Apache Kafka简介与安装(一)
介绍
Kafka是一个分布式的、可分区的、可复制的消息系统。它提供了普通消息系统的功能,但具有自己独特的设计。
首先让我们看几个基本的消息系统术语:
- Kafka将消息以topic为单位进行归纳。
- 将向Kafka topic发布消息的程序成为producers.
- 将预订topics并消费消息的程序成为consumer.
- Kafka以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker.
producers通过网络将消息发送到Kafka集群,集群向消费者提供消息,如下图所示:

客户端和服务端通过TCP协议通信。Kafka提供了Java客户端,并且对多种语言都提供了支持。
Topics 和Logs
先来看一下Kafka提供的一个抽象概念:topic.
一个topic是对一组消息的归纳。对每个topic,Kafka 对它的日志进行了分区,如下图所示:
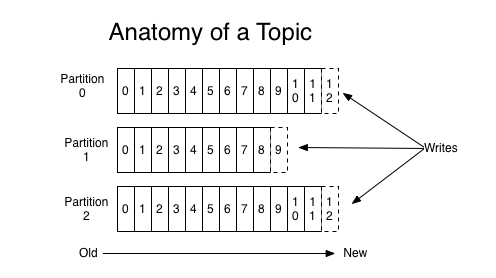
每个分区都由一系列有序的、不可变的消息组成,这些消息被连续的追加到分区中。分区中的每个消息都有一个连续的序列号叫做offset,用来在分区中唯一的标识这个消息。
在一个可配置的时间段内,Kafka集群保留所有发布的消息,不管这些消息有没有被消费。比如,如果消息的保存策略被设置为2天,那么在一个消息被发布的两天时间内,它都是可以被消费的。之后它将被丢弃以释放空间。Kafka的性能是和数据量无关的常量级的,所以保留太多的数据并不是问题。
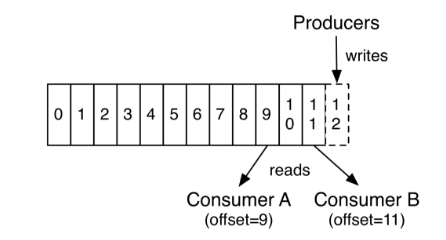
实际上每个consumer唯一需要维护的数据是消息在日志中的位置,也就是offset.这个offset有consumer来维护:一般情况下随着consumer不断的读取消息,这offset的值不断增加,但其实consumer可以以任意的顺序读取消息,比如它可以将offset设置成为一个旧的值来重读之前的消息。
以上特点的结合,使Kafka consumers非常的轻量级:它们可以在不对集群和其他consumer造成影响的情况下读取消息。你可以使用命令行来"tail"消息而不会对其他正在消费消息的consumer造成影响。
将日志分区可以达到以下目的:首先这使得每个日志的数量不会太大,可以在单个服务上保存。另外每个分区可以单独发布和消费,为并发操作topic提供了一种可能。
分布式
每个分区在Kafka集群的若干服务中都有副本,这样这些持有副本的服务可以共同处理数据和请求,副本数量是可以配置的。副本使Kafka具备了容错能力。
每个分区都由一个服务器作为“leader”,零或若干服务器作为“followers”,leader负责处理消息的读和写,followers则去复制leader.如果leader down了,followers中的一台则会自动成为leader。集群中的每个服务都会同时扮演两个角色:作为它所持有的一部分分区的leader,同时作为其他分区的followers,这样集群就会据有较好的负载均衡。
Producers
Producer将消息发布到它指定的topic中,并负责决定发布到哪个分区。通常简单的由负载均衡机制随机选择分区,但也可以通过特定的分区函数选择分区。使用的更多的是第二种。
Consumers
发布消息通常有两种模式:队列模式(queuing)和发布-订阅模式(publish-subscribe)。队列模式中,consumers可以同时从服务端读取消息,每个消息只被其中一个consumer读到;发布-订阅模式中消息被广播到所有的consumer中。Consumers可以加入一个consumer 组,共同竞争一个topic,topic中的消息将被分发到组中的一个成员中。同一组中的consumer可以在不同的程序中,也可以在不同的机器上。如果所有的consumer都在一个组中,这就成为了传统的队列模式,在各consumer中实现负载均衡。如果所有的consumer都不在不同的组中,这就成为了发布-订阅模式,所有的消息都被分发到所有的consumer中。更常见的是,每个topic都有若干数量的consumer组,每个组都是一个逻辑上的“订阅者”,为了容错和更好的稳定性,每个组由若干consumer组成。这其实就是一个发布-订阅模式,只不过订阅者是个组而不是单个consumer。
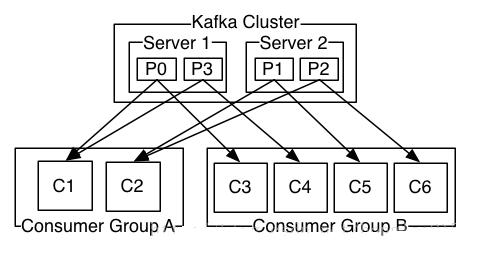
由两个机器组成的集群拥有4个分区 (P0-P3) 2个consumer组. A组有两个consumerB组有4个
相比传统的消息系统,Kafka可以很好的保证有序性。
传统的队列在服务器上保存有序的消息,如果多个consumers同时从这个服务器消费消息,服务器就会以消息存储的顺序向consumer分发消息。虽然服务器按顺序发布消息,但是消息是被异步的分发到各consumer上,所以当消息到达时可能已经失去了原来的顺序,这意味着并发消费将导致顺序错乱。为了避免故障,这样的消息系统通常使用“专用consumer”的概念,其实就是只允许一个消费者消费消息,当然这就意味着失去了并发性。
在这方面Kafka做的更好,通过分区的概念,Kafka可以在多个consumer组并发的情况下提供较好的有序性和负载均衡。将每个分区分只分发给一个consumer组,这样一个分区就只被这个组的一个consumer消费,就可以顺序的消费这个分区的消息。因为有多个分区,依然可以在多个consumer组之间进行负载均衡。注意consumer组的数量不能多于分区的数量,也就是有多少分区就允许多少并发消费。
Kafka只能保证一个分区之内消息的有序性,在不同的分区之间是不可以的,这已经可以满足大部分应用的需求。如果需要topic中所有消息的有序性,那就只能让这个topic只有一个分区,当然也就只有一个consumer组消费它。
Kafka详细介绍请查阅官网学习:http://kafka.apache.org/ 。
Apache Kafka简介与安装(一)的更多相关文章
- Apache Kafka简介与安装(二)
Kafka在Windows环境上安装与运行 简介 Apache kafka 是一个分布式的基于push-subscribe的消息系统,它具备快速.可扩展.可持久化的特点.它现在是Apache旗下的一个 ...
- Kafka简介、安装
一.Kafka简介 Kafka是一个分布式.可分区的.可复制的消息系统.几个基本的消息系统术语:1.消费者(Consumer):从消息队列(Kafka)中请求消息的客户端应用程序.2.生产者(Prod ...
- Apache Hive 简介及安装
简介 Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件 映射为一张数据库表,并提供类 SQL 查询功能. 本质是将 SQL 转换为 MapReduce 程序. 主要用途:用来 ...
- Apache Flume简介及安装部署
概述 Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的软件. Flume 的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目 ...
- 【Apache Kafka】一、Kafka简介及其基本原理
对于大数据,我们要考虑的问题有很多,首先海量数据如何收集(如Flume),然后对于收集到的数据如何存储(典型的分布式文件系统HDFS.分布式数据库HBase.NoSQL数据库Redis),其次存储 ...
- 【Apache Kafka】二、Kafka安装及简单示例
(一)Apache Kafka安装 1.安装环境与前提条件 安装环境:Ubuntu16.04 前提条件: ubuntu系统下安装好jdk 1.8以上版本,正确配置环境变量 ubuntu系统下安 ...
- Windows OS上安装运行Apache Kafka教程
Windows OS上安装运行Apache Kafka教程 下面是分步指南,教你如何在Windows OS上安装运行Apache Zookeeper和Apache Kafka. 简介 本文讲述了如何在 ...
- Netty学习——Apache Thrift 简介和下载安装
Netty学习——Apache Thrift 简介和下载安装 Apache Thrift 简介 本来由Facebook开发,捐献给了Apache,成了Apache的一个重要项目 可伸缩的,跨语言的服务 ...
- apache简介与安装
1.1 apache简介 apache当前全世界排名点击这里 1.1.1 当前互联网主流web服务说明 静态服务 apache --->中小型静态web服务的主流,web服务器中的老大哥 ngi ...
随机推荐
- iOS中 自定义cell分割线/分割线偏移 韩俊强的博客
在项目开发中我们会常常遇到tableView 的cell分割线显示不全,左边会空出一截像素,更有甚者想改变系统的分割线,并且只要上下分割线的一个等等需求,今天重点解决以上需求,仅供参考: 每日更新关注 ...
- iOS下WebRTC音视频通话(二)-局域网内音视频通话
这里是iOS 下WebRTC音视频通话开发的第二篇,在这一篇会利用一个局域网内音视频通话的例子介绍WebRTC中常用的API. 如果你下载并编译完成之后,会看到一个iOS 版的WebRTC Demo. ...
- Java中Integer和String浅谈
Java中的基本数据类型有八种:int.char.boolean.byte.long.double.float.short.Java作为一种面向对象的编程语言,数据在Java中也是一种对象.我们用基本 ...
- Cocos2D旋转炮塔到指定角度(二)
增加如下代码到ccTouchesEnded方法中,就在你在导弹精灵上调用runAction之前: // Determine angle to face float angleRadians = ata ...
- Spring mvc,uploadifive 文件上传实践(转自:https://segmentfault.com/a/1190000004503262)
1.前台页面: 引入js和css 全选复制放进笔记 <link type="text/css" rel="stylesheet" href=&quo ...
- Device Tree Usage(理解DTS文件语法)
Basic Data Format The device tree is a simple tree structure of nodes and properties. Properties are ...
- (NO.00001)iOS游戏SpeedBoy Lite成形记(十五)
现在啃第2个问题:如何让玩家输入赌注金额. 实现的方法有很多种,比如可以限制玩家只能从特定的金额中选择,把每个选择做成一个按钮即可.以下是一个假想选择窗口的示意图: 这样没有玩家的输入问题了.缺点是不 ...
- Android scrollview嵌套webview滑动冲突的解决方案
在Android开发中有时我们需要在scrollview中嵌套webview这时你会发现这两者的滑动事件产生了冲突导致:webview很难被滑动,即使被滑动了一点也非常不顺畅.解决方案也比较简单只需要 ...
- Android 免Root实现Apk静默安装,覆盖兼容市场主流的98%的机型
地址:http://blog.csdn.net/sk719887916/article/details/46746991 作者: skay 最近在做apk自我静默更新,在获取内置情况下,或者已root ...
- Ubuntu 14 安装WPS
在32位Ubuntu 14.04 安装 WPS,WPS For Linux版除延续Windows版相同体验外,更加尊重Linux用户特定的使用习惯:深度兼容:自带方正字体集:在线模板和素材使文档创作更 ...