ElasticSearch(1)---Logstash同步Mysql数据到ElasticSearch
1. 单机部署-场景描述
elasticsearch只用过,没有部署或者维护过,从头完整走一遍,记录下,原创实战,有需要的朋友参考下。
2 . 解决方案
特别说下,以前win7下安装的3台虚拟机,没有联网,因为要安装elasticsearch-head需要安装前端报,调整为联网,安装yum、npm等,碰到了很多奇葩的问题,后续有时间发下。
2.1 下载
(1) 下载地址:https://www.elastic.co/cn/downloads/elasticsearch
(2) 下载效果图,282兆,还挺大的

2.2 部署es及启动
(1)上传目录
/opt
(2)解压
[root@w158 ~]# cd /opt/
[root@w158 opt]# tar -zxvf elasticsearch-7.6.2-linux-x86_64.tar.gz
[root@w158 opt]# mv elasticsearch-7.6.2 elasticsearch
(3)新增es操作账户
[root@w158 opt]# useradd laowang
[root@w158 opt]# passwd laowang
设置密码:
laowang
laowang
[root@w158 opt]# chown -R laowang:laowang /opt/elasticsearch
(4)修改配置文件
[root@w158 opt]# su laowang
[laowang@w158 opt]$ cd elasticsearch
[laowang@w158 elasticsearch]$ mkdir data
[laowang@w158 elasticsearch]$ cd config/
[laowang@w158 elasticsearch]$ cp elasticsearch.yml elasticsearch.yml.0328
#其余全部注释,直接复制进去,ip根据本机进行修改
vi elasticsearch.yml
discovery.seed_hosts: ["192.168.85.158"]
cluster.initial_master_nodes: ["node-1"]
cluster.name: es
node.name: node-1
path.data: /opt/elasticsearch/data
path.logs: /opt/elasticsearch/logs
network.host: 0.0.0.0
http.port: 9200
#discovery.zen.ping.unicast.hosts: ["192.168.85.158"]
http.cors.enabled: true
http.cors.allow-origin: "*"
(5)启动
[laowang@w158 elasticsearch]$ cd /opt/elasticsearch/bin
[laowang@w158 bin]$./elasticsearch -d
启动可能报错:
(1)ERROR: bootstrap checks failed
max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]
原因:无法创建本地文件问题,用户最大可创建文件数太小
解决方案:
切换到 root 用户,编辑 limits.conf 配置文件, 添加类似如下内容:
vi /etc/security/limits.conf
添加如下内容:
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
备注: * 代表 Linux 所有用户名称(比如 es)
保存、退出、重新登录才可生效
(2)max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least
[262144]
原因:最大虚拟内存太小
大讲台科技
- 2 -
解决方案:切换到 root 用户下,修改配置文件 sysctl.conf
vi /etc/sysctl.conf
添加下面配置:
vm.max_map_count=655360
并执行命令(配置生效):
sysctl -p
然后重新启动 elasticsearch,即可启动成功。
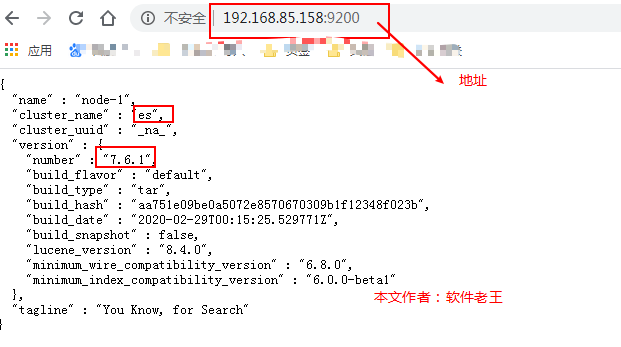
(6)启动效果
进程图:

启动成功:
一、安装elasticsearch和可视化工具
有关整个教程参考:mac安装elasticsearch和可视化工具
1、安装elasticsearch
网址地址:官网
2、安装elasticsearch-head(可视化界面)
安装地址:https://github.com/mobz/elasticsearch-head
3、安装Node.js
安装地址:Mac 下安装node.js
4、grunt-cli(3、4主要配合2实现可视化界面)
命令:sudo npm install -g grunt-cli (我的是安装在Mac上,所以其它不一定适用其它)
在终端运行: grunt --version(成功QQ图)

5、elasticsearch和elasticsearch-head整合
修改 elasticsearch.yml 文件,在文档的最末端加入
http.cors.enabled: true
http.cors.allow-origin: "*"
查看查看结果:输入:localhost:9100

这里说明整个已经安装成功并已经连接成功,green代表很健康
二、安装logstash并同步MySQL数据库
相关博客推荐:安装logstash并同步MySQL数据库
1、下载logstash
注意:下载的版本要和你的elasticsearch的版本号一致,我的版本elasticsearch6.3.2
2、配置logstash-jdbc-input
据说2.x以上就不用配置了,不过我还是配置了
3、添加mysql-connector驱动jar包
把这个jar包放入logstash中:mysql-connector-java-5.1.21.jar
4、添加配置文件(用于连接elasticsearch和mysql数据库)很重要!
具体的解释推荐博客:logstash input jdbc连接数据库
input {
stdin {
}
jdbc {
type => "news_info"
#后面的test对应mysql中的test数据库
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/news"
jdbc_user => "root"
jdbc_password => "root"
tracking_column => "auto_id"
record_last_run => "true"
use_column_value => "true"
#代表最后一次数据记录id的值存放的位置,它会自动在bin目录创建news,这个必填不然启动报错
last_run_metadata_path => "news"
clean_run => "false"
# 这里代表mysql-connector-java-5.1.21.jar放在bin目录
jdbc_driver_library => "mysql-connector-java-5.1.21.jar"
# the name of the driver class for mysql
jdbc_driver_class => "Java::com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "500"
statement => "select auto_id,title,content,up_count,down_count,origin_create_time,grade from t_live_news_origin where auto_id > :sql_last_value and similar_score>0.5"
#定时字段 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新
schedule => "* * * * *"
#设定ES索引类型
}
jdbc {
type => "press_info"
# mysql jdbc connection string to our backup databse 后面的test对应mysql中的test数据库
jdbc_connection_string => "jdbc:mysql:////127.0.0.1:3306/news"
jdbc_user => "root"
jdbc_password => "root"
tracking_column => "auto_id"
record_last_run => "true"
use_column_value => "true"
last_run_metadata_path => "news"
clean_run => "false"
jdbc_driver_library => "mysql-connector-java-5.1.21.jar"
jdbc_driver_class => "Java::com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "500"
statement => "select auto_id,title,source_mc,read_count,summary,summary_img,origin_create_time from t_live_press_origin where auto_id > :sql_last_value"
#定时字段 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新
schedule => "* * * * *"
}
}
filter {
mutate {
convert => [ "publish_time", "string" ]
}
date {
timezone => "Europe/Berlin"
match => ["publish_time" , "ISO8601", "yyyy-MM-dd HH:mm:ss"]
}
#date {
# match => [ "publish_time", "yyyy-MM-dd HH:mm:ss,SSS" ]
# remove_field => [ "publish_time" ]
# }
json {
source => "message"
remove_field => ["message"]
}
}
output {
if [type]=="news_info" {
elasticsearch {
#ESIP地址与端口
hosts => "127.0.0.1:9200"
#ES索引名称(自己定义的)
index => "wantu_news_info"
#自增ID编号
document_id => "%{auto_id}"
}
}
if [type]=="press_info" {
elasticsearch {
#ESIP地址与端口
hosts => "127.0.0.1:9200"
#ES索引名称(自己定义的)
index => "wantu_press_info"
#自增ID编号
document_id => "%{auto_id}"
}
}
}
#我这里的mysql.yml放到了bin的上层目录
./logstash -f ../mysql.yml
6、实际效果


连接成功,已经成功把MySQL数据库表中的数据存储到Elasticsearch中,并且logstash每一分钟去数据库读取最新数据。
最后看下我的logstash文件存放位置

三、坑和注意事项的总结
1、如下报错说明没有找到你的mysql-connectorjar包,很可能你的jar没有放到配置文件指定的目录。

2、需要重新让查询从0开始。
那就删除last_run_metadata_path => "news"的news文件,当然也要记得删除该索引好让它重新读取数据库表中数据。
相关其它坑博客地址:坑的总结
再遇到其它相关坑,百度吧,都能快速找到答案。
ElasticSearch(1)---Logstash同步Mysql数据到ElasticSearch的更多相关文章
- centos7配置Logstash同步Mysql数据到Elasticsearch
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中.个人认为这款插件是比较稳定,容易配置的使用Logstash之前,我们得明确 ...
- 实战ELK(6)使用logstash同步mysql数据到ElasticSearch
一.准备 1.mysql 我这里准备了个数据库mysqlEs,表User 结构如下 添加几条记录 2.创建elasticsearch索引 curl -XPUT 'localhost:9200/user ...
- 【记录】ELK之logstash同步mysql数据到Elasticsearch ,配置文件详解
本文出处:https://my.oschina.net/xiaowangqiongyou/blog/1812708#comments 截取部分内容以便学习 input { jdbc { # mysql ...
- Centos8 部署 ElasticSearch 集群并搭建 ELK,基于Logstash同步MySQL数据到ElasticSearch
Centos8安装Docker 1.更新一下yum [root@VM-24-9-centos ~]# yum -y update 2.安装containerd.io # centos8默认使用podm ...
- 使用logstash同步mysql数据到elasticsearch
下载 logstash tar -zxvf https://artifacts.elastic.co/downloads/logstash/logstash-6.3.2.tar.gz .tar.gz ...
- Logstash学习之路(四)使用Logstash将mysql数据导入elasticsearch(单表同步、多表同步、全量同步、增量同步)
一.使用Logstash将mysql数据导入elasticsearch 1.在mysql中准备数据: mysql> show tables; +----------------+ | Table ...
- 推荐一个同步Mysql数据到Elasticsearch的工具
把Mysql的数据同步到Elasticsearch是个很常见的需求,但在Github里找到的同步工具用起来或多或少都有些别扭. 例如:某记录内容为"aaa|bbb|ccc",将其按 ...
- 使用logstash同步MySQL数据到ES
使用logstash同步MySQL数据到ES 版权声明:[分享也是一种提高]个人转载请在正文开头明显位置注明出处,未经作者同意禁止企业/组织转载,禁止私自更改原文,禁止用于商业目的. https:// ...
- 同步mysql数据到ElasticSearch的最佳实践
Elasticsearch是一个实时的分布式搜索和分析引擎.它可以帮助你用前所未有的速度去处理大规模数据.ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全 ...
- Logstash7.6.2同步Mysql数据到ElasticSearch
1.准备工作:存在的mysql的数据库表.创建好的elasticsearch索引 2.下载mysql-connector 下载地址:https://dev.mysql.com/downloads/co ...
随机推荐
- 高性能计算-gemm-openmp效率测试(10)
1. 目标 设计一个程序,使用OpenMP并行化实现矩阵乘法.给定两个矩阵 A 和 B,矩阵大小均为1024*1024,你的任务是计算它们的乘积 C. 要求: (1).使用循环结构体的知识点,包括fo ...
- Spring的IOC容器创建过程深入剖析
前言 本次对于Spring的IOC容器的创建过程是基于其源码进行研究分析的,主要涉及BeanFactory的创建过程,Bean的解析与注册过程,Bean实例化的过程以及诸如ClassPathXmlAp ...
- Spring + EHcache配置
需要使用Spring来实现一个Cache简单的解决方案,具体需求如下:使用任意一个现有开源Cache Framework,要求可以Cache系统中Service或则DAO层的get/find等方法返回 ...
- Docker之修改默认存储路径
背景:Docker 默认安装的情况下,会使用 /var/lib/docker/ 目录作为存储目录,用以存放拉取的镜像和创建的容器等.不过由于此目录一般都位于系统盘,遇到系统盘比较小,而镜像和容器多了后 ...
- 【Java基础】-- isAssignableFrom的用法详细解析
最近在java的源代码中总是可以看到isAssignableFrom()这个方法,到底是干嘛的?怎么用? 1. isAssignableFrom()是干什么用的? 首先我们必须知道的是,java里面一 ...
- 【论文系列】PPO知识点梳理 (尽我可能细致通俗理解!)
零.题记 这篇博客一方面为了记录当前的知识点,另一方面PPO算法实在是太重要了,不但要从理论上理解它到底是怎样实现的,还需要从代码方面进行学习和记录,这里我就通俗的将这个知识点进行简单的记录,用来日后 ...
- Java基础 —— 集合(一)
集合(一) 数组和集合的区别 数组是固定长度的数据结构,而集合是动态的数据结构 数组可以包含基本数据类型和对象,集合只能包含对象 数组只能存放同一类型的数据,而集合可以蹲房不同类型的 数组可以直接访问 ...
- 正则g修饰符对test方法的影响
标签: js 坑位 最近在使用正则的时候遇到一个问题,从一个数组中选出符合我要求的元素做进一步使用,但正则验证莫名的失效不通过,坑位代码片段如下 测试地址 : var reg = /\[.{32}\] ...
- Flutter 设置安卓启动页报错 java.lang.RuntimeException: Canvas: trying to draw too large(106,975,232 bytes) bitmap.
设置安卓启动页报错 首先设置安卓启动页 在android/app/src/main/AndroidManifest.xml中添加这一行 <meta-data android:name=" ...
- C#字符串拼接的几种方式及其性能分析对比
前言 在C#编程中字符串拼接是一种常见且基础的操作,广泛应用于各种场景,如动态生成SQL查询.构建日志信息.格式化用户显示内容等.然而,不同的字符串拼接方式在性能和内存使用上可能存在显著差异.今天咱们 ...