集合之hascode方法
在前面三篇博文中LZ讲解了(HashMap、HashSet、HashTable),在其中LZ不断地讲解他们的put和get方法,在这两个方法中计算key的hashCode应该是最重要也是最精华的部分,所以下面LZ揭开hashCode的“神秘”面纱。
hashCode的作用
要想了解一个方法的内在原理,我们首先需要明白它是干什么的,也就是这个方法的作用。在讲解数组时(java提高篇(十八)------数组),我们提到数组是java中效率最高的数据结构,但是“最高”是有前提的。第一我们需要知道所查询数据的所在位置。第二:如果我们进行迭代查找时,数据量一定要小,对于大数据量而言一般推荐集合。
在Java集合中有两类,一类是List,一类是Set他们之间的区别就在于List集合中的元素师有序的,且可以重复,而Set集合中元素是无序不可重复的。对于List好处理,但是对于Set而言我们要如何来保证元素不重复呢?通过迭代来equals()是否相等。数据量小还可以接受,当我们的数据量大的时候效率可想而知(当然我们可以利用算法进行优化)。比如我们向HashSet插入1000数据,难道我们真的要迭代1000次,调用1000次equals()方法吗?hashCode提供了解决方案。怎么实现?我们先看hashCode的源码(Object)。
public native int hashCode();
它是一个本地方法,它的实现与本地机器有关,这里我们暂且认为他返回的是对象存储的物理位置(实际上不是,这里写是便于理解)。当我们向一个集合中添加某个元素,集合会首先调用hashCode方法,这样就可以直接定位它所存储的位置,若该处没有其他元素,则直接保存。若该处已经有元素存在,就调用equals方法来匹配这两个元素是否相同,相同则不存,不同则散列到其他位置(具体情况请参考(Java提高篇()-----HashMap))。这样处理,当我们存入大量元素时就可以大大减少调用equals()方法的次数,极大地提高了效率。
所以hashCode在上面扮演的角色为寻域(寻找某个对象在集合中区域位置)。hashCode可以将集合分成若干个区域,每个对象都可以计算出他们的hash码,可以将hash码分组,每个分组对应着某个存储区域,根据一个对象的hash码就可以确定该对象所存储区域,这样就大大减少查询匹配元素的数量,提高了查询效率。
hashCode对于一个对象的重要性
hashCode重要么?不重要,对于List集合、数组而言,他就是一个累赘,但是对于HashMap、HashSet、HashTable而言,它变得异常重要。所以在使用HashMap、HashSet、HashTable时一定要注意hashCode。对于一个对象而言,其hashCode过程就是一个简单的Hash算法的实现,其实现过程对你实现对象的存取过程起到非常重要的作用。
在前面LZ提到了HashMap和HashTable两种数据结构,虽然他们存在若干个区别,但是他们的实现原理是相同的,这里我以HashTable为例阐述hashCode对于一个对象的重要性。
一个对象势必会存在若干个属性,如何选择属性来进行散列考验着一个人的设计能力。如果我们将所有属性进行散列,这必定会是一个糟糕的设计,因为对象的hashCode方法无时无刻不是在被调用,如果太多的属性参与散列,那么需要的操作数时间将会大大增加,这将严重影响程序的性能。但是如果较少属相参与散列,散列的多样性会削弱,会产生大量的散列“冲突”,除了不能够很好的利用空间外,在某种程度也会影响对象的查询效率。其实这两者是一个矛盾体,散列的多样性会带来性能的降低。
那么如何对对象的hashCode进行设计,LZ也没有经验。从网上查到了这样一种解决方案:设置一个缓存标识来缓存当前的散列码,只有当参与散列的对象改变时才会重新计算,否则调用缓存的hashCode,这样就可以从很大程度上提高性能。
在HashTable计算某个对象在table[]数组中的索引位置,其代码如下:
int index = (hash & 0x7FFFFFFF) % tab.length;
为什么要&0x7FFFFFFF?因为某些对象的hashCode可能会为负值,与0x7FFFFFFF进行与运算可以确保index为一个正数。通过这步我可以直接定位某个对象的位置,所以从理论上来说我们是完全可以利用hashCode直接定位对象的散列表中的位置,但是为什么会存在一个key-value的键值对,利用key的hashCode来存入数据而不是直接存放value呢?这就关系HashTable性能问题的最重要的问题:Hash冲突!
我们知道冲突的产生是由于不同的对象产生了相同的散列码,假如我们设计对象的散列码可以确保99.999999999%的不重复,但是有一种绝对且几乎不可能遇到的冲突你是绝对避免不了的。我们知道hashcode返回的是int,它的值只可能在int范围内。如果我们存放的数据超过了int的范围呢?这样就必定会产生两个相同的index,这时在index位置处会存储两个对象,我们就可以利用key本身来进行判断。所以具有相索引的对象,在该index位置处存在多个对象,我们必须依靠key的hashCode和key本身来进行区分。
hashCode与equals
在Java中hashCode的实现总是伴随着equals,他们是紧密配合的,你要是自己设计了其中一个,就要设计另外一个。当然在多数情况下,这两个方法是不用我们考虑的,直接使用默认方法就可以帮助我们解决很多问题。但是在有些情况,我们必须要自己动手来实现它,才能确保程序更好的运作。
对于equals,我们必须遵循如下规则:
对称性:如果x.equals(y)返回是“true”,那么y.equals(x)也应该返回是“true”。
反射性:x.equals(x)必须返回是“true”。
类推性:如果x.equals(y)返回是“true”,而且y.equals(z)返回是“true”,那么z.equals(x)也应该返回是“true”。
一致性:如果x.equals(y)返回是“true”,只要x和y内容一直不变,不管你重复x.equals(y)多少次,返回都是“true”。
任何情况下,x.equals(null),永远返回是“false”;x.equals(和x不同类型的对象)永远返回是“false”。
对于hashCode,我们应该遵循如下规则:
1. 在一个应用程序执行期间,如果一个对象的equals方法做比较所用到的信息没有被修改的话,则对该对象调用hashCode方法多次,它必须始终如一地返回同一个整数。
2. 如果两个对象根据equals(Object o)方法是相等的,则调用这两个对象中任一对象的hashCode方法必须产生相同的整数结果。
3. 如果两个对象根据equals(Object o)方法是不相等的,则调用这两个对象中任一个对象的hashCode方法,不要求产生不同的整数结果。但如果能不同,则可能提高散列表的性能。
至于两者之间的关联关系,我们只需要记住如下即可:
如果x.equals(y)返回“true”,那么x和y的hashCode()必须相等。
如果x.equals(y)返回“false”,那么x和y的hashCode()有可能相等,也有可能不等。
理清了上面的关系我们就知道他们两者是如何配合起来工作的。先看下图:
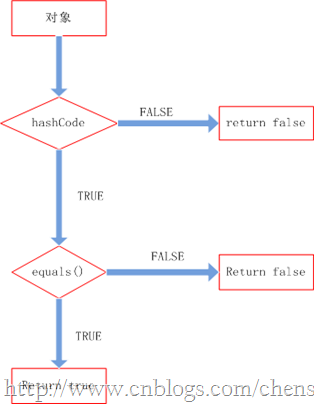
整个处理流程是:
1、判断两个对象的hashcode是否相等,若不等,则认为两个对象不等,完毕,若相等,则比较equals。
2、若两个对象的equals不等,则可以认为两个对象不等,否则认为他们相等。
实例:

public class Person { private int age; private int sex; //0:男,1:女 private String name; private final int PRIME = 37; Person(int age ,int sex ,String name){ this.age = age; this.sex = sex; this.name = name; } /** 省略getter、setter方法 **/ @Override public int hashCode() { System.out.println("调用hashCode方法..........."); int hashResult = 1; hashResult = (hashResult + Integer.valueOf(age).hashCode() + Integer.valueOf(sex).hashCode()) * PRIME; hashResult = PRIME * hashResult + ((name == null) ? 0 : name.hashCode()); System.out.println("name:"+name +" hashCode:" + hashResult); return hashResult; } /** * 重写hashCode() */ public boolean equals(Object obj) { System.out.println("调用equals方法..........."); if(obj == null){ return false; } if(obj.getClass() != this.getClass()){ return false; } if(this == obj){ return true; } Person person = (Person) obj; if(getAge() != person.getAge() || getSex()!= person.getSex()){ return false; } if(getName() != null){ if(!getName().equals(person.getName())){ return false; } } else if(person != null){ return false; } return true; }}
该Bean为一个标准的Java Bean,重新实现了hashCode方法和equals方法。
public class Main extends JPanel { public static void main(String[] args) { Set<Person> set = new HashSet<Person>(); Person p1 = new Person(11, 1, "张三"); Person p2 = new Person(12, 1, "李四"); Person p3 = new Person(11, 1, "张三"); Person p4 = new Person(11, 1, "李四"); //只验证p1、p3 System.out.println("p1 == p3? :" + (p1 == p3)); System.out.println("p1.equals(p3)?:"+p1.equals(p3)); System.out.println("-----------------------分割线--------------------------"); set.add(p1); set.add(p2); set.add(p3); set.add(p4); System.out.println("set.size()="+set.size()); }}
运行结果如下:

从上图可以看出,程序调用四次hashCode方法,一次equals方法,其set的长度只有3。add方法运行流程完全符合他们两者之间的处理流程。
集合之hascode方法的更多相关文章
- jmeter集合点使用方法:Synchronizing Timer
LR中集合点可以设置多个虚拟用户等待到一个点,同时触发一个事务,以达到模拟真实环境下多个用户同时操作,实现性能测试的最终目的. jmeter中使用Synchronizing Timer实现Lr中集合点 ...
- List集合和Set集合的遍历方法
Set集合遍历方法: 对 set 的遍历 1.迭代遍历: Set<String> set = new HashSet<String>(); Iterator<String ...
- HashSet集合的add()方法的源码
interface Collection { ... } interface Set extends Collection { ... } class HashSet implements Set { ...
- List集合的clear方法
一 . list.clear()底层源码实现 在使用list 结合的时候习惯了 list=null :在创建这样的方式,但是发现使用list的clear 方法很不错,尤其是有大量循环的时候 1.lis ...
- jmeter ---集合点使用方法:Synchronizing Timer
LR中集合点可以设置多个虚拟用户等待到一个点,同时触发一个事务,以达到模拟真实环境下多个用户同时操作,实现性能测试的最终目的. jmeter中使用Synchronizing Timer实现Lr中集合点 ...
- 元组/字典/集合内置方法+简单哈希表(day07整理)
目录 二十三.元组内置方法 二十四.字典数据类型 二十五 集合内置方法 二十五.数据类型总结 二十六.深浅拷贝 补充:散列表(哈希表) 二十三.元组内置方法 什么是元组:只可取,不可更改的列表 作用: ...
- c#中list集合使用Max()方法查找到最大值
在C#的List集合操作中,有时候需要查找到List集合中的最大值,此时可以使用List集合的扩展方法Max方法,Max方法有2种形式,一种是不带任何参数的形式,适用于一些值类型变量的List集合,另 ...
- 【转载】C#中List集合使用Max()方法查找到最大值
在C#的List集合操作中,有时候需要查找到List集合中的最大值,此时可以使用List集合的扩展方法Max方法,Max方法有2种形式,一种是不带任何参数的形式,适用于一些值类型变量的List集合,另 ...
- 【转载】C#中List集合使用LastOrDefault方法查找出最后一个符合条件的元素
在C#的List集合中,FirstOrDefault方法一般用来查找List集合中第一个符合条件的对象,如果未查到则返回相应默认值.其实如果要查找最后一个符合条件的List集合元素对象,可以使用Las ...
随机推荐
- MVC 客户端(Memo = "<img src="http://">")中检测到有潜在的危险的 Request.Form 值 的解决方案
解释定义:ASP.NET为了阻止跨站脚本攻击,会对向服务器端输入的HTML代码进行防御措施,在使用.NET MVC中,可以对validateinput属性设置,但是,有时需要ASP.NET临时关闭这个 ...
- Mysql-安装指南
1.设置用户名密码 首次登录后修改密码如下: 如果密码设置太过简单会报以下错误 mysql修改密码Your password does not satisfy the current policy r ...
- Fastify 系列教程二 (中间件、钩子函数和装饰器)
Fastify 系列教程: Fastify 系列教程一 (路由和日志) Fastify 系列教程二 (中间件.钩子函数和装饰器) Fastify 系列教程三 (验证.序列化和生命周期) Fastify ...
- Eigen 学习之块操作
Eigen 为 Matrix .Array 和 Vector提供了块操作方法.块区域可以被用作 左值 和 右值.在Eigen中最常用的块操作函数是 .block() . block() 方法的定义如 ...
- UPDATE语句总结
一.基本语句 1.SQL UPDATE 语法 UPDATE table_name SET column1 = value1, column2 = value2, ... WHERE condition ...
- windows 端口映射
netsh interface portproxy add v4tov4 listenport=8765 listenaddress=0.0.0.0 connectaddress=172.19.24. ...
- [翻译] Icon and Image Sizes
Icon and Image Sizes iOS Human Interface Guidelines Every app needs an app icon and a launch file or ...
- 模仿SDWebImage实现异步加载图片
模仿SDWebImage实现异步加载图片 SDWebImage想必大家都不陌生吧,要实现它的图片异步加载功能这个还是很简单的. 注意:此处我只实现了异步加载图片,并没有将文件缓存到本地的打算哦:) 源 ...
- Linux系统清除多余的账号
清除多余的账号 注释掉/etc/passwd文件中nologin的行 grep 'nologin' /etc/passwd 注: 目前暂没想到用命令行替换,后面再想想
- php中查询时间
在做查询过程中,例如要实现查上个月从第一天到最后一天的佣金(提成),那我们在程序实现过程中就要让程序在上个月的范围内查询,第一天是比较好办,但最后一天就不定,要去写段函数进行月份及年份判断来得出上个月 ...