爬虫实例系列一(requests)
一 爬虫简介
'''
爬虫:通过编写程序,模拟浏览器上网,让其去互联网上爬取数据的过程 分类:
通用爬虫:爬取全部的页面数据
聚焦爬虫:抓取页面中局部数据
增量式爬虫:爬取网站中更新出的数据 反爬机制:门户网站会通过制定相关的技术手段,组织爬虫程序进行数据获取
反反爬策略:针对反爬机制制定的策略,为了获取数据 第一个反爬机制:
robots.txt协议:防君子不防小人的协议
'''
二 request 入门使用流程
'''
request使用流程:
- 制定url
- 发起请求
- 获取响应回来的页面数据
- 持久化存储
'''
三 实例
1 获取搜狗页面(反反爬机制:防君子不防小人)
import requests #获取搜狗页面数据 #1.指定url
url='https://www.sogo.com/' #2.发起请求
response=requests.get(url=url) #3.获取页面数据
response_text=response.text #4.持久化存储
with open('sogo.html',mode='w',encoding='utf8') as f:
f.write(response_text)
2 获取知乎页面数据(UA伪装)
'''
User-Agent:请求载体的身份标识
反爬机制:UA检测
反反爬策略:UA伪装
'''
#请求知乎 url='https://www.zhihu.com/' #指定请求头,进行UA伪装
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.20 Safari/537.36'
}
response=requests.get(url=url,headers=headers) print(response.text)
3 post请求实例(请求百度翻译结果)

#请求百度翻译结果 #经过分析发现,百度翻译发送的请求是ajax请求
import requests url='https://fanyi.baidu.com/sug' #指定请求头,进行UA伪装
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.20 Safari/537.36'
} #搜索数据不要写死 kw=input('input a word:')
#构建请求数据
data={
'kw':kw
} response=requests.post(url=url,headers=headers,data=data) print(response.json())
4 post 请求携带更多参数data={}
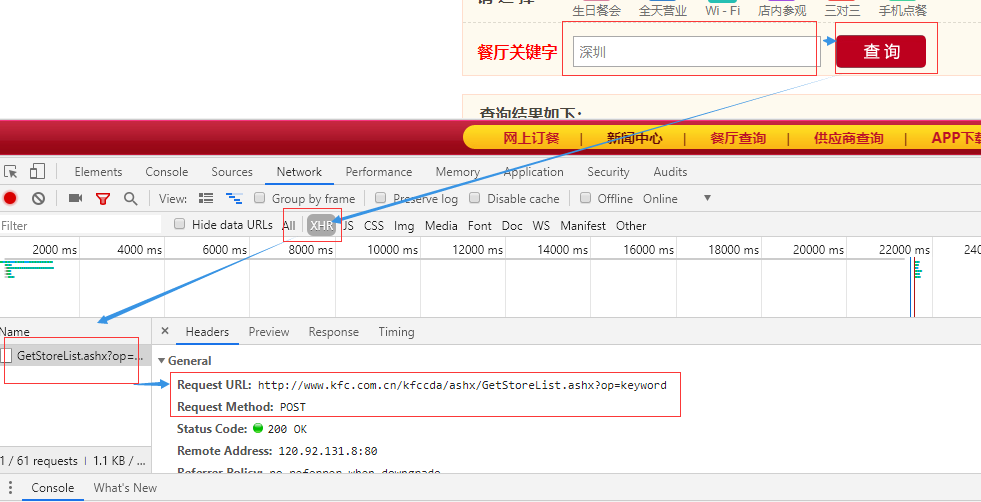

#爬取城市肯德基餐厅的位置信息 http://www.kfc.com.cn/kfccda/storelist/index.aspx '''
抓包获取的数据
Request URL: http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword
Request Method: POST
Status Code: 200 OK
Remote Address: 120.92.131.8:80
Referrer Policy: no-referrer-when-downgrade
''' import requests url='http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword' headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.20 Safari/537.36'
} data={
'cname':'',
'pid':'',
'keyword': '深圳',
'pageIndex': 3,
'pageSize': 10,
} response=requests.post(url=url,headers=headers,data=data) print(response.json())
5 爬取豆瓣电影中的详细数据(ajax请求)
import requests
#爬取豆瓣电影中的详细数据(ajax请求)
#'https://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action=&start=20&limit=20'
url='https://movie.douban.com/j/chart/top_list'
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.20 Safari/537.36'
}
#此处参数已经写死,后续项目中在此基础修改
params={
'type': '',
'interval_id': '100:90',
'action':'',
'start':'',
'limit':'',
}
response=requests.get(url=url,headers=headers,params=params)
print(response.json())
爬虫实例系列一(requests)的更多相关文章
- 爬虫实例之使用requests和Beautifusoup爬取糗百热门用户信息
这次主要用requests库和Beautifusoup库来实现对糗百的热门帖子的用户信息的收集,由于糗百的反爬虫不是很严格,也不需要先登录才能获取数据,所以较简单. 思路,先请求首页的热门帖子获得用户 ...
- 爬虫入门系列(二):优雅的HTTP库requests
在系列文章的第一篇中介绍了 HTTP 协议,Python 提供了很多模块来基于 HTTP 协议的网络编程,urllib.urllib2.urllib3.httplib.httplib2,都是和 HTT ...
- 爬虫入门系列(三):用 requests 构建知乎 API
爬虫入门系列目录: 爬虫入门系列(一):快速理解HTTP协议 爬虫入门系列(二):优雅的HTTP库requests 爬虫入门系列(三):用 requests 构建知乎 API 在爬虫系列文章 优雅的H ...
- 爬虫系列(七) requests的基本使用
一.requests 简介 requests 是一个功能强大.简单易用的 HTTP 请求库,可以使用 pip install requests 命令进行安装 下面我们将会介绍 requests 中常用 ...
- python爬虫学习(6) —— 神器 Requests
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 模块提供了你所需要的大多数 H ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- [python爬虫]Requests-BeautifulSoup-Re库方案--Requests库介绍
[根据北京理工大学嵩天老师“Python网络爬虫与信息提取”慕课课程编写 文章中部分图片来自老师PPT 慕课链接:https://www.icourse163.org/learn/BIT-10018 ...
随机推荐
- 当子查询内存在ORDER BY 字句时查询会报错
问题:当子查询内存在ORDER BY 字句时查询会报错 SQL: SELECT * FROM ( SELECT * FROM USER ORDER BY USER_CORD ) S. 解决办法:在子查 ...
- Linux学习笔记(一):常用命令(1)
经过统计Linux中能够识别的命令超过3000种,当然常用的命令就远远没有这么多了,按照我的习惯,我把已经学过的Linux常用命令做了以下几个方面的分割: 1.文件处理命令 2.文件搜索命令 3.帮助 ...
- 漫画:全面理解java.lang.IllegalArgumentException及其可用性设计
经过一段时间的学习与实践,飞鸟已经可以独力解决一些问题.小鱼就让飞鸟讲述一些遇到的问题和解决过程. 报错日志: 这个产生的原因是我覆盖Collections.sort的Comparator方法的时候 ...
- python操作符笔记
1.**两个乘号就是乘方,比如2**4,结果就是2的4次方,结果是16 2.//就是做浮点除法,并舍弃小数部分(注意不是四舍五入) 3.@是python中的修饰符,具体功能我没弄懂.
- Linux下编译器的安装
一.Linux下gcc/g++/gfortran的安装 (1).gcc Linux下自带gcc编译器.可以通过“gcc -v”命令来查看是否安装. (2).g++安装g++编译器,可以通过命令“sud ...
- 痞子衡嵌入式:第一本Git命令教程(5)- 提交(commit/format-patch/am)
今天是Git系列课程第五课,上一课我们做了Git本地提交前的准备工作,今天痞子衡要讲的是Git本地提交操作. 当我们在仓库工作区下完成了文件增删改操作之后,并且使用git add将文件改动记录在暂存区 ...
- Centos7-yum部署配置LAMP-之LAMP及php-fpm实现反代动态资源
一.简介 LAMP:linux+apache+mysql(这里用mariadb)+php(perl,python) LAMMP:memcached缓存的 CGI:Common Gateway Inte ...
- [MySQL] 5.7版本以上group by语句报1055错误问题
1. 在5.7版本以上mysql中使用group by语句进行分组时, 如果select的字段 , 不是完全对应的group by后面的字段 , 有其他字段 , 那么就会报这个错误 ERROR 105 ...
- 讲讲跳跃表(Skip Lists)
跳跃表(Skip Lists)是一种有序的数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的.在大部分情况下,跳跃表的效率可以和平衡树相媲美,并且在实现上比平衡树要更为 ...
- vue 组件通信
组件 组件之间的数据是单向绑定的. 父组件向子组件通信 是通过子组件定义的props属性来实现.通过props定义变量与变量类型和验证方式. props简化定义 在简化定义中,变量是以数组的方式定义. ...