Urllib库的基本用法
1、什么是url?
统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。
基本URL包含模式(或称协议)、服务器名称(或IP地址)、路径和文件名,如“协议://授权/路径?查询”。完整的、带有授权部分的普通统一资源标志符语法看上去如下:协议://用户名:密码@子域名.域名.顶级域名:端口号/目录/文件名.文件后缀?参数=值#标志
2、什么是Urllib库?
Urllib是python内置的处理URL的库,
包括以下模块
urllib.request 打开、读URLs
urllib.error 包含了request出现的异常
urllib.parse url解析模块
urllib.robotparser robots.txt解析模块(spider在访问一个网站时,会首先会检查该网站的根域下是否有一个叫做robots.txt的纯文本文件。您可以在您的网站中创建一个纯文本文件robots.txt,在文件中声明该网站中不想被robot访问的部分或者指定搜索引擎只收录特定的部分)
3、实例
(1)读一个网页
import urllib.request
with urllib.request.urlopen('http://www.baidu.com') as f:
print(f.read(20).decode('utf8'))
其中,urlopen返回的是一个字节类型的对象,这是由于urlopen不知道从服务器上读的数据该如何解码,需要我们自己对字符串解码。
如上,可以打开百度的界面,
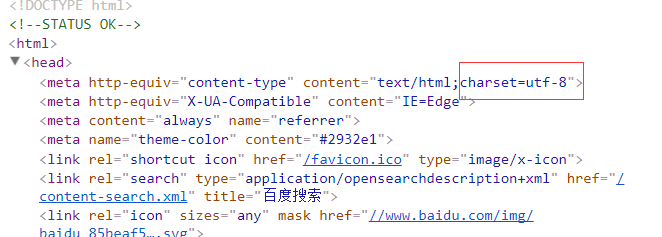
可以看到,此页面用utf-8编码。
当然,你也可以把代码改为:
import urllib.request
req = urllib.request.Request(url = 'http://www.baidu.com')
with urllib.request.urlopen(req) as f:
print(f.read(20).decode('utf8'))
访问请求放置在Request类中,该类包含一些属性,可以传递数据等,此处不过于深究。
(2)登陆动作(使用基础的HTTP身份验证)
Urllib库的基本用法的更多相关文章
- Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- Python爬虫Urllib库的高级用法
Python爬虫Urllib库的高级用法 设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Head ...
- Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 转 Python爬虫入门四之Urllib库的高级用法
静觅 » Python爬虫入门四之Urllib库的高级用法 1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我 ...
- python爬虫---urllib库的基本用法
urllib是python自带的请求库,各种功能相比较之下也是比较完备的,urllib库包含了一下四个模块: urllib.request 请求模块 urllib.error 异常处理模块 u ...
- Python爬虫入门(3-4):Urllib库的高级用法
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它 是一段HTML代码,加 JS.CS ...
- Python爬虫 Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 芝麻HTTP: Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 4.Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
随机推荐
- js操作控制iframe页面的dom元素
1.代码1 index.html <!DOCTYPE html> <html> <head> <meta charset="UTF-8" ...
- Django认证系统实现的web页面
结合数据库.ajax.js.Djangoform表单和认证系统的web页面 一:数据模块 扩展了Django中的user表,增加了自定义的字段 from django.db import models ...
- 最小生成树 kuangbin专题最后一个题
题目链接:https://cn.vjudge.net/contest/66965#problem/N 注释:这道题需要用krustra,用prim的话可能会超时.并且在计算距离的时候要尽量减少步骤,具 ...
- jQuery和Prototype的兼容性和冲突的五种解决方法
第一种情况:先加载Prototype,再加载jQuery方法一:jQuery 库和它的所有插件都是在jQuery名字空间内的,包括全局变量也是保存在jQuery 名字空间内的. 使用jQuery.no ...
- PL/SQ连接oracle,L 新建表的时候, virtual那一列是什么意思
Virtual标示该栏位是否为虚拟列. https://www.2cto.com/database/201306/216917.html
- TCP检验和
TCP的检验和 检验和目的 目的是为了发现TCP首部和数据在发送端到接收端之间发生的任何改动.如果接收方检测到检验和有差错,则TCP段会被直接丢弃. TCP在计算检验和时,要加上一个12字节的伪首 ...
- 企业日志大数据分析系统ELK+KAFKA实现【转】
背景: 最近线上上了ELK,但是只用了一台Redis在中间作为消息队列,以减轻前端es集群的压力,Redis的集群解决方案暂时没有接触过,并且Redis作为消息队列并不是它的强项:所以最近将Redis ...
- ETL利器Kettle实战应用解析系列三
本系列文章主要索引如下: 一.ETL利器Kettle实战应用解析系列一[Kettle使用介绍] 二.ETL利器Kettle实战应用解析系列二 [应用场景和实战DEMO下载] 三.ETL利器Kettle ...
- mac上安装完成node,就升级好了npm,之后的设置
1.打开终端输入: npm config list 找到npmrc globalconfig /usr/local/etc/npmrc 2.打开npmrc sudo vim /usr/local/et ...
- mysqlbinlog的日志类型
一.mysqlbinlog简介 binlog又叫二进制日志文件,它会将mysql中所有修改数据库数据的Query以二进制的形式记录到日志文件中,如:create,insert,drop,update等 ...