二 Hive分桶
二.Hive分桶
1.创建分桶表
create table t_buck (id string ,name string)
clustered by (id) //根据id分桶
sorted by (id) //根据id排序
into 4 buckets //分为4个桶
row format delimited
fields terminated by ',';
向创建的分桶表中插入数据需要是已分桶且排序的。通常是将其他表查询的结果插入桶中才会执行分桶操作。分桶的原理和分区原理差不多,类似HashPartitioner。
2.向分桶表中导入其他表查询后的数据
select id ,name from t_shizhan01 distribute by (id) sort by (id);
或者
insert into t_buck
select id ,name from t_shizhan01 cluster by (id);
可以使用distribute by(id) sort by(id asc) 或是排序和分桶的字段相同的时候使用Cluster by(字段)
注意使用cluster by 就等同于分桶+排序(sort)
3.设置变量,设置分桶为true, 设置reduce数量是分桶的数量个数
set hive.enforce.bucketing = true;
set mapreduce.job.reduces=4;
设置是否分桶及设置reduce的数量。在创建表的时候设置的分桶数量要和此处设置的相匹配,如果此处不设置reduce数量和是否分桶,表对应的空间中只会有一个桶。
执行插入操作后hdfs目录如下:
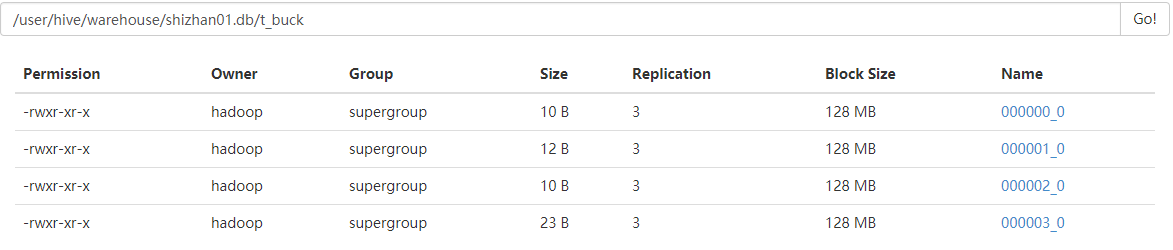
二 Hive分桶的更多相关文章
- Hive分桶
1.简介 分桶表是对列值取哈希值的方式将不同数据放到不同文件中进行存储.对于hive中每一个表,分区都可以进一步进行分桶.由列的哈希值除以桶的个数来决定数据划分到哪个桶里. 2.适用场景 1.数据抽样 ...
- hive分桶 与保存数据的方式
创建分桶的表 create table t_buck(id int ,name string) clustered by (id ) sorted by (id) into 4 buckets ; ...
- hive分桶表bucketed table分桶字段选择与个数确定
为什么分桶 (1)获得更高的查询处理效率.桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构.具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map ...
- hive 分桶及抽样调查
1.分桶的概述 分区提供了一个隔离数据和优化查询的遍历方式.不是所有的数据集都可形成合力的分区 对于一张表或者分区,hive可以进一步组织成桶,也就是更为细粒度的数据范围 分区针对的是数据的存储路径( ...
- Hive 学习之路(五)—— Hive 分区表和分桶表
一.分区表 1.1 概念 Hive中的表对应为HDFS上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大. 分区为HDFS上表目录的子目录,数据按照分区存储在子目录中.如 ...
- Hive 系列(五)—— Hive 分区表和分桶表
一.分区表 1.1 概念 Hive 中的表对应为 HDFS 上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大. 分区为 HDFS 上表目录的子目录,数据按照分区存储在子 ...
- 入门大数据---Hive分区表和分桶表
一.分区表 1.1 概念 Hive 中的表对应为 HDFS 上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大. 分区为 HDFS 上表目录的子目录,数据按照分区存储在子 ...
- Hive分区表与分桶
分区表 在Hive Select查询中.通常会扫描整个表内容,会消耗非常多时间做不是必需的工作. 分区表指的是在创建表时,指定partition的分区空间. 分区语法 create table tab ...
- Hive动态分区和分桶(八)
Hive动态分区和分桶 1.Hive动态分区 1.hive的动态分区介绍 hive的静态分区需要用户在插入数据的时候必须手动指定hive的分区字段值,但是这样的话会导致用户的操作复杂度提高,而且在 ...
随机推荐
- MQ--API总结
研究MQ很长时间了, 每个类,方法,都查了很长时间,在此总结一下! Java编写访问MQ的程序 1.MQQueueManager―――队列管理器访问类 常用方法: public MQQueueMan ...
- Django 导出csv文件 中文乱码问题
import csvimport codecsimport datetimefrom django.db import connectionfrom django.contrib.auth.model ...
- 【[ZJOI2006]物流运输】
一直不会做,觉得这是一道神题 于是万般无奈下去借鉴抄了一下题解 发现这就是一道套路题 我们用\(dp[i]\)表示前\(i\)天的最小总花费,于是我们就可以用一个常规的老套路来做了 那就是枚举断点 我 ...
- [19/04/06-星期六] 多线程_静态代理(StaticProxy)和 lamda (简化代码,jdk8新增)
一.静态代理 [代码示例] /*** * 静态代理:记录日志等,类是写好的,直接拿来用. 动态代理:随用随构建,临时抱佛脚 * 婚庆公司:代理角色,帮你搞婚庆的一切,布置房间等等 * 自己:真实角色, ...
- Jmeter--调度器配置
Jmeter的线程组设置里有一个调配器设置,用于设置该线程组下脚本执行的开始时间.结束时间.持续时间及启动延迟时间.当需要半夜执行性能测试时会用到这个功能. ps:设置调度器配置,需要将前面的循环次数 ...
- 解决pycharm无法导入本地包的问题
在用python写爬虫程序时,import 行无法通过,具体情况如下: pycharm运行程序后,程序pass了,但是出现了警告,如下图所示: 这是由于该程序不在根目录下,无法导入本地包,解决办法如下 ...
- HDU 1027 Ignatius and the Princess II(求第m个全排列)
传送门: http://acm.hdu.edu.cn/showproblem.php?pid=1027 Ignatius and the Princess II Time Limit: 2000/10 ...
- 【转载】iPhone屏幕尺寸、分辨率及适配
iPhone屏幕尺寸.分辨率及适配 转载http://m.blog.csdn.net/article/details?id=42174937 1.iPhone尺寸规格 iPhone 整机宽度Width ...
- STM32F103片外运行代码分析
STM32F103片外运行代码分析 STM32F103有三种启动方式: 1.从片内Flash启动: 2.从片内RAM启动: 3.从片内系统存储器启动,内嵌的自举程序,用于串口IAP. 无法直接在片外N ...
- 阿里云修改主机名(以centOS为例)
需要更改配置文件生效,修/etc/sysconfig/network里的 HOSTNAME=主机名(可自定义),重启生效. 如何修改? 1.[root@aliyunbaike ~]# cd /etc/ ...