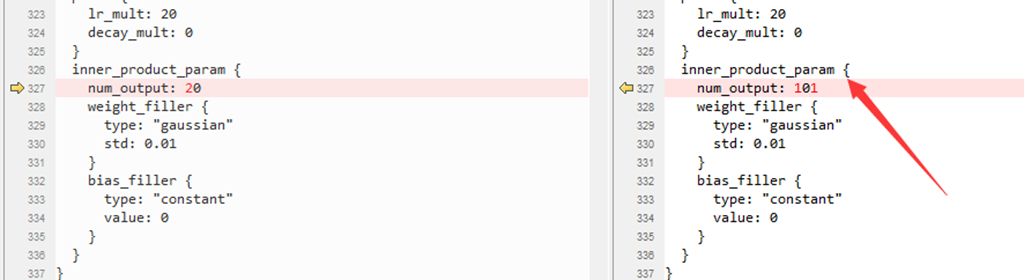
3、修改用于实际测试的部署文件deploy.protxt

输出层的个数也要改:
五、开始训练
1、新建train.bat
caffe train -solver solver.prototxt -weights bvlc_reference_caffenet.caffemodel
rem caffe train --solver solver.prototxt --snapshot snapshot/bvlc_iter_48000.solverstate
pause
双击即可开始训练,当训练过程中出现意外中断,可注释第一行,关闭第二行注释,根据实际情况修改保存,继续双击训练。
我的电脑CPU是i5 6500,显卡为gtx1050Ti,8G内存,大致要训练10个小时吧,中途也出现了一些内存不足训练终止的情况。
2、训练结束
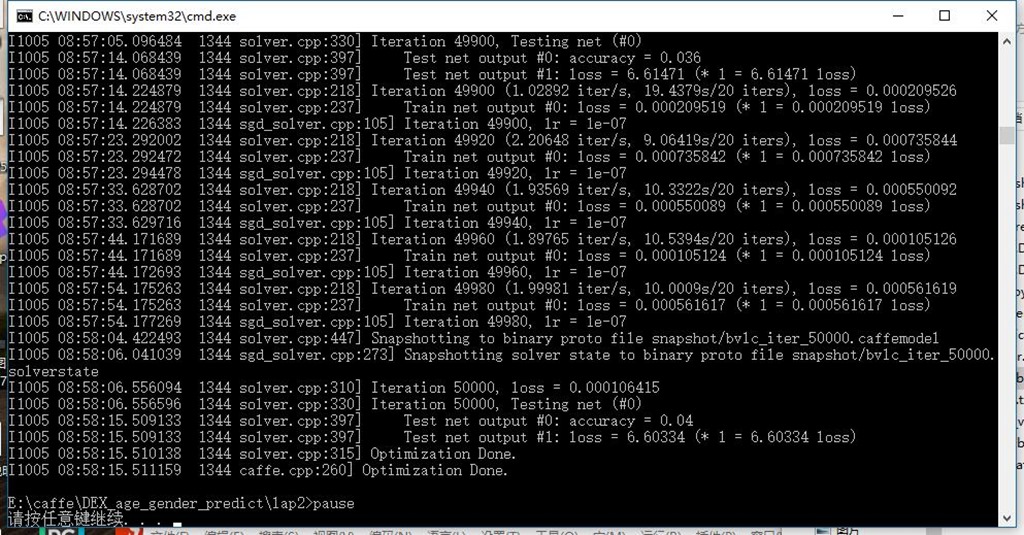
六、模型评价
年龄估计原本是一个线性问题,不是一个明确的分类问题,人都无法准确无误地得到某人的年龄,更何况是机器呢。所以评价这个年龄分类模型的好坏不能简单地通过精度来衡量,可以用MAE(平均绝对误差)以及ε-error来衡量,其中
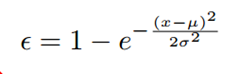
1、对验证集Validation.txt的所有图片进行预测
借助 https://github.com/eveningglow/age-and-gender-classification ,其环境搭建可参考https://www.cnblogs.com/smbx-ztbz/p/9399016.html
修改main函数
int split(std::string str, std::string pattern, std::vector<std::string> &words)
{
std::string::size_type pos;
std::string word;
int num = ;
str += pattern;
std::string::size_type size = str.size();
for (auto i = ; i < size; i++) {
pos = str.find(pattern, i);
if (pos == i) {
continue;//if first string is pattern
}
if (pos < size) {
word = str.substr(i, pos - i);
words.push_back(word);
i = pos + pattern.size() - ;
num++;
}
}
return num;
} //param example: model/deploy_age2.prototxt model/age_net.caffemodel model/mean.binaryproto img/0008.jpg
int main(int argc, char* argv[])
{
if (argc != )
{
cout << "Command shoud be like ..." << endl;
cout << "AgeAndGenderClassification ";
cout << " \"AGE_NET_MODEL_FILE_PATH\" \"AGE_NET_WEIGHT_FILE_PATH\" \"MEAN_FILE_PATH\" \"TEST_IMAGE\" " << endl;
std::cout << "argc = " << argc << std::endl;
getchar();
return ;
} // Get each file path
string age_model(argv[]);
string age_weight(argv[]);
string mean_file(argv[]);
//string test_image(argv[4]); // Probability vector
vector<Dtype> prob_age_vec; // Set mode
Caffe::set_mode(Caffe::GPU); // Make AgeNet
AgeNet age_net(age_model, age_weight, mean_file); // Initiailize both nets
age_net.initNetwork(); //读取待测试的图片名
std::ifstream fin("E:\\caffe\\DEX_age_gender_predict\\lap2\\Validation.txt");
std::string line;
std::vector<std::string> test_images;
std::vector<int> test_images_age;
while (!fin.eof()) {
std::getline(fin, line);
std::vector<std::string> words;
split(line, " ", words);
test_images.push_back(words[]);
test_images_age.push_back(atoi(words[].c_str()));
}
std::cout << "test_images size = " << test_images.size() << std::endl; std::ofstream fout("E:\\caffe\\DEX_age_gender_predict\\lap2\\Validation_predict.txt");
for (int k = ; k < test_images.size(); ++k) {
std::cout << "k = " << k << std::endl;
std::string test_image;
test_image = test_images[k]; // Classify and get probabilities
Mat test_img = imread(test_image, CV_LOAD_IMAGE_COLOR);
int age = age_net.classify(test_img, prob_age_vec); // Print result and show image
//std::cout << "prob_age_vec size = " << prob_age_vec.size() << std::endl;
//for (int i = 0; i < prob_age_vec.size(); ++i) {
// std::cout << "[" << i << "] = " << prob_age_vec[i] << std::endl;
//} //Dtype prob;
//int index;
//get_max_value(prob_age_vec, prob, index);
//std::cout << "prob = " << prob << ", index = " << index << std::endl; //imshow("AgeAndGender", test_img);
//waitKey(0);
fout << test_images[k] << " " << test_images_age[k] << " " << age << std::endl; } std::cout << "finish!" << std::endl;
getchar();
return ;
}
我的命令参数为:E:\caffe\DEX_age_gender_predict\lap2\deploy.prototxt E:\caffe\DEX_age_gender_predict\lap2\snapshot\bvlc_iter_50000.caffemodel model\mean.binaryproto img\0008.jpg
可根据实际情况修改。可得到Validation_predict.txt文件。运行过程中可能会因为内存不足中断运行,可能要分批次运行多次。
2、计算MAE及ε-error
(1)将Validation_predict.txt文件及验证集的标注文件Reference.csv拷贝到新建的vs项目的工作目录下;
(2)计算
#include <iostream>
#include <string>
#include <fstream>
#include <vector> int split(std::string str, std::string pattern, std::vector<std::string> &words)
{
std::string::size_type pos;
std::string word;
int num = ;
str += pattern;
std::string::size_type size = str.size();
for (auto i = ; i < size; i++) {
pos = str.find(pattern, i);
if (pos == i) {
continue;//if first string is pattern
}
if (pos < size) {
word = str.substr(i, pos - i);
words.push_back(word);
i = pos + pattern.size() - ;
num++;
}
}
return num;
} int main(int argc, char** argv)
{
//u, sigma, x
std::vector<int> u;
std::vector<float> sigma;
std::vector<int> predict; std::string line;
std::ifstream csv_file("Reference.csv");
while (!csv_file.eof()) {
std::getline(csv_file, line);
std::vector<std::string> words;
split(line, ";", words);
u.push_back(atoi(words[].c_str()));
sigma.push_back(atof(words[].c_str()));
}
std::ifstream predict_file("Validation_predict.txt");
while (!predict_file.eof()) {
std::getline(predict_file, line);
std::vector<std::string> words;
split(line, " ", words);
predict.push_back(atoi(words[].c_str()));
}
if (u.size() != predict.size()) {
std::cout << "u.size() != predict.size()" << std::endl;
getchar();
return -;
} //MAE
int sum_err = ;
float MAE = ;
for (int i = ; i < u.size(); ++i) {
sum_err += abs(u[i] - predict[i]);
}
MAE = static_cast<float>(sum_err) / u.size();
std::cout << "MAE = " << MAE << std::endl;//11.7184 //esro-error
std::vector<float> errors;
float err = ;
float error = 0.0;
for (int i = ; i < u.size(); ++i) {
err = 1.0 - exp(-1.0*(predict[i] - u[i])*(predict[i] - u[i]) / ( * sigma[i] * sigma[i]));
errors.push_back(err);
error += err;
}
error /= errors.size();
std::cout << "error = " << error << std::endl;//0.682652 std::cout << "finish!" << std::endl;
getchar();
return ;
}
最终得到MAE为11.7184, ε-error为0.682652。
七、实际应用中预测
1、可利用caffe提供的classification工具对输入图片地进行估计
classification deploy.prototxt snapshot\bvlc_iter_50000.caffemodel imagenet_mean.binaryproto ..\age_labels.txt ..\test_image\test_3.jpg
pause
其中,age_labels.txt为0-100个label的说明信息,每个label对应一行,共101行,我的写法如下:
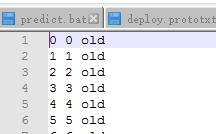
end
使用LAP数据集进行年龄训练及估计的更多相关文章
- 【猫狗数据集】pytorch训练猫狗数据集之创建数据集
猫狗数据集的分为训练集25000张,在训练集中猫和狗的图像是混在一起的,pytorch读取数据集有两种方式,第一种方式是将不同类别的图片放于其对应的类文件夹中,另一种是实现读取数据集类,该类继承tor ...
- Fast RCNN 训练自己的数据集(3训练和检测)
转载请注明出处,楼燚(yì)航的blog,http://www.cnblogs.com/louyihang-loves-baiyan/ https://github.com/YihangLou/fas ...
- YOLO 从数据集制作到训练
1.图片数据集收集 共 16种 集装箱船 container ship 散货船 bulker 油船 tanker 游轮 / 客轮 / 邮轮 passenger liner 渔船 fishing boa ...
- 基于MNIST数据集使用TensorFlow训练一个包含一个隐含层的全连接神经网络
包含一个隐含层的全连接神经网络结构如下: 包含一个隐含层的神经网络结构图 以MNIST数据集为例,以上结构的神经网络训练如下: #coding=utf-8 from tensorflow.exampl ...
- 基于MNIST数据集使用TensorFlow训练一个没有隐含层的浅层神经网络
基础 在参考①中我们详细介绍了没有隐含层的神经网络结构,该神经网络只有输入层和输出层,并且输入层和输出层是通过全连接方式进行连接的.具体结构如下: 我们用此网络结构基于MNIST数据集(参考②)进行训 ...
- CNN实现terecord、数据集、模型训练
AlexNet(Alex Krizhevsky,ILSVRC2012冠军)适合做图像分类.层自左向右.自上向下读取,关联层分为一组,高度.宽度减小,深度增加.深度增加减少网络计算量. 训练模型数据集 ...
- openface 训练数据集
训练深度网络模型OpenFace还不是运用faceNet的model作为训练模型,所以在准确性上比faceNet要低,如果你只是做一个简单的分类,建议你看看官网的demo3(http://cmusat ...
- 十折交叉验证10-fold cross validation, 数据集划分 训练集 验证集 测试集
机器学习 数据挖掘 数据集划分 训练集 验证集 测试集 Q:如何将数据集划分为测试数据集和训练数据集? A:three ways: 1.像sklearn一样,提供一个将数据集切分成训练集和测试集的函数 ...
- mask_rcnn训练自己的数据集
1.首先从官方下载mask_rcnn源码https://github.com/matterport/Mask_RCNN 2.首先将demo.ipynb转换成demo.py,这里我顺便更改为适用于我自己 ...
随机推荐
- Vue语法学习第一课——插值
学习关于Vue的插值语法 ① 文本值 : "Mustache"语法,即双大括号 <span>Message:{{msg}}</span> 注:双大括号中的m ...
- Windows7上安装Ubuntu双系统
零.前言 最近不小心把Ubuntu系统搞崩了打不开了,在网上找了找方法,从最初的步骤开始安装,本文是安装Ubuntu16.04,不过安装啥版本步骤都一样,下面逐一介绍. 一.如何卸载Ubuntu(第一 ...
- spring cloud config git库文件搜索顺序
spring.cloud.config.server.git.uri只配置到仓库那一层就行了,需要访问仓库的子目录的话就配置spring.cloud.config.server.git.searchP ...
- vsftpd 的端口模式以及端口映射问题
开个blog ,写一下关于vsftp 端口映射的一些坑 内容繁多,改日再更.
- JAVAEE期末项目------文章发布系统
项目文档和代码的GitHub地址:https://github.com/xiangbaobaojojo/- 1.项目介绍 (计科四班 蔡春燕 20150141401)和我 陈香宇(计科四班 201 ...
- 单链表sLinkList类,模板类
sLinkList模板类,单链表代码 /* 该文件按习惯可以分成.h文件和实现的.cpp文件 */ template <class elemType> class sLinkList { ...
- css中换行与不换行的样式
常见的css样式分为换行与不换行两种需求 1.不换行显示省略号 text-overflow:ellipsis; white-space:normal; 2.换行自适应 word-break: brea ...
- Vue-cli里面引用stylus遇到的问题总结
1.stylus的调用 在vue-cli中用到stylus样式处理器的时候一定要引用两个对应的报stylus stylus-loader 命令:cnpm install stylus stylus- ...
- 运动控制之一_PID控制理论
PID算法是早期发展起来的控制算法,该算法因其简单.鲁棒性强且可靠性高而被广泛地应用于过程控制和运动控制中. 常规的PID控制系统原理框图如下所示: PID控制系统原理图 误差信号Err(t)输入到控 ...
- MS SQL 全局临时表的删除
本来已经搜索到怎么删除了 如下: IF OBJECT_ID( 'tempdb..##TEMP_COPTD') IS NOT NULL Begin DROP TABLE ##TEMP_COPTD End ...