loadrunner12--学习中遇到疑问及解释
1、analysis里面,平均事务响应时间,平均事务响应时间+运行vuser,两个图的数据有区别是什么原因?
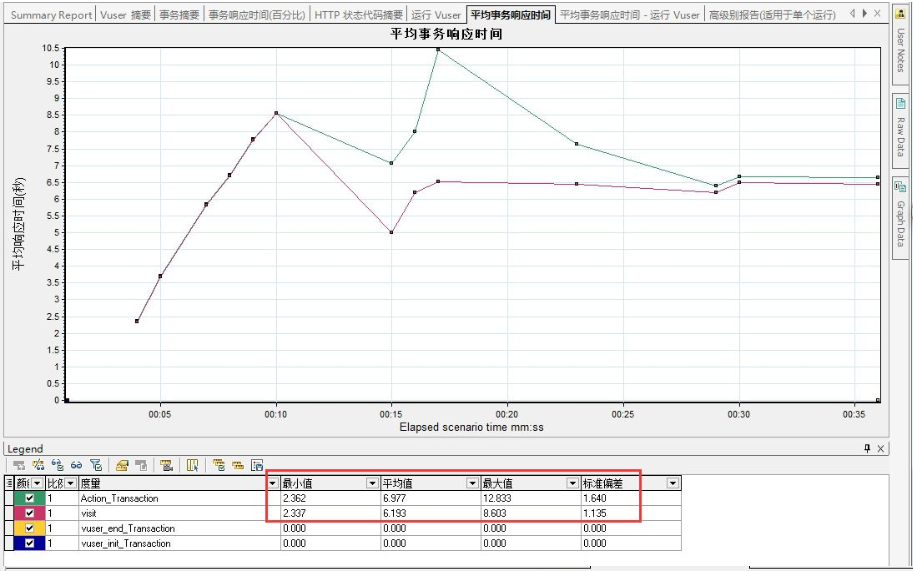
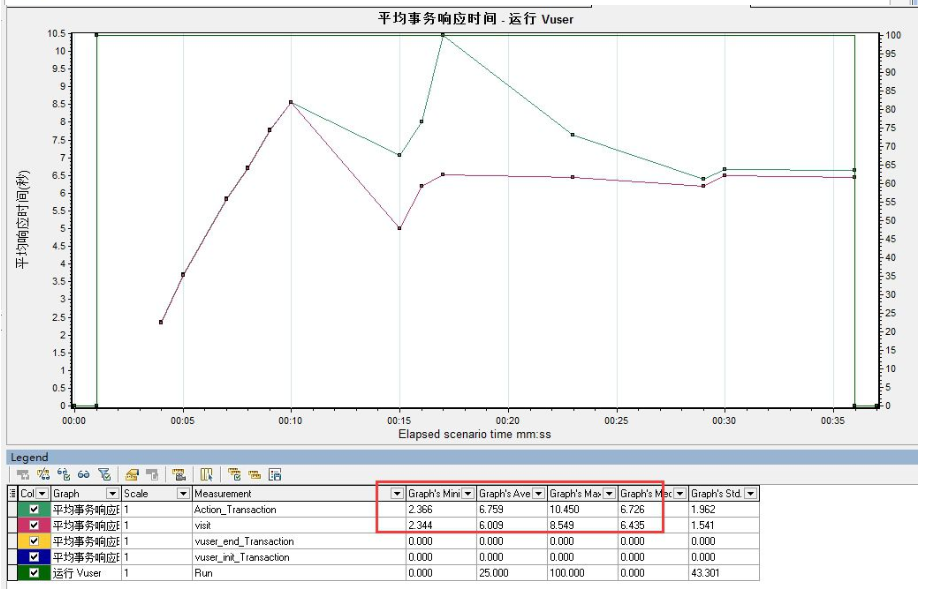
答:
请仔细查看以下两张图,其实两张图的数据是没有区别的。
之所以我们认为他们二者的数据有区别,是因为度量的标准不同。
第一张图显示的是最大值、最小值以及平均值。
而第二张图显示的数据确是图表的最大值、图表的最小值、图表的平均值。
所以看起来二者的数据有区别。
但是若将第二张图的度量添加了最大值、最小值以及平均值,可以看到数据是相同的。(在列表空白处单击鼠标右键--configure columns--在“最小值”“最大值”“平均值”前面打上勾)
**图最小值和最小值,图最小值是基于图表中的数据点来计算的,最小值统计的数据是基于全部的采样数据计算的,采样的数据空间不一样。
同理,Summary和平均事务响应时间图里的图最大,图平均,图最小值,之所以不一样是因为采样不一样。
秒。
如果让他们的采样时间是一样的,平均也就会完全一样了。
Summary是按整个场景的时间来做平均的,最大最小值,也是从整个场景中取出来的。
而平均事务响应时间图里,是按频率来取值。这两个值没有什么可比性。也没有什么关系。
只是一堆数据的不同计算方法。在取样时间内,有可能比summary里的高,有可能低,有可能持平,这都是很偶然的。
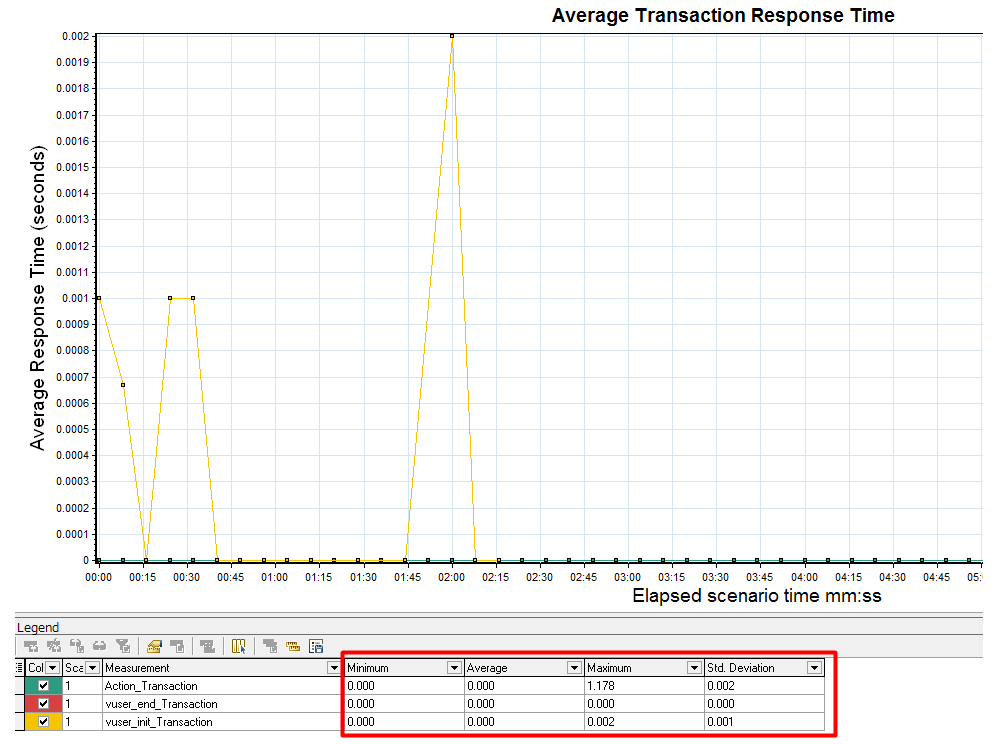
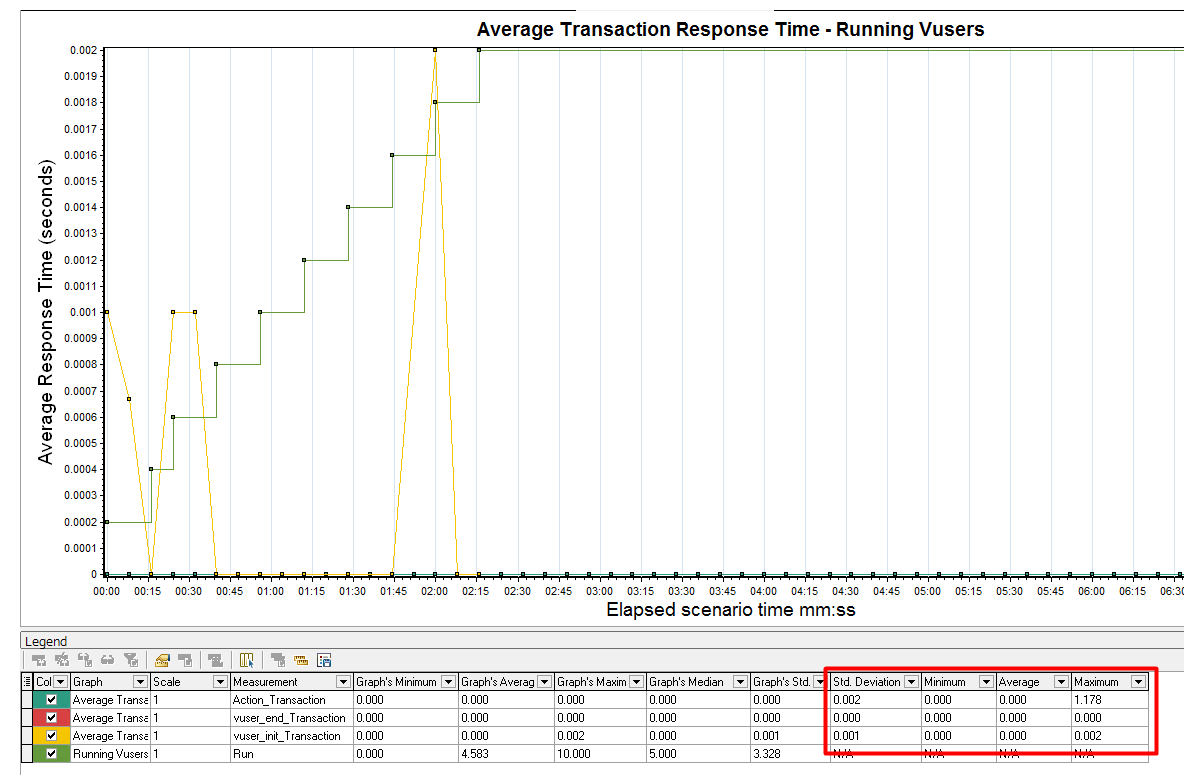
2、测试的系统,包含了html5动画,js动画等浏览器渲染效果,这种情况下怎么考虑平均事务响应时间?
答:LR是基于请求的,计算时间的方式是第一个字节出去到最后一个字节回来,它不可能知道在浏览器上做了什么事情的。(云层回答)
1)平均事务响应时间:是包括服务器响应时间、网络连接时间、网络延迟时间等。
2)网络正常的情况下,一个加载页面的操作,响应时间应该只会比服务器响应时间多零点几秒。但是要是有网络延迟,那就要看网络延迟多少了,有时候延迟10秒多都是正常的。
3)事务响应时间比较高的时候,需要考虑脚本里是否有思考时间,LR本身消耗的时间waste time(这个时间脚本跑完可以看到,这个消耗时间对访问网页来说几乎可以忽略,除非那种很复杂的下载文件之类才会产生消耗),如果去除前面说的这些时间,响应还是很多,那就是不正常了。
总结来说,就是不管网页有啥动画效果,对lr测试后整理的报告来说都是没有影响的,报告里的时间会把所有乱七八糟的时间都去除。要是有网络延迟,会计算延迟的时间,但是正常服务器的响应时间,也是要计算延迟的,LR模拟的就是这个真实的时间。最理想的测试性能情况应该是最符合真是的环境;公网是正常的情况下,公网测试出来的结果也就是网页中实际可以承受的压力。
3、loadrunner运行压力测试,比如对一个表单进行100并发压力测试提交数据,那么按理来说应该成功提交了100条数据才对。
答:这个问题有待验证。
验证后确实如此,例如参数化10条数据,在vugen中回放,就会成功提交10条数据,如果没有成功提交到数据库,那么这个压力测试是有问题的。
loadrunner12--学习中遇到疑问及解释的更多相关文章
- 关于 knockout js 学习中的疑问 (1)
最近刚刚学习knockout中遇到如下问题: 1.在给viewModel定义一个方法时,有时后面跟 的this,有的时候没有 如下所示: this.fullName = ko.computed(fun ...
- c++学习中的疑问
1.关于iostream头文件中的cout对象没有包含对string的<<操作符重载函数 测试代码: #include<iostream> using namespace st ...
- ASPNET_MVC学习中的疑问
1.在mvc..net4.5.Entity Framewor都提供了多种验证规则. 请问,其中不需要提交到服务器验证的验证,是否是在客户端就完成的,还是说像之前的aspnet一样,都得提交到服务器验 ...
- 卷积在深度学习中的作用(转自http://timdettmers.com/2015/03/26/convolution-deep-learning/)
卷积可能是现在深入学习中最重要的概念.卷积网络和卷积网络将深度学习推向了几乎所有机器学习任务的最前沿.但是,卷积如此强大呢?它是如何工作的?在这篇博客文章中,我将解释卷积并将其与其他概念联系起来,以帮 ...
- 有关JAVA基础学习中的集合讨论
很高兴能在这里认识大家,我也是刚刚接触后端开发的学习者,相信很多朋友在学习中都会遇到很多头疼的问题,希望我们都能够把问题分享出来,把自己的学习思路整理出来,我们一起探讨一起成长. 今天我 ...
- Android 布局学习之——Layout(布局)具体解释二(常见布局和布局參数)
[Android布局学习系列] 1.Android 布局学习之--Layout(布局)具体解释一 2.Android 布局学习之--Layout(布局)具体解释二(常见布局和布局參数) ...
- 深度学习中dropout策略的理解
现在有空整理一下关于深度学习中怎么加入dropout方法来防止测试过程的过拟合现象. 首先了解一下dropout的实现原理: 这些理论的解释在百度上有很多.... 这里重点记录一下怎么实现这一技术 参 ...
- 深度学习中交叉熵和KL散度和最大似然估计之间的关系
机器学习的面试题中经常会被问到交叉熵(cross entropy)和最大似然估计(MLE)或者KL散度有什么关系,查了一些资料发现优化这3个东西其实是等价的. 熵和交叉熵 提到交叉熵就需要了解下信息论 ...
- 深度学习中的Normalization模型
Batch Normalization(简称 BN)自从提出之后,因为效果特别好,很快被作为深度学习的标准工具应用在了各种场合.BN 大法虽然好,但是也存在一些局限和问题,诸如当 BatchSize ...
随机推荐
- IO流常规操作
IO流 IO就是输入输出,IO设备在计算机中起着举足轻重的作用,IO流也就是输入输出流,用来交互数据,程序和程序交互,程序也可以和网络等媒介交互. 一.IO流的分类 要分类,肯定得站得不同角度来看这个 ...
- web本地存储(localStorage、sessionStorage)
web 本地存储 (localStorage.sessionStorage) 说明 对浏览器来说,使用 Web Storage 存储键值对比存储 Cookie 方式更直观,而且容量更大,它包含两种:l ...
- windows server 2012 AD 域和站点部署系列
http://blog.csdn.net/ronsarah/article/category/1495599 http://blog.csdn.net/david_520042/article/cat ...
- 我的第一个php扩展
一.进入php源码包,找到ext文件夹 cd /owndata/software/php-5.4.13/ext 文件夹下放的都是php的相关扩展模块 二.生成自己的扩展文件夹和相关文件 php支持开发 ...
- wheezy下安装emacs24
wget -q -O - http://emacs.naquadah.org/key.gpg | sudo apt-key add - vim /etc/apt/sources.list 添加 deb ...
- Java 遍历文件夹里面的全部文件、指定文件
Java 手册 listFiles public File[] listFiles(FileFilter filter) 返回抽象路径名数组,这些路径名表示此抽象路径名表示的目录中满足指定过滤器的文件 ...
- 利用VMware在虚拟机上安装Zookeeper集群
http://blog.csdn.net/u010246789/article/details/52101026 利用VMware在虚拟机上安装Zookeeper集群 pasting
- php调用dll经验小结
最近做一个网站,需要频繁使用远程数据,数据接口已经做好.在做转换的时候遇到了性能上的问题:开始打算用php来实现转换,苦苦查了数天,都没有找到直接操作字节的方法.虽然可以使用 pack() 方法将各个 ...
- java DecimalFormat类
今天去面试了,需要上机做题.题目的内容是计算一个货物订单的税费和总价格(包括税费),结果需要精确到两个小数,同时按照如下规则进行处理: 3.01 ——>3.05, 2.48——> ...
- 认识Linux操作系统
Linux系统是一个类似UNIX的操作系统 认识Linux的来世与今生 1.Linux系统的历史 Linux系统是一个类似UNIX的操作系统,Linux系统是UNIX在微机上的完整实现,它的标志是一个 ...