从零开始学Python 三(网络爬虫)
本章由网络爬虫的编写来学习python。首先写几行代码抓取百度首页,提提精神,代码如下:
import urllib.request
file=urllib.request.urlopen("http://www.baidu.com")
data=file.read()
handle=open("code/python/baidu.html","wb")
handle.write(data)
handle.close()
除了第一行导入第三方包之外,我们用5行代码实现了一个简单的程序:读取百度首页并存储在本地制定文件。下面来详细介绍代码:
1.import urllib.request
urllib库是python的一个操作url功能强大的库,经常用在爬虫程序中。使用上述代码,我们便可以在程序中打开并爬取网页。
2.urllib.request.urlopen("http://www.baidu.com")
使用urlopen方法,参数为想爬取的网页。成功之后,把爬取的内容赋值给file变量。
另,读取file数据有2种方法:
file.read() //读取全部数据
file.readline()//读取一行数据
3.handle=open("code/python/baidu.html","wb")
通过open函数打开一个文件,并且以“wb”即二进制写入方式打开,然后赋值给hadle变量。需要注意首先建立对应的文件夹和文件,否则无法运行。错误如下:
Traceback (most recent call last):
File "<pyshell#10>", line 1, in <module>
fhandle=open("/code/python","wb")
FileNotFoundError: [Errno 2] No such file or directory:
4.handle.write(data)
使用write()方法将data数据写入文件
5.handle.close()
关闭文件。操作完文件之后一定要记得关闭。至此,我们就把百度首页保存到了本地文件:
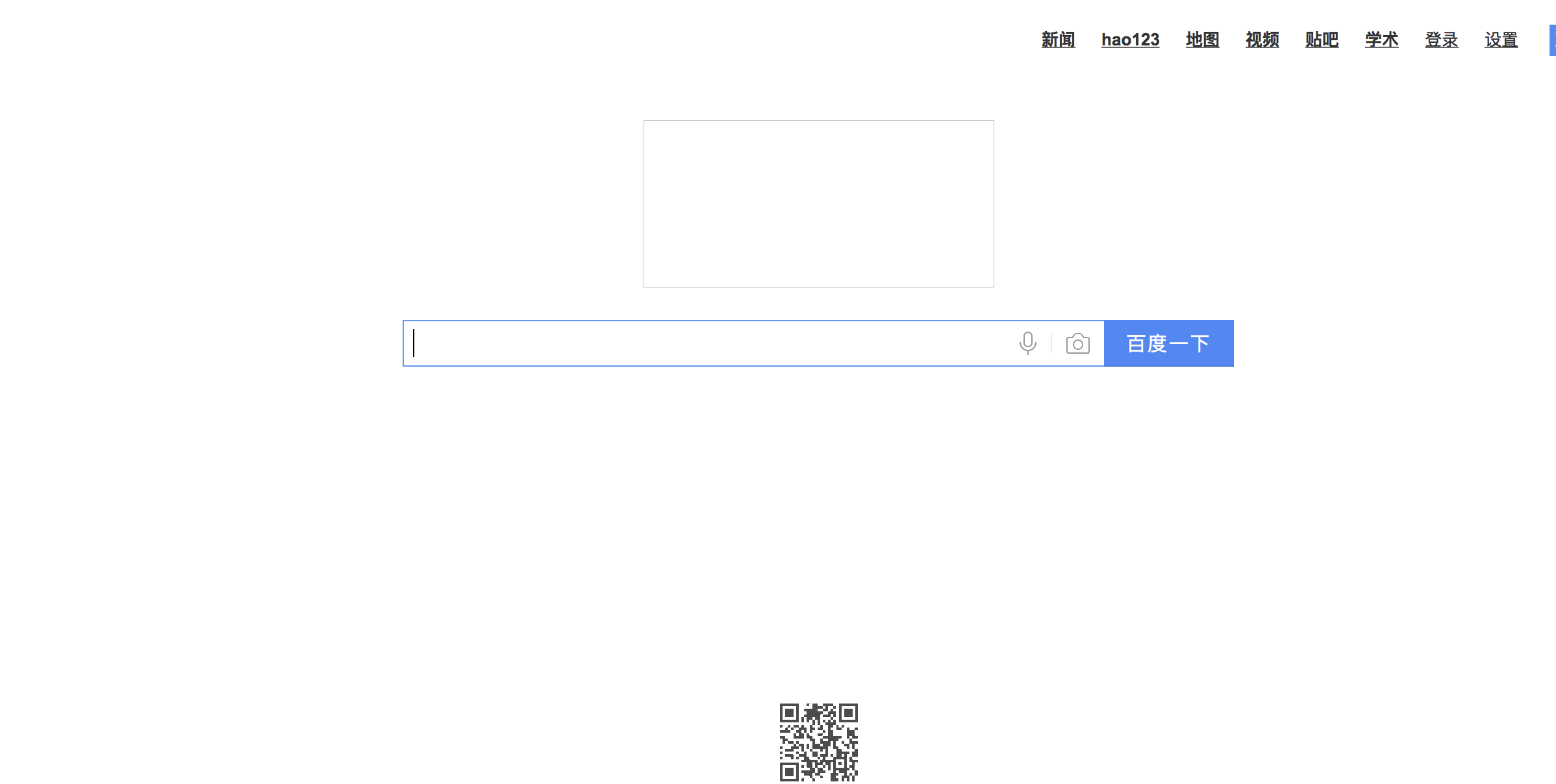
打开文件显示如下:
其实,上面5行代码可以精简为1行,功能不变但代码更少:
>>> import urllib.request
>>>
>>> urllib.request.urlretrieve("http://www.baidu.com","code/python/baidu2.html")
('code/python/baidu2.html', <http.client.HTTPMessage object at 0x1060f8240>)
>>>
接着,让我们更进一步,用程序模拟百度搜索操作。
当我们在百度上查询时,是在输入框中输入关键字,然后点击回车,接着百度返回搜索结果。这一系列操作通过http语音描述如下:使用get方法,通过"http://www.baidu.com/s?wd="+关键字调用百度服务。明白背后原理之后,我们用python模拟搜索“逃税”的操作,代码如下:
>>> url="http://www.baidu.com/s?wd="
>>> key="逃税"
>>> key_code=urllib.request.quote(key)
>>> urllib.request.urlretrieve(url+key_code,"code/python/baidu逃税.html")
('code/python/baidu逃税.html', <http.client.HTTPMessage object at 0x1060f8f98>)
打开本地文件后,发现和在百度上输入一模一样。
上面代码有个关键点:URL标准中只允许一部分ASCII字符(字母、数字),其他的比如汉字不符合标准。因此不能直接在url后面拼接汉字,需要使用quote()方法进行编码。相应的,如果需要对编码的网址进行解码,可以使用unquote()方法。
最后,以一个不完整的图片爬虫程序结束。
现在,我们想把淘宝网上连衣裙分类里的图片全部下载到本地。首先,找到目标网址(https://s.taobao.com/list?spm=a217f.8051907.312003.5.19833308A93qss&q=%E8%BF%9E%E8%A1%A3%E8%A3%99&cat=16&seller_type=taobao&oetag=6745&source=qiangdiao&bcoffset=12&s=180)。打开开发者工具,查看图片地址。
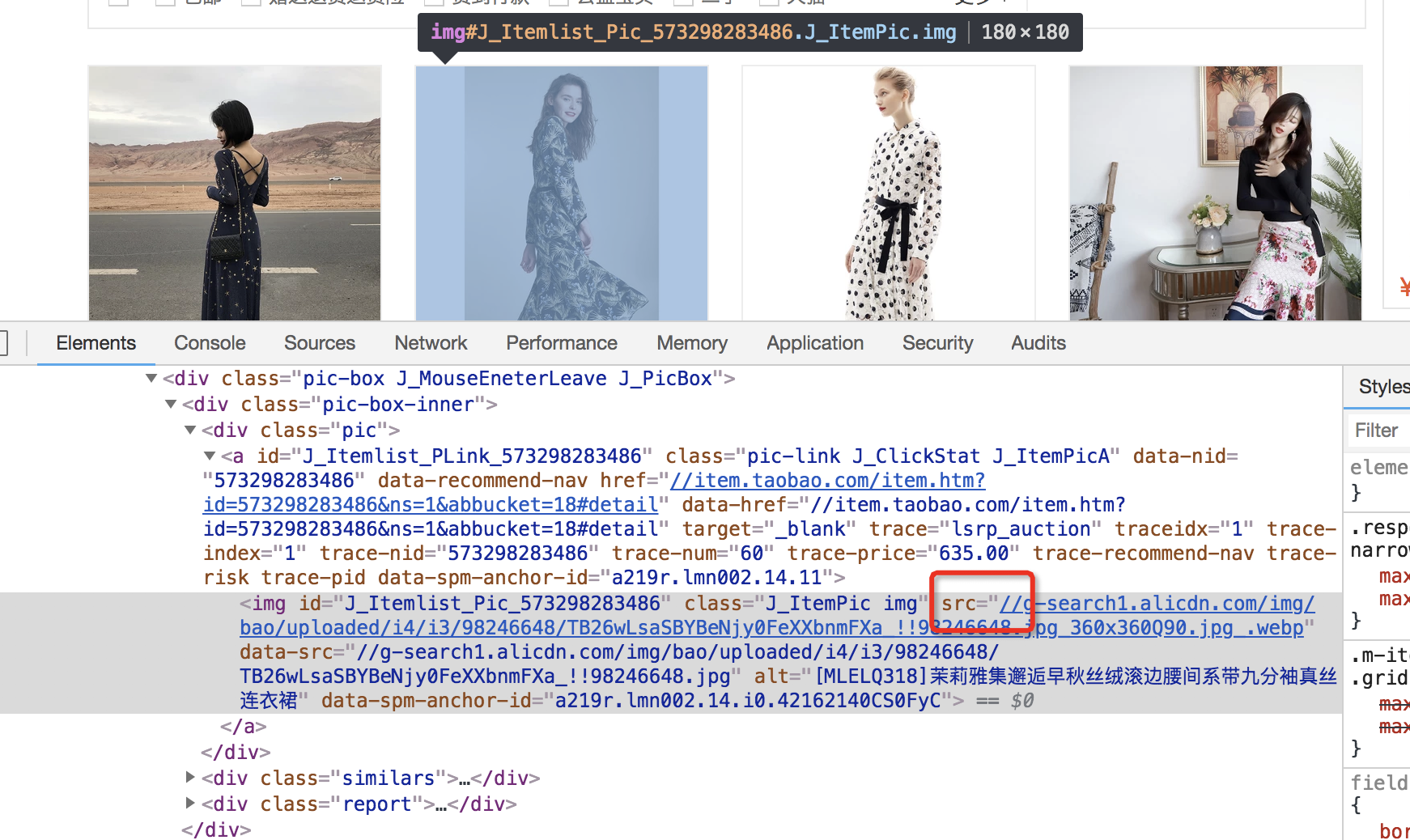
可以看到,我们已经拿到了图片路径,在浏览器上加上前缀"http://"就可以打开。
因此,程序逻辑如下:
循环获取网址内容->对于每个网址找到需要的图片->构造图片路径,下载到本地
具体代码请等下期内容。
从零开始学Python 三(网络爬虫)的更多相关文章
- 从零开始学Python网络爬虫PDF高清完整版免费下载|百度网盘
百度网盘:从零开始学Python网络爬虫PDF高清完整版免费下载 提取码:wy36 目录 前言第1章 Python零基础语法入门 11.1 Python与PyCharm安装 11.1.1 Python ...
- Python 3网络爬虫开发实战中文 书籍软件包(原创)
Python 3网络爬虫开发实战中文 书籍软件包(原创) 本书书籍软件包为本人原创,想学爬虫的朋友你们的福利来了.软件包包含了该书籍所需的所有软件. 因为软件导致这个文件比较大,所以百度网盘没有加速的 ...
- Python 3网络爬虫开发实战书籍
Python 3网络爬虫开发实战书籍,教你学会如何用Python 3开发爬虫 本书介绍了如何利用Python 3开发网络爬虫,书中首先介绍了环境配置和基础知识,然后讨论了urllib.reques ...
- 读书笔记汇总 --- 用Python写网络爬虫
本系列记录并分享:学习利用Python写网络爬虫的过程. 书目信息 Link 书名: 用Python写网络爬虫 作者: [澳]理查德 劳森(Richard Lawson) 原版名称: web scra ...
- Python即时网络爬虫项目启动说明
作为酷爱编程的老程序员,实在按耐不下这个冲动,Python真的是太火了,不断撩拨我的心. 我是对Python存有戒备之心的,想当年我基于Drupal做的系统,使用php语言,当语言升级了,推翻了老版本 ...
- Python即时网络爬虫项目: 内容提取器的定义(Python2.7版本)
1. 项目背景 在Python即时网络爬虫项目启动说明中我们讨论一个数字:程序员浪费在调测内容提取规则上的时间太多了(见上图),从而我们发起了这个项目,把程序员从繁琐的调测规则中解放出来,投入到更高端 ...
- Python即时网络爬虫项目: 内容提取器的定义
1. 项目背景 在python 即时网络爬虫项目启动说明中我们讨论一个数字:程序员浪费在调测内容提取规则上的时间,从而我们发起了这个项目,把程序员从繁琐的调测规则中解放出来,投入到更高端的数据处理工作 ...
- Python即时网络爬虫:API说明
API说明——下载gsExtractor内容提取器 1,接口名称 下载内容提取器 2,接口说明 如果您想编写一个网络爬虫程序,您会发现大部分时间耗费在调测网页内容提取规则上,不讲正则表达式的语法如何怪 ...
- Python学习网络爬虫--转
原文地址:https://github.com/lining0806/PythonSpiderNotes Python学习网络爬虫主要分3个大的版块:抓取,分析,存储 另外,比较常用的爬虫框架Scra ...
随机推荐
- drools kie-server和kie-workbench安装手册
Drools规则引擎可以直接在项目中编写drl文件,后调用. 也可以搭建kie-server和kie-workbench来进行远程调用. 关系: 在kie-workbench通过页面配置规则,发布到执 ...
- JAVA获取计算机IP地址
import java.net.InetAddress;import java.net.UnknownHostException;public class HuoQu { public stat ...
- hdu1172(枚举)
中文题,题意就不解释了. 思路:因为答案一定是四位数,所以只要枚举1000-9999,如果符合所有条件,那么保存一下答案,记录一下答案的个数,如果答案是唯一的,那么输出它,否则,就不确定. 代码如下: ...
- telnet客户端操作memcached增删改查
一,通过telnet连接进入memcached(telnet 本地ip/服务器ip 端口) 进入后回车看效果: 二, 添加数据和取出数据 添加命令: add key名 0(固定) ...
- 集束搜索beam search和贪心搜索greedy search
贪心搜索(greedy search) 贪心搜索最为简单,直接选择每个输出的最大概率,直到出现终结符或最大句子长度. 集束搜索(beam search) 集束搜索可以认为是维特比算法的贪心形式,在维特 ...
- P4177 [CEOI2008]order(网络流)最大权闭合子图
P4177 [CEOI2008]order 如果不能租机器,这就是最大权闭合子图的题: 给定每个点的$val$,并给出限制条件:如果取点$x$,那么必须取$y_1,y_2,y_3......$,满足$ ...
- python 包 笔记
绝对导入和相对导入 我们的最顶级包glance是写给别人用的,然后在glance包内部也会有彼此之间互相导入的需求,这时候就有绝对导入和相对导入两种方式: 绝对导入:以glance作为起始 相对导入: ...
- iOS绘制坐标图,折线图-Swift
坐标图,经常会在各种各样的App中使用,最常用的一种坐标图就是折线图,根据给定的点绘制出对应的坐标图是最基本的需求.由于本人的项目需要使用折线图,第一反应就是搜索已经存在的解决方案,因为这种需求应该很 ...
- HBuilder --- MUI , HTML5
一.创建简单app应用 ① ② ③连接手机 ④ 二.MUI 各组件的运用 http://dev.dcloud.net.cn/mui/snippet/ 三. HTML5plus 参考文档: http ...
- yii 邮箱封装
<?php class Mailer { private static $obj; private static $config; public static function getMaile ...