DynamoDB-键值存储
什么是DynamoDB?
DynamoDB 是一个你什么也不用管的 NoSql 数据库。记得给 AWS付账单就可以。
在2004年的时候, Amazon 发现 Oracle 数据库都不够用了。为了还能继续做生意。 AWS设计了一个 Key-Vale 存储系统。以希望能达到以下目的:高性能,可扩展性,可靠性。
DynamoDB是分布式数据库,设计成用来解决数据库管理、性能、可扩展性和可靠性等核心问题。开发人员可以创建一个数据库表,该表可以存储和检索任何数量的数据。
DynamoDB 用起来很简单,因为它的功能很简单,你想一个 Key-value 能什么花头可以搞的, 以至于你感觉它基本上没用处。 特别是你发现市场上 kev-value 的数据库已经多的性况下。如果你非要说好,也怕只有:你开箱就用,不需要自己去维护什么。要记得给钱。
Dynamodb 会说你在最开始做产品的开发的的时候,要用户没用户,要功能没功能,所以关系型数据库不合适,因为你不知道有什么 schema。 但是 DynamoDB 对你可能更没有用。因为根据它的文档:你只能对你的产品需求很熟悉的时候,你才能设计好表的 Partion key和Sort key, 以及 primary key。 从这个角度来说,还不如 MySQL。
什么是DynamoDB
Amazon DynamoDB 是一种完全托管的 NoSQL 数据库服务,提供快速而可预测的性能,能够实现无缝扩展。DynamoDB 可以从表中自动删除过期的项,从而帮助您降低存储用量,减少用于存储不相关数据的成本。
DynamoDB工作原理
在DynamoDB中核心组件是表、项目和属性。表是项目的集合,项目是属性的集合,DynamoDB使用主键来标识表中的每个项目,还提供了二级索引来提供更大的查询灵活性,还可以使用DynamoDB流来捕获DynamoDB表中的数据修改事件。
表、项目和属性
- 表 DynamoDB将数据存储在表中,表是某类数据的集合,例如People表、Cars表。
- 项目 每个表包含多个项目,项目是一组属性,具有不同于所有其他项目的唯一标识,项目类似与SQL中的行、记录或元组。
- 属性 每个项目包含一个或多个属性,属性是基本的数据元素,属性类似与SQL中的字段或列。
People表示例

- 表中每个项目都有一个唯一的标识符或主键(PersonID)用于将项目和表中的其他内容区分开来
- 除主键外,People表是无架构的,这表示属性和其数据类型都不需要预先定义,每个项目都能有自己独特的属性
- 大部分属性属于标量类型,这意味着它们只能有一个值,例如字符串或数字
- 某些项目具有嵌套属性(People表中的Address),DynamoDB最高支持32级深度的嵌套属性
Music表示例

- 与People表不同的是,Music表的项目主键有两个属性(Artist和SongTitle),表中的每个项目都必须包含这两个属性,Artist和SongTitle属性的组合用于将表中的每个项目区分开来
主键
创建表时除了指定表名外还必须指定表的主键,主键用于唯一标识表中的每一个项目,任意两个项目的主键都不能相同。
DynamoDB支持两种类型的主键:
- 分区键 简单的主键由一个分区键的属性构成,表中的每个项目都必须有不同的分区键值,分区键值用于DynamoDB内部散列(Hash)函数的输入,散列函数的输出决定将项目存储到哪个分区中。
- 分区键和排序键 也称复合键,该类型的主键由两个属性组成, 第一个属性是分区键,第二个属性是排序键,分区键决定存储位置,具有相同分区键的项目按照排序键的值排序然后顺序存储在一起。在具有分区键和排序键的表中两个项目可能有相同的分区键值,但是必须有不同的排序键值。
注意
每个主键属性必须为标量,主键属性的数据类型只能是字符串、数字和二进制。
二级索引
可以在表上建立一个或多个二级索引,利用二级索引,除了可以用主键进行查询外,还可以使用替代键查询表中的数据。
DynamoDB支持两种索引:
- 全局二级索引(Global secondary index) 一种可能带有与表中不同的分区键和排序键的索引
- 本地二级索引(Local secondary index) 一种分区键与表中的相同但排序键与表中不同的索引
每个表最多可以定义5个全局二级索引和5个本地二级索引。
前面的Music示例表中可以按Artist(分区键)或按Artist和SongTitle(分区键和排序键)进行数据查询。若要按Genre和AlbumTitle查询数据要该怎么做?
这时我们可以在Genre和AlbumTitle上创建一个二级索引,然后通过相同的方式查询索引。
下面的Music示例表包含了一个名为GenreAlbumTitle的新索引,索引中Genre是分区键,AlbumTitle是排序键。

- 每一个索引属于一个表(称为索引的基表),上面Music是GenreAlbumTitle索引的基表.
- DynamoDB会自动维护索引,当你添加、更新或删除基表中的某个项目时,DynamoDB会自动添加、更新或删除属于该表的任何索引中的对应项目
- 在创建索引时可以指定哪些属性将从基表复制或投影到索引。不指定的情况下DynamoDB至少也会将键属性投影到索引中,如上面所示,此时GenreAlbumTitle索引中至少有Music表中的键属性(Artist和SongTitle)
DynamoDB流
DynamoDB流是一项可选功能,它用于捕获DynamoDB表中的数据修改事件。有关这些事件的数据将按事件发生的顺序近乎实时的出现在流中。
每个事件由一条流记录表示,若对表启用了流,每当以下事件之一 发生时,DynamoDB流都会写入一条流记录:
- 如果向表中添加了新项目,流将捕获整个项目的映像(包括其所有属性)
- 如果更新了项目,流将捕获项目中任何已修改属性的"之前"和"之后"映像
- 如果从表中删除了项目,流将在整个项目被删除前捕获其映像
每条流记录还包含表名称、事件时间戳和其他元数据。流记录的有效事件为24小时,过此事件后记录将被自动删除
扩展
DynamoDB流可以和AWS Lambda结合使用以创建触发器,即在流中有你感兴趣的事件出现时自动执行Lambda中的代码。
例如,假设有一个包含某公司客户信息的 Customers 表。假设你希望向每位新客户发送一封“欢迎”电子邮件。你可对该表启用一个流,然后将该流与 Lambda 函数关联。Lambda 函数将在有新项目添加到Customers表的流记录发生时执行。若该新项目有EmailAddress属性,Lambda 函数将调用 Amazon Simple Email Service (Amazon SES) 以向该地址发送电子邮件。
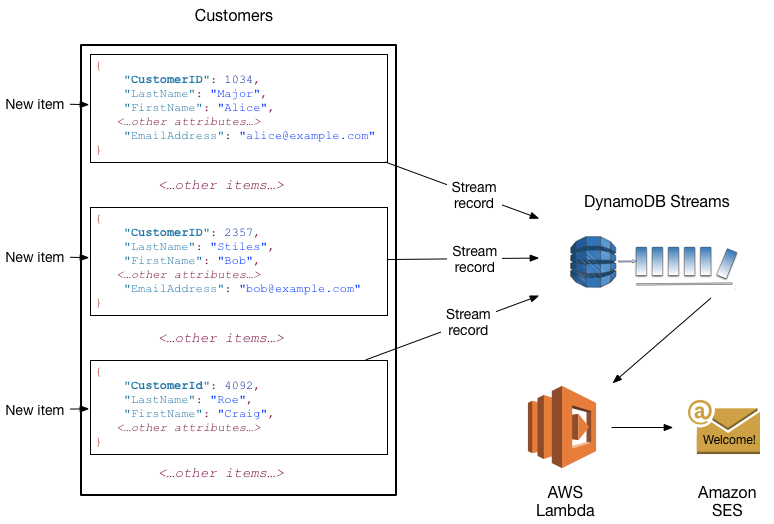
此示例中最后一位客户将不会收到电子邮件,因为他没有EmailAddress属性。
除了触发器之外,DynamoDB流还提供更强大的解决方案,例如AWS区域内或跨区域数据复制,DynamoDB表中的数据具体化视图,使用Kinesis具体化视图的数据分析等。
DynamoDB-键值存储的更多相关文章
- [Swift]LeetCode981. 基于时间的键值存储 | Time Based Key-Value Store
Create a timebased key-value store class TimeMap, that supports two operations. 1. set(string key, s ...
- LeetCode 981.基于时间的键值存储(C++)
创建一个基于时间的键值存储类 TimeMap,它支持下面两个操作: 1. set(string key, string value, int timestamp) 存储键 key.值 value,以及 ...
- 【插件开发】—— 8 IPreferenceStore,插件的键/值存储!
前文回顾: 1 插件学习篇 2 简单的建立插件工程以及模型文件分析 3 利用扩展点,开发透视图 4 SWT编程须知 5 SWT简单控件的使用与布局搭配 6 SWT复杂空间与布局搭配 7 SWT布局详解 ...
- SQLite实现内存键值存储
SQLite数据文件往Linux内存文件系统/dev/shm/data.sqlite3一放,就是内存级读写性能的SQL系统.用SQLite实现内存键值存储:CREATE TABLE IF NOT EX ...
- 用于C# 的异步,持久的键值存储 Akavache 使用
Akavache是一个异步的,持久的(即写入磁盘)键值存储,用于在C#中编写桌面和移动应用程序,基于SQLite3.Akavache非常适合存储重要数据(即用户设置)以及过期的缓存本地数据. 开源 ...
- CockroachDB学习笔记——[译]CockroachDB中的SQL:映射表中数据到键值存储
CockroachDB学习笔记--[译]CockroachDB中的SQL:映射表中数据到键值存储 原文标题:SQL in CockroachDB: Mapping Table Data to Key- ...
- 云原生K8S精选的分布式可靠的键值存储etcd原理和实践
@ 目录 概述 定义 应用场景 特性 为何使用etcd 术语 架构 原理 读操作 写操作 日志复制 部署 单示例快速部署 多实例集群部署 静态 etcd 动态发现 常见命令 概述 定义 etcd 官网 ...
- Key-Value键值存储原理初识(NOSQL)
NO-Sql数据库:Not Only不仅仅是SQL 定义:非关系型数据库:NoSQL用于超大规模数据的存储.(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据).这些类型的数据存储不需要固 ...
- PowerDotNet平台化软件架构设计与实现系列(05):ETCD分布式键值存储平台
ETCD目前在PowerDotNet已经被用于注册中心和配置管理(常见的配置中心在PowerDotNet中仅仅是一个小小的模块而已)中,作为基础设施的重要组成部分,ETCD的重要性不言而喻. 本文简单 ...
- [iOS Keychain本地长期键值存储]
目前本地存储方式大致有:Sqlite,Coredata,NSUserdefaults.但他们都是在删除APP后就会被删除,如果长期使用存储,可以使用Keychain钥匙串来实现. CHKeychain ...
随机推荐
- 4.4 Linux解压.zip格式的文件(unzip命令)
unzip 命令可以查看和解压缩 zip 文件.该命令的基本格式如下: [root@localhost ~]# unzip [选项] 压缩包名 此命令常用的选项以及各自的含义如表 1 所示. 选项 含 ...
- SpringBoot必须掌握的常用注解!
Spring Boot 提供了大量的注解,用于简化配置和加速程序开发. 那么接下来,咱们就一起来看下 Spring Boot 中的常用注解有哪些?及其这些注解的具体使用. 1.Bean相关 @Comp ...
- ARC133D Range XOR
ARC133D Range XOR 题目链接:[ARC133D] Range XOR 非常好数位 dp. 思路 根据异或的前缀和,我们可以把式子化成这样. \[\sum_{i=l}^r\sum_{j= ...
- CommonsCollections5(基于ysoserial)
环境准备 JDK1.8(8u421)我以本地的JDK8版本为准.commons-collections(3.x 4.x均可这里使用3.2版本) cc3.2: <dependency> &l ...
- common-dbutils的使用
1. 介绍 commons-dbutils是Apache组织提供的一个开源 JDBC工具类库,能让我们更简单的使用JDBC.它是一个非常小的类包,花几分钟的时间就能掌握它的使用. 2. ...
- 在运行期通过反射了解JVM内部机制
本文由 ImportNew - 黄飞飞 翻译自 takipioncode.欢迎加入Java小组.转载请参见文章末尾的要求. 在日常工作中,我们都习惯直接使用或者通过框架使用反射.在没有反射相关硬编码知 ...
- SQL SERVER日常运维巡检系列——结构设计
前言 做好日常巡检是数据库管理和维护的重要步骤,而且需要对每次巡检日期.结果进行登记,同时可能需要出一份巡检报告. 本系列旨在解决一些常见的困扰: 不知道巡检哪些东西不知道怎么样便捷体检机器太多体检麻 ...
- Docker之磁盘清理
Docker 很占用空间,每当我们运行容器.拉取镜像.部署应用.构建自己的镜像时,我们的磁盘空间会被大量占用. 如果你也被这个问题所困扰,咱们就一起看一下 Docker 是如何使用磁盘空间的,以及如何 ...
- 为什么Spring官方不推荐使用 @Autowired?
前言 很多人刚接触 Spring 的时候,对 @Autowired 绝对是爱得深沉. 一个注解,轻松搞定依赖注入,连代码量都省了. 谁不爱呢? 但慢慢地,尤其是跑到稍微复杂点的项目里,@Autowir ...
- CSS 样式百分比
1.宽高百分比 元素宽度/高度百分比是基于父级元素的width/height,不包含padding,border 注意:高度百分比一定要求父元素有设置height属性,只设置 min-height 虽 ...