单机部署 ELK
对于一个体量不大的系统,运行在单机上的 ELK 就足以胜任日志的处理任务了。本文介绍如何在单台服务器上安装并配置 ELK(elalasticsearch + logstash + kibana),并最终通过 filebeat 把日志数据发送给日志服务器(ELK)。整体的架构如下图所示(此图来自互联网):
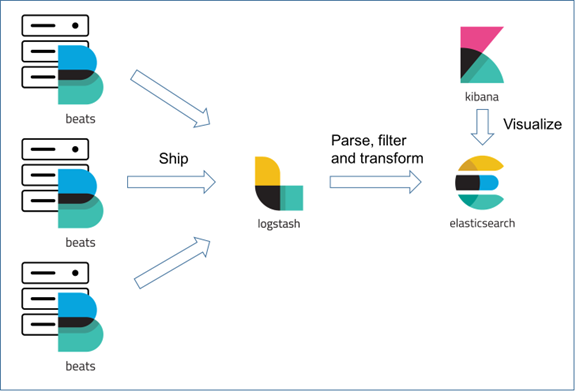
本文的演示环境为 Ubuntu Server 18.04,ELK 和 filebeat 的版本都是 6.2.4。
安装 java 运行时
我们假设您已经有一台运行 Ubuntu Server 18.04 的主机了,所以安装步骤从 java 运行时开始。必须安装 java 运行时是因为 elasticsearch 和 logstash 都是 Java 程序。下面的命令安装 openjdk8:
$ apt update
$ apt install -y openjdk--jre-headless
安装完成后检查一下安装结果:
$ java -version

安装 elasticsearch
可以通过下面的命令安装 elasticsearch 6.2.4:
$ wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
$ sudo echo "deb https://artifacts.elastic.co/packages/6.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-.x.list
$ sudo apt update
$ sudo apt install -y elasticsearch=6.2.
$ sudo systemctl daemon-reload
$ sudo systemctl enable elasticsearch.service
安装 kibana
可以通过下面的命令安装 kibana 6.2.4:
$ wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
$ sudo echo "deb https://artifacts.elastic.co/packages/6.x/apt stable main" | tee -a /etc/apt/sources.list.d/elastic-.x.list
$ sudo apt update
$ sudo apt install -y kibana=6.2.
$ sudo systemctl daemon-reload
$ sudo systemctl enable kibana.service
安装 logstash
笔者在通过上面的方式安装 logstash 6.2.4 的时候发生了错误,说是找不到 logstash 6.2.4:

所以直接从官网下载了 6.2.4 的安装包通过下面的命令进行本地安装:
$ sudo apt install ./logstash-6.2..deb $ sudo systemctl daemon-reload
$ sudo systemctl enable logstash.service
完整的安装脚本
可以通过下面的脚本一次完成 elasticsearch、kibana 和 logstash 的安装:
#!/bin/bash
# sudo ./installelk6.2.4.u1804.sh apt update
apt install -y openjdk--jre-headless
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | apt-key add -
echo "deb https://artifacts.elastic.co/packages/6.x/apt stable main" | tee -a /etc/apt/sources.list.d/elastic-.x.list apt update apt install -y elasticsearch=6.2.
apt install -y kibana=6.2.
apt install -y ./logstash-6.2..deb systemctl daemon-reload
systemctl enable elasticsearch.service
systemctl enable logstash.service
systemctl enable kibana.service
把上面的内容保存在 installelk6.2.4.u1804.sh 文件中,和下载的 logstash-6.2.4.deb 文件放在同一个目录下,并进入到该目录中,执行下面的命令进行安装:
$ chomd +x installelk6.2.4.u1804.sh
$ sudo ./installelk6.2.4.u1804.sh
为 elasticsearch 挂载一个大磁盘
elasticsearch 需要大容量的存储设备来保存日志数据,所以我们这里单独添加一块 1T 的磁盘来保存日志数据。
先在系统的根目录下创建 esdata 目录作为磁盘的挂载点,elasticsearch 中的数据和自身的日志将会保存到这个目录中:
$ sudo mkdir /esdata
我们添加的磁盘的文件设备名称为 /dev/sdb,下面就把磁盘挂载到 /esdata 目录。
先使用 fdisk 命令对磁盘进行分区:
$ (echo n; echo p; echo ; echo ; echo ; echo w) | sudo fdisk /dev/sdb
然后使用 mkfs 命令将文件系统写入分区:
$ sudo mkfs -t ext4 /dev/sdb1
最后把新的磁盘分区挂载到 /esdata 装载新磁盘使其在操作系统中可访问:
$ sudo mount /dev/sdb1 /esdata
查看挂载完成后的文件系统:
$ df -h

接下来设置 elasticsearch 用户作为该目录的所有者,这样就 elasticsearch 就能往目录下写文件了:
$ sudo chown elasticsearch:elasticsearch /esdata
$ sudo chmod /esdata
设置开机自动挂载
现在挂载的文件系统 /esdata 会在系统重启后丢掉,因此需要设置在开机时自动挂载这个文件系统。先通过下面的命令找到设备的 UUID:
$sudo -i blkid
输出的内容为类似于下面的一些行,其中的 UUID 是我们需要的:
/dev/sdb1: UUID="db048fa3-903b-4b85-a7ab-01c920283eeb" TYPE="ext4" PARTUUID="b0261bed-01"
在 /etc/fstab 文件中添加类似于以下内容的行,其中的 UUID 就是从上面得来的:
UUID=db048fa3-903b-4b85-a7ab-01c920283eeb /esdata ext4 defaults,nofail,barrier=
这样的设置完成后,文件系统会在开机时自动挂载。
修改 elasticsearch 数据和日志文件的存储位置
在 /etc/elasticsearch/elasticsearch.yml 文件中找 path.data 和 path.logs 的设置,并修改如下:
# ----------------------------------- Paths ------------------------------------
# Path to directory where to store the data (separate multiple locations by comma):
path.data: /esdata
#
# Path to log files:
path.logs: /esdata
配置 kibana
kibana 服务默认监听的端口号修为 5601,但是默认只有在本机才能访问!
要取消对访问者 IP 地址的限制,需要修改配置文件 /etc/kibana/kibana.yml 中的 server.host,把默认值 localhost 改为 0.0.0.0:
#server.host: "localhost"
server.host: "0.0.0.0"
配置 logstash
logstash 的配置文件为 /etc/logstash/logstash.yml 默认不需要修改。在 /etc/logstash/conf.d 目录下添加配置文件 beat2es.conf,内容如下:
input{
beats{
port =>
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "beat-test-%{+YYYY.MM.dd}"
sniffing => true
template_overwrite => true
}
}
该配置会让 logstash 服务监听 5044 端口接收数据:
*:
到此为止,我们已经完成了 elasticsearch、kibana 和 logstash 的安装和配置,下面启动这些服务:
$ sudo systemctl start elasticsearch.service
$ sudo systemctl start kibana.service
$ sudo systemctl start logstash.service
安装 filebeat
假设我们也在 Ubuntu Server 18.04 的环境中安装 filebeat 6.2.4。先从官网下载 filebeat 6.2.4 deb 包,或者直接运行下面的命令进行安装:
$ curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.2.4-amd64.deb
$ sudo dpkg -i ./filebeat-6.2.-amd64.deb
$ sudo systemctl daemon-reload
$ sudo systemctl enable filebeat.service
验证安装:
$ filebeat version
filebeat version 6.2. (amd64), libbeat 6.2.
配置 filebeat
配置 filebeat 从文件收集日志
编辑配置文件 /etc/filebeat/filebeat.yml,在 filebeat.prospectors 段修改 type 为 log 中的内容:
- type: log
# Change to true to enable this prospector configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /home/nick/work/test.log
把日志发送给 logstash
编辑配置文件 /etc/filebeat/filebeat.yml,在 output.logstash 段修改配置 中的内容:
output.logstash:
# The Logstash hosts
hosts: ["your log server ip:5044"]
多行事件编码(合并多行到一条记录)
在 filebeat.prospectors 配置块中添加下面的配置:
### Multiline options
multiline.pattern: '^\['
multiline.negate: true
multiline.match: after
注释掉 output.elasticsearch
同时要把 output.elasticsearch 的配置注释掉。
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
最后启动 filebeat 服务:
$ sudo systemctl start filebeat.service
测试一下
通过 echo 向 /home/nick/work/test.log 文件中追加 '[' 开头的行模拟日志记录:
echo "[exception:]" >> work/test.log
echo " at xxx" >> work/test.log
echo " at xxx" >> work/test.log
echo "[OK]" >> work/test.log
" at" 开头的行用来模拟程序中的异常堆栈。
在浏览器中打开 kibana,添加 beat-test* 模式的索引就可以看到日志记录了:

由于我们在 filebeat 的配置中设置了 multiline 处理,所以类似 " at" 开头的行会被认为是异常堆栈从而合并到一条记录中:

这样的设置在故障调查时会让异常堆栈看起来更友好些!
总结
ELK 本身是个体量比较大的日志系统(当然也可以用来干其它的事情),安装和配置都会有些坑。本文只是介绍如何部署一个袖珍的 demo 环境,方便大家开始了解和学习 ELK。
单机部署 ELK的更多相关文章
- Centos7单机部署ELK+x-pack
ELK分布式框架作为现在大数据时代分析日志的常为大家使用.现在我们就记录下单机Centos7部署ELK的过程和遇到的问题. 系统要求:Centos7(内核3.5及以上,2核4G) elk版本:6.2. ...
- Linux下单机部署ELK日志收集、分析环境
一.ELK简介 ELK是elastic 公司旗下三款产品ElasticSearch .Logstash .Kibana的首字母组合,主要用于日志收集.分析与报表展示. ELK Stack包含:Elas ...
- Centos7单机部署ELK
一. 简介 1.1 介绍 ELK是三个开源工具组成,简单解释如下: Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风 ...
- linux单机部署kafka(filebeat+elk组合)
filebeat+elk组合之kafka单机部署 准备: kafka下载链接地址:http://kafka.apache.org/downloads.html 在这里下载kafka_2.12-2.10 ...
- 被一位读者赶超,手摸手 Docker 部署 ELK Stack
被一位读者赶超,容器化部署 ELK Stack 你好,我是悟空. 被奇幻"催更" 最近有个读者,他叫"老王",外号"茴香豆泡酒",找我崔更 ...
- Hadoop系列之(一):Hadoop单机部署
1. Hadoop介绍 Hadoop是一个能够对海量数据进行分布式处理的系统架构. Hadoop框架的核心是:HDFS和MapReduce. HDFS分布式文件系统为海量的数据提供了存储, MapRe ...
- Ecstore安装篇-2.单机部署【linux】
单机部署实施-linux 单机部署实施-linux author :James,jimingsong@vip.qq.com since :2015-03-02 系统环境需求 软件来源 底层依赖 1. ...
- ETL作业调度软件TASKCTL4.1单机部署
单机部署,实际上就是将EM节点和一个Server节点安装到同一个地方.EM节点是TASKCTL服务端的最顶层,主要负责客户端与服务端之间的通信.Server节点是TASKCTL的调度服务控制层,也有A ...
- [原创]ubuntu14.04部署ELK+redis日志分析系统
ubuntu14.04部署ELK+redis日志分析系统 [环境] host1:172.17.0.4 搭建ELK+redis服务 host2:172.17.0.3 搭建logstash+nginx服务 ...
随机推荐
- Docker中安装WordPress
前言 虚拟化技术风靡一时,还不层在生产环境中实践.只能是闭门造车,自己玩一玩了,接触了一下docker最简单的命令,这才自己搭建一个wordpress玩一玩. 安装wordpress之前先把本机的do ...
- 杭电ACM2015--偶数求和
偶数求和 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submis ...
- WebService简单介绍(一)
分布式系统或软件如何通信?使用WebService服务.说它是服务可以,web通信中间件也ok,web通信组件....... 特点 自包含 自描述 跨平台.跨语言 基于开放和标准 (用了xml,嗯,开 ...
- 【WebAPI No.3】API的访问控制IdentityServer4
介绍: IdentityServer是一个OpenID Connect提供者 - 它实现了OpenID Connect和OAuth 2.0协议.是一种向客户发放安全令牌的软件. 官网给出的功能解释是: ...
- 前端入门13-JavaScript进阶之原型
声明 本系列文章内容全部梳理自以下几个来源: <JavaScript权威指南> MDN web docs Github:smyhvae/web Github:goddyZhao/Trans ...
- CSS3图片翻转动画技术详解
CSS动画非常的有趣:这种技术的美就在于,通过使用很多简单的属性,你能创建出漂亮的消隐效果.其中代表性的一种就是CSS图片翻转效果,能让你看到一张卡片的正反两面上的内容.本文就是要用最简单的方法向大家 ...
- [Web][DreamweaverCS6][高中同学毕业分布去向网站+服务器上挂载]一、安装与破解DreamweaverCS6+基本规划
DreamweaverCS6安装与破解 一.背景介绍:同学毕业分布图项目计划简介 哎哎哎,炸么说呢,对于Web前端设计来说,纯手撕html部分代码实在是难受. 对于想做地图这类的就“必须”用这个老工具 ...
- SQL Server GUID 数据迁移至MongoDB后怎样查看?
关键字:SQL Server NEWID():BSON:MongoDB UUID 1.遇到的问题和困惑 SQL Server中的NEWID数据存储到MongoDB中会是什么样子呢?发现不能简单的通过此 ...
- oracle 10g函数大全--日期型函数
sysdate [功能]:返回当前日期. [参数]:没有参数,没有括号 [返回]:日期 [示例]select sysdate hz from dual; 返回:2008-11-5 add_months ...
- c/c++ linux 进程间通信系列7,使用pthread mutex
linux 进程间通信系列7,使用pthread mutex #include <stdio.h> #include <stdlib.h> #include <unist ...