HyperLogLog in Practice: Algorithmic Engineering of a State of The Art Cardinality Estimation Algorithm
HyperLogLog参考下面这篇blog,
http://blog.codinglabs.org/articles/algorithms-for-cardinality-estimation-part-iv.html
为何LLC在基数不大的时候会误差比较大?
直观上,由于基数不大时,会有很多空桶,而最终结果是求平均值,这个值对离群值(这里的0)非常敏感
那么重理论上看,为何误差比较大?
LLC的渐近标准误差为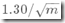 ,看上去只是和桶数m有关,为何还和基数大小有关?
,看上去只是和桶数m有关,为何还和基数大小有关?
关键就是理解渐近标准误差,
标准误差,(个人理解)
对于估计,真实值和预测值之间一定有误差的,这种误差往往符合高斯分布(根据中心极限定理)
而高斯分布的参数 ,就是表示标准误差,因为这个参数表示高斯分布的宽窄,所以
,就是表示标准误差,因为这个参数表示高斯分布的宽窄,所以 越小,表示高斯分布越收拢,即越多的预测值会更接近均值
越小,表示高斯分布越收拢,即越多的预测值会更接近均值 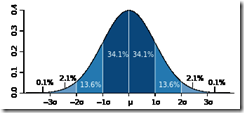
所以标准误差是可以用来衡量模型预测质量好坏的,所以如果LLC的标准误差为,那么该算法的误差只和桶数m相关
但是这里“渐近”两个字,表示只有当基数n趋向于无穷大,标准差才趋向于
这就解释了前面的问题
所以解决这个问题两个改进算法,
Adaptive Counting,简单的想法,在n比较小的时候使用linear counting,n比较大的时候用LLC
HyperLogLog Counting,比较复杂的方法,参考“HyperLogLog: the analysis of a near-optimal cardinality estimation algorithm”
基本的改进是使用调和平均数替代几何平均数,以减少对离群值的敏感性
---------------------------------------------------------------------------------------------------------------------------------------------------------------
传统的cardinality统计的方法过于耗费内存, 所以有很多近似的方法以比较低的资源耗费来解决这个问题
在Goolge,每天都会有如下数据分析系统需要对非常大的数据集做cardinality估计,所以google对HyperLogLog做了一系列的improvement。
At Google, various data analysis systems such as Sawzall [15], Dremel [13] and PowerDrill [9] estimate the cardinality of very large data sets every day, for example to determine the number of distinct search queries on google.com over a time period.
Google做了一系列的实验对比,从准确率上来看,Linear counting是最好的,所以当数据量不大的时候首选
但是当基数的取值很大的时候,空间效率上看是有问题的,所以还是选择准确率稍差的HLLC
算法设计的Goal是,
Therefore, the key requirements for a cardinality estimation algorithm can be summarized as follows:
• Accuracy.
For a fixed amount of memory, the algorithm should provide as accurate an estimate as possible. Especially for small cardinalities, the results
should be near exact.
• Memory efficiency.
The algorithm should use the available memory efficiently and adapt its memory usage to the cardinality. That is, the algorithm should use less
than the user-specified maximum amount of memory if the cardinality to be estimated is very small.
• Estimate large cardinalities.
Multisets with cardinalities well beyond 1 billion occur on a daily basis, and it is important that such large cardinalities can be estimated with reasonable accuracy.
• Practicality.
The algorithm should be implementable and maintainable.
HLLC算法
相对于LLC的n的公式,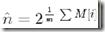
HLLC前面的步骤都是一样,只是最后的计算公式,用调和平均数
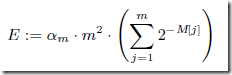 ,其中
,其中
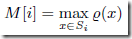
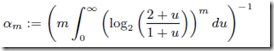
并且在实现的时候做了如下的优化,主要是指n很小和很大时,做些特殊化处理
1. Initialization of registers.
The registers are initialized to 0 instead of  to avoid the result 0 for n << mlogm where n is the cardinality of the data stream (i.e., the value we are trying to estimate).
to avoid the result 0 for n << mlogm where n is the cardinality of the data stream (i.e., the value we are trying to estimate).
2. Small range correction.
Simulations by Flajolet et. al. show that for  nonlinear distortions appear that need to be corrected.
nonlinear distortions appear that need to be corrected.
Thus, for this range LinearCounting [16] is used.
3. Large range corrections.
When n starts to approach  , hash collisions become more and more likely (due to the 32 bit hash function). To account for this, a correction is used.
, hash collisions become more and more likely (due to the 32 bit hash function). To account for this, a correction is used.
Google对HLLC的提高
1. Using a 64 Bit Hash Function
这个很容易理解,google需要处理的cardinalities beyond 1 billion,所以原来的32bit不够
2.Estimating Small Cardinalities
对于很小的cardinalities,之前的处理是,当就使用Linear counting
这里提出一种bias-corrected的方法,文章中实验如下,
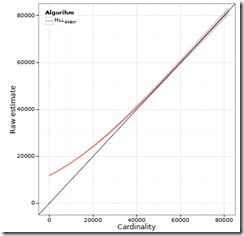
Our experiments show that at the latest for n > 5m the correction does no longer reduce the error significantly.
所以在n> 5m的时候,直接用HLLC就ok
但是当n<5m时,文章中试图用他们的实验数据去把bias修正掉
再次测试结果是,尽管这样,在n很小的情况下,仍然是Linear counting的效果比较好 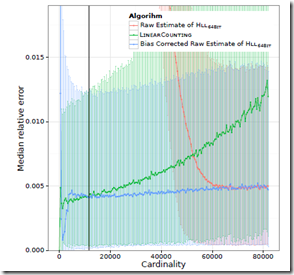
所以最终的逻辑是
当n<5m时,会优先使用bias-corrected的方法, 只有当出现空桶,即n很小的情况下,才使用linear counting
3.Sparse Representation
这组优化关键就是更加节省空间,其实HLLC对空间的耗费本身就不高,但是由于google的基数实在太大导致桶数也非常大, 所以再小的值乘上个超大的基数也扛不住
优化都比较简单,
1. 当n<<m,情况下,即有很多空桶,那不用记录每个桶的情况,只需要记录有数据的桶,就是稀疏表示,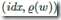
2. 在稀疏表示的情况下,可以使用更多位数来表示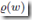 ,以达到更高的precision
,以达到更高的precision
3. 进一步压缩稀疏表示
4. 在linear counting的情况下,其实不需要记录
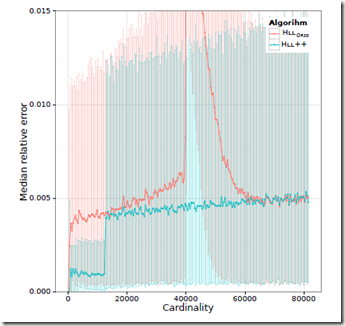
最终HLLC和google的HLLC++的数据对比
HyperLogLog in Practice: Algorithmic Engineering of a State of The Art Cardinality Estimation Algorithm的更多相关文章
- Image Processing and Analysis_8_Edge Detection:Edge and line oriented contour detection State of the art ——2011
此主要讨论图像处理与分析.虽然计算机视觉部分的有些内容比如特 征提取等也可以归结到图像分析中来,但鉴于它们与计算机视觉的紧密联系,以 及它们的出处,没有把它们纳入到图像处理与分析中来.同样,这里面也有 ...
- 翻新并行程序设计的认知整理版(state of the art parallel)
近几年,业内对并行和并发积累了丰富的经验.有了较深刻的理解.但之前积累的大量教材,在当今的软硬件体系下.反而都成了负面教材.所以,有必要加强宣传,翻新大家的认知. 首先.天地倒悬,结论先行:当你须要并 ...
- 大数据下的Distinct Count(一):序
在数据库中,常常会有Distinct Count的操作,比如,查看每一选修课程的人数: select course, count(distinct sid) from stu_table group ...
- 资源list:Github上关于大数据的开源项目、论文等合集
Awesome Big Data A curated list of awesome big data frameworks, resources and other awesomeness. Ins ...
- Awesome Big Data List
https://github.com/onurakpolat/awesome-bigdata A curated list of awesome big data frameworks, resour ...
- Redis数据结构之HperLogLog
一.HyperLogLog HyperLogLog是用来做基数统计的. 其可以非常省内存的去统计各种计数,比如注册ip数.每日访问IP数.页面实时UV(PV肯定字符串就搞定了).在线用户数等在对准确性 ...
- 【原创】大叔算法分享(4)Cardinality Estimate 基数计数概率算法
读过<编程珠玑>(<Programming Pearls>)的人应该还对开篇的Case记忆犹新,大概的场景是: 作者的一位在电话公司工作的朋友想要统计一段时间内不同的电话号码的 ...
- HyperLogLog
数据量一大,连统计基数也成了一个麻烦事.在使用kylin的时候,遇到对度量值进行基数统计,使用的是Hyperloglog算法,占用内存小,误差小,实乃不错的方法,但查阅网上的资料与内容,感觉未能理解的 ...
- Reids(4)——神奇的HyperLoglog解决统计问题
一.HyperLogLog 简介 HyperLogLog 是最早由 Flajolet 及其同事在 2007 年提出的一种 估算基数的近似最优算法.但跟原版论文不同的是,好像很多书包括 Redis 作者 ...
随机推荐
- 当点击onBackpress方法或者onKeyDown方法时出现不能响应的问题解决办法
一般来讲,当我们点击手机上的back键之后,会直接调用activity的onbackpress()方法,或者我们也可以通过这样来进行捕捉点击事件 @Override public boolean on ...
- VC++使用CSocket发送HTTP Request时需要注意发送数据的编码格式
VS2010以及更高版本中新建的MFC项目字符集默认是Unicode,CString创建的字符串默认是Unicode. 使用CSocket时,若以CString组织需要发送的HTTP Head时,那么 ...
- while(scanf("%d",&n)!=EOF)与while(cin>>n)
我们知道scanf函数是C语言里面的,其返回值是,被输入函数成功赋值的变量个数.针对于int counts = scanf("%d",&n);来说如果赋值成功那么其返回值 ...
- 快速找出System.Management.Automation.dll,c#调用powershell
public static void InvokeSystemPS(string cmd) { List<string> ps = new List<string>(); ps ...
- svn merge和branch分析
[转载] 使用svn几年了,一直对分支和合并敬而远之,一来是因为分支的管理不该我操心,二来即使涉及到分支的管理,也不敢贸然使用合并功能,生怕合并出了问题对团队造成不良影响,最主要的原因是,自己对分支的 ...
- Hyperic-Sigar简介
Hyperic-Sigar是一个收集系统各项底层信息的工具集.他有如下特点:1. 收集信息全面收集CPU,MEM,NETWORK,PROCESS,IOSTAT等使用Sigar,你完全可以模仿出cpui ...
- ios iOS手势识别的详细使用(拖动,缩放,旋转,点击,手势依赖,自定义手势)
iOS手势识别的详细使用(拖动,缩放,旋转,点击,手势依赖,自定义手势) 转自容芳志大神的博客:http://www.cnblogs.com/stoic/archive/2013/02/27/2940 ...
- ios 气泡聊天
最近做的项目里面,有几个模块用到了聊天功能和评论回复的功能,使用的频率还是很高的,所以抽时间做了这个博客,希望能给自己和别人带来方便, 具体代码如下: 1,创建model, #import <F ...
- 测试用例和BUG描述规范
欢迎关注我的公众号,了解更多的测试知识:[软件测试经验与教训] 一一BUG描述基础知识 Bug标题中需包含Bug的具体位置并以[]标注 举例:[模块-子模块-页面]XXXXXXXXXXXX Bug标题 ...
- excel中,一系列单元格中包含某一个字段的单元格数量?
excel中,一系列单元格中包含某一个字段的单元格数量?这个怎么写公式?如:A列单元格A1-A7的内容分别为 A.AB.BC.AC.CD.AD.EA,怎么数这一列中几个单元格的内容包含A字母? 任意单 ...