Urllib库的基本用法
1、什么是url?
统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。
基本URL包含模式(或称协议)、服务器名称(或IP地址)、路径和文件名,如“协议://授权/路径?查询”。完整的、带有授权部分的普通统一资源标志符语法看上去如下:协议://用户名:密码@子域名.域名.顶级域名:端口号/目录/文件名.文件后缀?参数=值#标志
2、什么是Urllib库?
Urllib是python内置的处理URL的库,
包括以下模块
urllib.request 打开、读URLs
urllib.error 包含了request出现的异常
urllib.parse url解析模块
urllib.robotparser robots.txt解析模块(spider在访问一个网站时,会首先会检查该网站的根域下是否有一个叫做robots.txt的纯文本文件。您可以在您的网站中创建一个纯文本文件robots.txt,在文件中声明该网站中不想被robot访问的部分或者指定搜索引擎只收录特定的部分)
3、实例
(1)读一个网页
import urllib.request
with urllib.request.urlopen('http://www.baidu.com') as f:
print(f.read(20).decode('utf8'))
其中,urlopen返回的是一个字节类型的对象,这是由于urlopen不知道从服务器上读的数据该如何解码,需要我们自己对字符串解码。
如上,可以打开百度的界面,
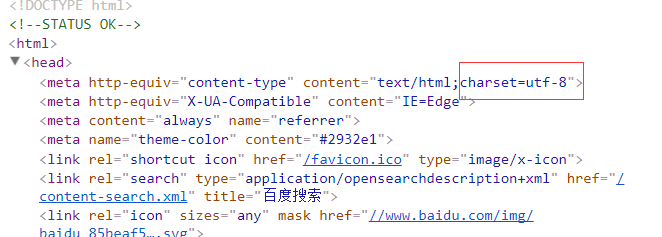
可以看到,此页面用utf-8编码。
当然,你也可以把代码改为:
import urllib.request
req = urllib.request.Request(url = 'http://www.baidu.com')
with urllib.request.urlopen(req) as f:
print(f.read(20).decode('utf8'))
访问请求放置在Request类中,该类包含一些属性,可以传递数据等,此处不过于深究。
(2)登陆动作(使用基础的HTTP身份验证)
Urllib库的基本用法的更多相关文章
- Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- Python爬虫Urllib库的高级用法
Python爬虫Urllib库的高级用法 设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Head ...
- Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 转 Python爬虫入门四之Urllib库的高级用法
静觅 » Python爬虫入门四之Urllib库的高级用法 1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我 ...
- python爬虫---urllib库的基本用法
urllib是python自带的请求库,各种功能相比较之下也是比较完备的,urllib库包含了一下四个模块: urllib.request 请求模块 urllib.error 异常处理模块 u ...
- Python爬虫入门(3-4):Urllib库的高级用法
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它 是一段HTML代码,加 JS.CS ...
- Python爬虫 Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 芝麻HTTP: Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 4.Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
随机推荐
- POJ 3255 Roadblocks (次短路 SPFA )
题目链接 Description Bessie has moved to a small farm and sometimes enjoys returning to visit one of her ...
- mybatis的配置文件中<selectKey>标签问题
1.mybatis的配置文件中,使用sequence生成主键 未执行add方法之前,主键未生成(null):刚执行add之后,主键即生成(212) 这里的重点是,一旦执行add方法,配置文件中的sel ...
- oracle06
1. Oracle的体系结构 - 了解 1.1. Oracle数据库和Oracle实例 Oracle 服务器软件部分由两大部分组成, Oracle 数据库 和 Oracle 实例. 两者的解释如下: ...
- hdu 1251 统计难题(字典树)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1251 统计难题 Time Limit: 4000/2000 MS (Java/Others) M ...
- MySQL防范SQL注入风险
MySQL防范SQL注入风险 0.导读 在MySQL里,如何识别并且避免发生SQL注入风险 1.关于SQL注入 互联网很危险,信息及数据安全很重要,SQL注入是最常见的入侵手段之一,其技术门槛低.成本 ...
- python 面试题4
Python面试题 基础篇 分类: Python2014-08-08 13:15 2071人阅读 评论(0) 收藏 举报 最近,整理了一些python常见的面试题目,语言是一种工具,但是多角度的了解工 ...
- OpenJ_POJ 1058 Guideposts
Problem OpenJ_POJ Solution 如果我们用 \(G\) 来表示邻接矩阵,那么答案其实就是求\(\sum_{k|i}^n \binom n i G^i\) 为了消除整除的限制,我们 ...
- 记录一款Unity VR视频播放器插件的开发
效果图 先上一个效果图: 背景 公司最近在做VR直播平台,VR开发我们用到了Unity,而在Unity中播放视频就需要一款视频插件,我们调研了几个视频插件,记录两个,如下: Unity视频插件调研 网 ...
- 002_curl及postman专题
一. 步骤 1: 下载cURL工具 使用您的Windows机器从cURL web站点下载最新版本的cURL: (1) 通常情况下,多数的Windows用户可以从官网下载页面http://curl.ha ...
- 淘宝开放平台TOP SDK调用对接淘宝或天猫
如果在淘宝/天猫上开了网店,用户自己也有一套自己的管理平台,这时可能会考虑和淘宝进行数据对接.这就需要考虑调用阿里提供的开发接口来推送和接收数据. 对接的方式有2种,一种是通过http接口,另外一种是 ...