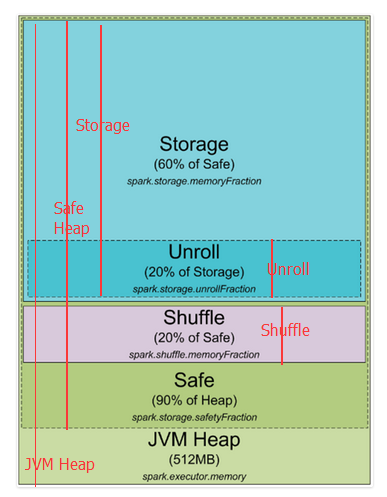
这是spark1.5及以前堆内存分配图
下边对上图进行更近一步的标注,红线开始到结尾就是这部分的开始到结尾
spark 默认分配512MB JVM堆内存。出于安全考虑和避免内存溢出,Spark只允许我们使用堆内存的90%,这在spark的spark.storage.safetyFraction 参数中配置着。也许你听说的spark是一个内存工具,Spark允许你存储数据在内存。其实,Spark不是真正的内存工具,它只是允许你使用内存的LRU(最近最少使用)缓存 。所以,一部分内存要被用来缓存你要处理的数据,这部分内存占可用安全堆内存的60%,这个值在spark.storage.memoryFraction参数中配置。所以如果你想知道你可以存多少数据在spark中,spark.storage.safetyFraction 默认值为0.9,spark.storage.memoryFraction的默认值为0.6,
Storage=总堆内存*0.9*0.6,所以你有54%的堆内存用来存储数据。
shuffle内存:
spark.shuffle.safetyFraction * spark.shuffle.memoryFraction
spark.shuffle.safetyFraction默认为0.8或80%,spark.shuffle.memoryFraction默认为0.2或20%,则你最终可以使用0.8*0.2=0.16或16%的JVM 堆内存用于shuffle。
Unroll内存:
spark允许数据以序列化或非序列化的形式存储,序列化的数据不能拿过来直接使用,所以就需要先反序列化,即unroll。
Heap Size*spark.storage.safetyFraction*spark.storage.memoryFraction*spark.storage.unrollFraction=Heap Size *0.9*0.6*0.2=Heap Size * 0.108或10.8%的JVM 堆内存。
到此为止,你应该就知道Spark是如何使用jvm内存的了,下边是集群模式,以yarn为例,其它类似。
在Yarn集群中,Yarn Resource Manager管理集群的资源(实际就是内存)和一系列运行在集群Node上yarn resource manager及集群Nodes资源的使用。从YARN的角度,每一个 Node都代表了一个可控制的内存资源,当你向Yarn Resource Manager申请资源时,它会反馈给你哪个yarn node manager 可以连接并启动一个execution container给你。每一个execution container都是一个可以提供堆内存的JVM,JVM的位置是由Yarn Resource manager选择的。
当你在Yarn上启动Spark时,你可以指定executor的数量(–num-executors flag or spark.executor.instances parameter)、每个executor的内存大小(–executor-memory flag or spark.executor.memory parameter)、每个executor的内核数量(–executor-cores flag of spark.executor.coresparameter)、每个task执行的内核数量(spark.task.cpusparameter),你也可以指定driver的内存大小(–driver-memory flag or spark.driver.memory parameter)。
当你在集群中执行某项任务时,一个job会被切分成stages,每个stage会被分成多个task,每个task会被单独分配,你可以把这些executor看成一个个执行task的槽池(a pool of tasks execution slots)。如下看一个例子:一个集群有12个节点(yarn node manager),每个节点有64G内存、32核的CPU(16个物理内核,一个物理内核可以虚拟成两个)。每个节点你可以启动两个executors、每个executor分配26G内存(留一部分用于system process、yarn NM、DataNode).所以集群一共可以处理 12 machines * 2 executors per machine * 12 cores per executor / 1 core for each task = 288 task slots。这意味着该集群可以并行运行288个task,充分利用集群的所有资源。你可以用来存储数据的内存为= 0.9 spark.storage.safetyFraction * 0.6 spark.storage.memoryFraction * 12 machines * 2 executors per machine * 26 GB per executor = 336.96 GB。没有那么多,但是也足够了。
到此,你已经知道spark如何分配 jvm内存,在集群中可以有多少个execution slots。那么什么是task,你可以把他想像成executor的某个线程,executor是一个进程 ,它可以多线程的执行task.
下边来解释一下另一个抽象概念"Partition",你用来分析的所有数据都将被切分成partitions,那么何为一个partition,它又是由什么决定的?partition的大小是由你使用的数据源决定的,在spark中你可以使用的所有读取数据的方式,大多你可以指定你的RDD中有多少个partitions。当你从HDFS中读取一个文件时,hadoop的InputFormat决定partition。通常由InputFormat输入的每一个 split对应于RDD中的一个partition,而每一个split通常相当于hdfs中的一个block(还有一些其它情况,暂不解释,如text file压缩后传过一整个partition不能直接使用)。
一个partition产生一个task,并在数据所在的节点task slot执行(数据本地性)
语言组织不是特别好,请见谅,如有失误之处,还请多提宝贵意见。
- JVM系列(1)- JVM常见参数及堆内存分配
常见参数配置 基于JDK1.6 -XX:+PrintGC 每次触发GC的时候打印相关日志 -XX:+UseSerialGC 串行回收模式 -XX:+PrintGCDetails 打印更详细的GC日志 ...
- java字符串池和字符串堆内存分配
1. String str=new String("abc")和String str="abc"的字符串“abc”都是存放在堆中,而不是存在 栈中. 2. 其实 ...
- jvm 虚拟机参数_堆内存分配
1.参数 -XX:+PrintGC 只要遇到 GC 就会打印日志 -XX:+UseSerialGC 配置串行回收器 -XX:+PrintGCDetails 查看详细信息,包括各个区的情况 -XX:+P ...
- java中内存分配策略及堆和栈的比较
Java把内存分成两种,一种叫做栈内存,一种叫做堆内存 在函数中定义的一些基本类型的变量和对象的引用变量都是在函数的栈内存中分配.当在一段代码块中定义一个变量时,java就在栈中为这个变量分配内存空间 ...
- JAVA基础-栈与堆,static、final修饰符、内部类和Java内存分配
Java栈与堆 堆:顺序随意 栈:后进先出(Last-in/First-Out). Java的堆是一个运行时数据区,类的对象从中分配空间.这些对象通过new.newarray.anewarray和mu ...
- 目录_Java内存分配(直接内存、堆内存、Unsafel类、内存映射文件)
1.Java直接内存与堆内存-MarchOn 2.Java内存映射文件-MarchOn 3.Java Unsafe的使用-MarchOn 简单总结: 1.内存映射文件 读文件时候一般要两次复制:从磁盘 ...
- ACE服务端编程3:ACE跨平台之分配堆内存
ACE服务端编程系列的第三篇,探究ACE解决不同编译器之间分配堆内存的差异. 在ACE的官方示例中会看到大量的ACE_NEW_RETURN,ACE_NEW这样的宏,这是ACE为了消除不同编译器编译的代 ...
- Unix系统编程()在堆上分配内存
在堆上分配内存:malloc和free 一般情况下,C程序使用malloc函数族在堆上分配和释放内存.较之brk和sbrk,这些函数具备不少优点: 属于C语言标准的一部分 更易于在多线程程序中使用 接 ...
- Java中堆内存与栈内存分配浅析
Java把内存划分成两种:一种是栈内存,另一种是堆内存.在函数中定义的一些基本类型的变量和对象的引用变量都是在函数的栈内存中分配,当在一段代码块定义一个变量时,Java就在栈中为这个变量分配内存空间, ...
随机推荐
- 用WM_COPYDATA消息来实现两个进程之间传递数据
文着重讲述了如果用WM_COPYDATA消息来实现两个进程之间传递数据. 进程之间通讯的几种方法:在Windows程序中,各个进程之间常常需要交换数据,进行数据通讯.常用的方法有 1.使用内存映射 ...
- ab并发负载压力测试
一.ab 0.安装ab压力测试软件 [root@a2 conf]# yum install httpd-tools -y #查看版本 [root@a2 conf]# ab -V This is Apa ...
- Kudu – 在快数据上的进行快分析的存储
转自: http://www.tuicool.com/articles/nmYf2uf Cloudera Impala Kudu – 在快数据上的进行快分析的存储 Kudu,对应中文的含义应该 ...
- 【云计算】Ubuntu14.04 搭建GlusterFS集群
1.修改 /etc/hosts 所有服务节点执行(如果集群中没有DNS,可忽略此步骤): 10.5.25.37 glusterfs-1-5-25-3710.5.25.38 glusterfs-2-5- ...
- 异常解决:util.NativeCodeLoader: Unable to load native-hadoop library for your platform
内容源自:点此链接 刚装好hadoop的时候,每次输入命令运行都会出现: WARN util.NativeCodeLoader: Unable to load native-hadoop librar ...
- idea启动dubbo
jetty 方式启动dubbo. 首先为dubbo 添加jetty mven 插件: http://www.eclipse.org/jetty/documentation/current/jetty- ...
- const 与 指针
#include <iostream> using namespace std; int main() { // 第一种.使指针不能改动对象的值.注:此时指针能够指向另外的对象 int i ...
- OpenCV 之 霍夫变换
Hough 变换,对图像中直线的残缺部分.噪声.以及其它的共存结构不敏感,因此,具有很强的鲁棒性. 它常用来检测 直线和曲线 (圆形),识别图像中的几何形状,甚至可用来分割重叠或有部分遮挡的物体. 1 ...
- java运行shell命令,chmod 777 xxx,改变权限无效的解决的方法。
在java程序中运行shell命令,改变文件的权限.能够在命令行中运行 chmod 777 <span style="font-family: Arial, Helvetica, sa ...
- 详解php的魔术方法__get()和__set()
先看看php官方文档的解释:__set() is run when writing data to inaccessible properties.__get() is utilized for re ...