HBase总结 LSM理解
转载的文章,觉得写的比较好
讲LSM树之前,需要提下三种基本的存储引擎,这样才能清楚LSM树的由来:
- 哈希存储引擎 是哈希表的持久化实现,支持增、删、改以及随机读取操作,但不支持顺序扫描,对应的存储系统为key-value存储系统。对于key-value的插入以及查询,哈希表的复杂度都是O(1),明显比树的操作O(n)快,如果不需要有序的遍历数据,哈希表就是your Mr.Right
- B树存储引擎是B树(关于B树的由来,数据结构以及应用场景可以看之前一篇博文)的持久化实现,不仅支持单条记录的增、删、读、改操作,还支持顺序扫描(B+树的叶子节点之间的指针),对应的存储系统就是关系数据库(Mysql等)。
- LSM树(Log-Structured Merge Tree)存储引擎和B树存储引擎一样,同样支持增、删、读、改、顺序扫描操作。而且通过批量存储技术规避磁盘随机写入问题。当然凡事有利有弊,LSM树和B+树相比,LSM树牺牲了部分读性能,用来大幅提高写性能。
通过以上的分析,应该知道LSM树的由来了,LSM树的设计思想非常朴素:将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作批量写入磁盘,不过读取的时候稍微麻烦,需要合并磁盘中历史数据和内存中最近修改操作,所以写入性能大大提升,读取时可能需要先看是否命中内存,否则需要访问较多的磁盘文件。极端的说,基于LSM树实现的HBase的写性能比Mysql高了一个数量级,读性能低了一个数量级。
LSM树原理把一棵大树拆分成N棵小树,它首先写入内存中,随着小树越来越大,内存中的小树会flush到磁盘中,磁盘中的树定期可以做merge操作,合并成一棵大树,以优化读性能
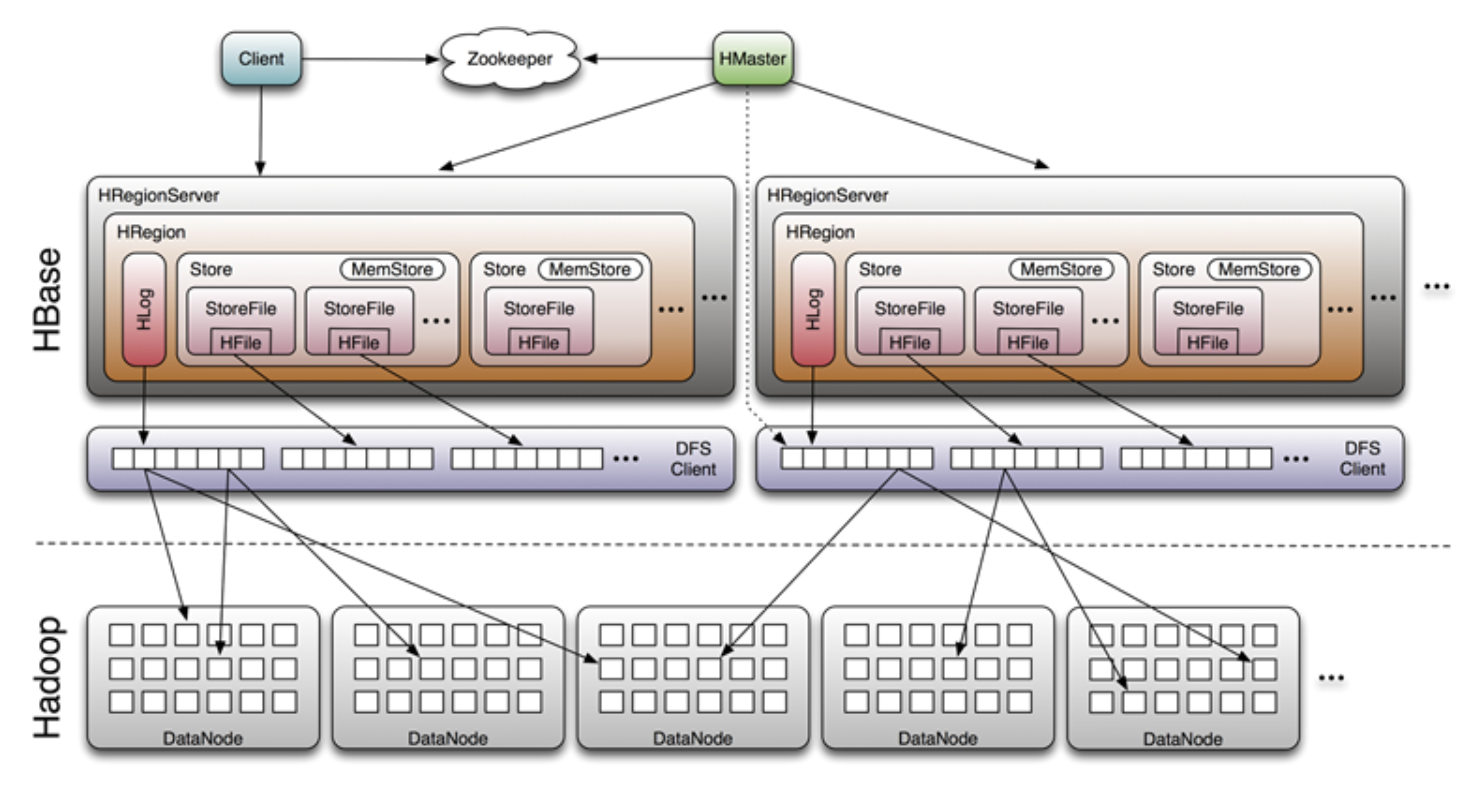
以上这些大概就是HBase存储的设计主要思想,这里分别对应说明下:
- 因为小树先写到内存中,为了防止内存数据丢失,写内存的同时需要暂时持久化到磁盘,对应了HBase的MemStore和HLog
- MemStore上的树达到一定大小之后,需要flush到HRegion磁盘中(一般是Hadoop DataNode),这样MemStore就变成了DataNode上的磁盘文件StoreFile,定期HRegionServer对DataNode的数据做merge操作,彻底删除无效空间,多棵小树在这个时机合并成大树,来增强读性能。
关于LSM Tree,对于最简单的二层LSM Tree而言,内存中的数据和磁盘你中的数据merge操作,如下图
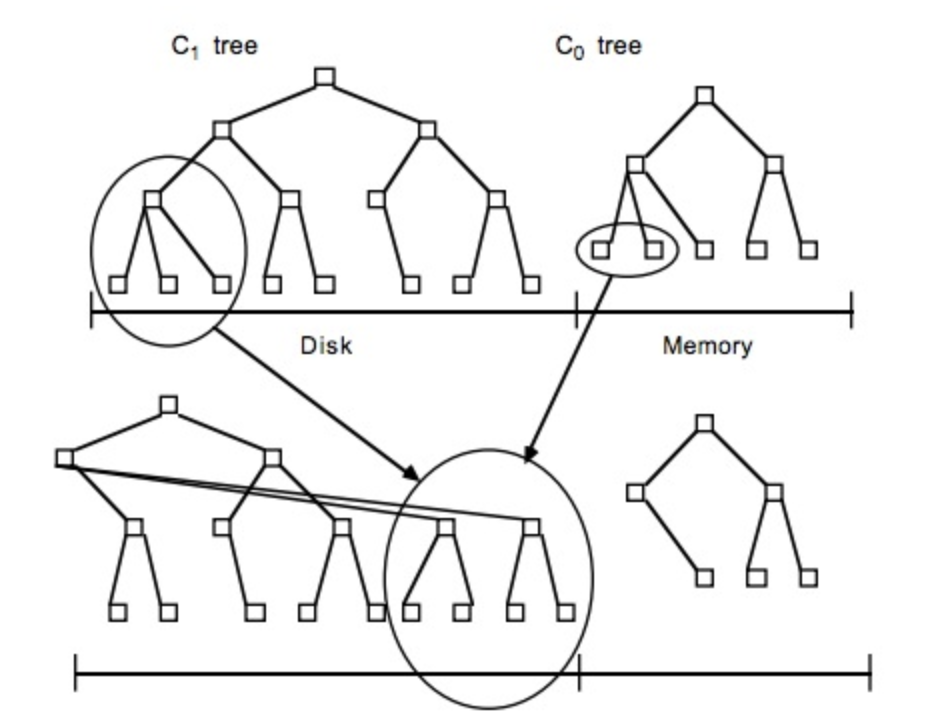
lsm tree,理论上,可以是内存中树的一部分和磁盘中第一层树做merge,对于磁盘中的树直接做update操作有可能会破坏物理block的连续性,但是实际应用中,一般lsm有多层,当磁盘中的小树合并成一个大树的时候,可以重新排好顺序,使得block连续,优化读性能。
hbase在实现中,是把整个内存在一定阈值后,flush到disk中,形成一个file,这个file的存储也就是一个小的B+树,因为hbase一般是部署在hdfs上,hdfs不支持对文件的update操作,所以hbase这么整体内存flush,而不是和磁盘中的小树merge update,这个设计也就能讲通了。内存flush到磁盘上的小树,定期也会合并成一个大树。整体上hbase就是用了lsm tree的思路。
HBase总结 LSM理解的更多相关文章
- sstable, bigtable,leveldb,cassandra,hbase的lsm基础
先看懂文献1和2 1. 先了解sstable.SSTable: Sorted String Table [2] [10] WiscKey: 类似myisam, key value分离, 根据ssd优 ...
- <HBase><读写><LSM>
Overview HBase中的一个big table,首先会按行划分成一些region(这些region之间是有序的,由startkey保证),每个region分配到不同的节点进行存储.因此,reg ...
- 快速理解 Phoenix : SQL on HBASE
转自:http://blog.csdn.net/colorant/article/details/8645081 ==是什么 == 目标Scope EasyStandard SQL access on ...
- hbase概念
1. 概述(扯淡~) HBase是一帮家伙看了Google发布的一片名为“BigTable”的论文以后,犹如醍醐灌顶,进而“山寨”出来的一套系统. 由此可见: 1. 几乎所有的HBase中的理念,都可 ...
- HBase概念及表格设计
HBase概念及表格设计 1. 概述(扯淡~) HBase是一帮家伙看了Google发布的一片名为“BigTable”的论文以后,犹如醍醐灌顶,进而“山寨”出来的一套系统. 由此可见: 1. 几乎所有 ...
- HBase写请求分析
HBase作为分布式NoSQL数据库系统,不单支持宽列表.而且对于随机读写来说也具有较高的性能.在高性能的随机读写事务的同一时候.HBase也能保持事务的一致性. 眼下HBase仅仅支持行级别的事务一 ...
- [Spark] 04 - HBase
BHase基本知识 基本概念 自我介绍 HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”. ...
- 【转帖】LSM树 和 TSM存储引擎 简介
LSM树 和 TSM存储引擎 简介 2019-03-08 11:45:23 长烟慢慢 阅读数 461 收藏 更多 分类专栏: 时序数据库 版权声明:本文为博主原创文章,遵循CC 4.0 BY-S ...
- HBase原理 – 分布式系统中snapshot是怎么玩的?(转载)
snapshot(快照)基础原理 snapshot是很多存储系统和数据库系统都支持的功能.一个snapshot是一个全部文件系统.或者某个目录在某一时刻的镜像.实现数据文件镜像最简单粗暴的方式是加锁拷 ...
随机推荐
- 三菱FX系列PLC教程
标 题 日 期 点击 第一章:可编程控制器概论 2014-11-04 1401 1-0 课程概述 2014-11-05 192237 1-1 PLC的定义功能与特点 2014-11-05 16 ...
- linux 定时下载github最新代码
场景:网站的代码在github上托管,静态网站部署在服务器上,每次自己修改完本地代码后,提交到github上,需要自己去服务器上执行git pull 拉取最新代码, 为了解决这种操作,自己再服务器上 ...
- windows 8.1 cmd命名提示符全屏
在 C:\Users\wy\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\System Tools 目录下,右键命令提示符-属性中修改:
- [HDU5969] 最大的位或
题目类型:位运算 传送门:>Here< 题意:给出\(l\)和\(r\),求最大的\(x|y\),其中\(x,y\)在\([l,r]\)范围内 解题思路 首先让我想到了前面那题\(Bits ...
- [SDOI2006] 保安站岗
题目链接 第一遍不知道为什么就爆零了…… 第二遍改了一下策略,思路没变,结果不知道为什么就 A 了??? 树形 DP 经典问题:选择最少点以覆盖树上所有点(边). 对于本题,设 dp[i][0/1][ ...
- 金融量化分析【day113】:布林带策略
一.布林带策略简介 1.简介 2.计算公式 3.图形 二.布林带策略代码 import jqdata def initialize(context): set_benchmark('0000 ...
- MSSQL Server2012备份所有数据库到网络共享盘上面,并自动删除几天前的备份。。
--要备份到哪一服务的IP网络位置,要提前打开文件夹共享.这里还要输入用户名和密码,下面这一行是建立共享 exec master..xp_cmdshell 'net use \\192.168.8.1 ...
- Python 各种进制转换
#coding=gbk var=input("请输入十六进制数:") b=bin(int(var,16)) print(b[2:]) 详细请参考python自带int函数.bin函 ...
- 利用pyinstaller 打包Python文件
1.下载安装pyinstaller模块 cmd 命令: pip install pyinstaller cmd命令: pip list 查看自己安装的模块 2.建议把要大包的Python文件单独放到新 ...
- 更改 Ubuntu默认Python版本的问题
一般Ubuntu默认版本为2.x,之前运行一些程序,将默认版本修改为3.5,现在想修改为2.7. 之前的方法有些忘记,现在重新记录一下: 1.查看你系统中有哪些Python的二进制文件可供使用, ls ...