ES查询优化随记1: 多路向量查询 & KNN IO排查 & 高效Filter使用
哈哈最近感觉自己不像算法倒像是DB,整天围着ES打转,今天查IO,明天查内存,一会优化查询,一会优化吞吐。毕竟RAG离不开知识库,我们的选型是ES,于是这一年都是和ES的各种纠葛。所以顺手把近期获得的一些小tips记下来,万一有人和我踩进了一样的坑,也能早日爬出来。当前使用的ES版本是8.13,和7版本有较大的差异,用7.X的朋友这一章可能有不适配。本章主要覆盖以下
- 多Query向量查询的各种方案:Script,Knn(mesearch)
- KNN查询IOUtil过高问题排查
- 如何使用Filter查询更高效
多Query向量查询的各种方法
大模型的知识库都离不开向量查询,并且当前的RAG往往会对用户query进行多角度的改写和发散,因此会涉及多query同时进行向量查询。如果用ES实现的话,常用的有以下几种形式
- 多向量Pooling Script查询:多个query的向量平均后进行查询,查询效果不好,因为Pooling往往会损失很多信息,虽然把多个向量压缩成了一个向量,查询效率更高压力更小,但是效果差的离谱。但是对使用ES 7.X版本的朋友可能也是一种选择。
query_body = {
"size":10
"query": {
"bool": {
"must": [{
"script_score": {
"query": {"match_all": {}},
"script": {
"source": f"cosineSimilarity(params.query_vector, 'vectors')",
"params": {"query_vector": avg_embedding}
}
}
}]
}
}
}
- 向量script循环取cosine的最大值或者平均值:使用ES 7且的朋友一般的选项,因为7的版本里部分没有KNN的支持,因此只能使用script线性遍历向量。而不把所有向量召回的内容都取回来进行重排序主要是IO的考虑,返回的条数更少传输压力更小。以下为python的查询示例,embedding_list是多query的向量数组。
query_body = {
"query": {
"function_score": {
"script_score": {
"script": {
"source": """
double max_score = -1.0;
if (doc[params.field].size() == 0) return 0; // 空值保护
for (int i=0; i<params.length; i++) {
double similarity = cosineSimilarity(
params.query_vectors[i],
params.field
);
max_score = Math.max(max_score, similarity);
}
return max_score;
""",
"params": {
"length": len(embedding_list),
"query_vectors": embedding_list,
"field": "vectors"
}
}
},
"boost_mode": "replace"
}
}
}
response = es.search(index=index, body=query_body)
- 多向量KNN查询:用ES8版本的一般会考虑KNN查询,每个向量单查KNN,对同一个index的多条KNN查询推荐使用msearch组合查询并返回。
query_body = {
"query": {
"bool": {
"must": [{
"knn": {
"field": 'vectors',
"query_vector": embedding_item,
"num_candidates": 10
}
}]
}
}
}
KNN查询IO打满的问题排查
在使用以上KNN搜索时,我们遇到一个问题,就是一使用KNN查询,IOUitl指标就会打满,进而影响其他所有查询任务,导致线上查询会Hang住,如下图所示。
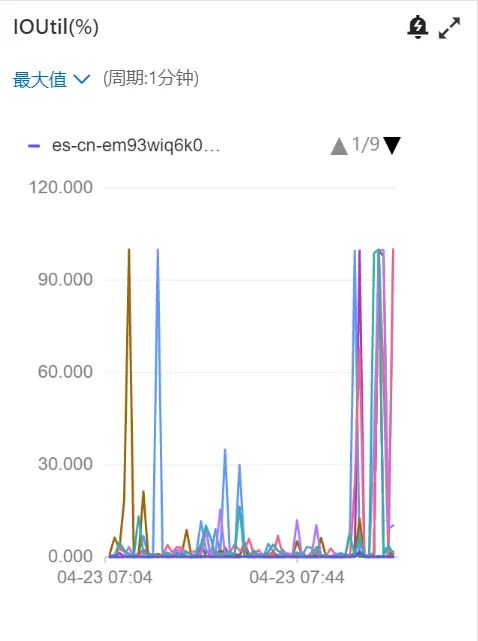
经过阿里ES大佬的帮助,我们定位了问题,核心是HNSW图向量没有加载到内存里,因此在查询时触发了向量加载,因此大量的IO都是在进行向量搬运操作,搬多久IO就打满多久,解决的方案主要分2步
第一步优化图大小,原始我们的图使用Float32存储的,ES8.15提供了int4,int8存储,8.17好像还提供压缩比例更高的存储方式,因此我们reindex了索引修改成了INT8存储。但是发现优化后IO指标并未下降。
于是就有了第二步预加载,大佬给出的解释是HNSW算法存在大量的随机读,除了HNSW图,还会读取原始或量化后的向量数据,这些数据也需要加载到内存中进行查询(从磁盘加载)。而解决这个问题的办法就是预加载。以int8_hnsw为例,预加载的方式如下,需要先关闭索引,完成预加载,再开启索引。因此必须在非业务使用期进行操作,百万级的索引大小大概几分钟就能完成以下操作,不过我们在预加载时有时会引起集群的不稳定,因此建议在业务低峰期操作。
# 关闭索引
POST your_index/_close
# 调整preload参数
PUT your_index/_settings
{
"index.store.preload": ["vex", "veq"]
}
# 开启索引
POST your_index/_open
只不过以上预加载存在一个问题,就是预加载的内容会持续存在缓存中,也算是用空间换时间的方案,如果有太多索引需要做预加载,应该会存在竞争关系,不过在我们的配置下还未出现这个问题,所以大家在预加载时需要关注下内存等指标变化
Filter的三种不同使用方式
依旧围绕向量搜索,在使用向量时在我们的场景中一般会有时间Filter,根据不同的时效性分层和时效性抽取结果选取不同的查询时间段,和整个index大小相比,时效性filter往往能大幅缩减查询的索引范围,但是使用filter的方式不同,对查询效率有较大影响。
- pre filter:过滤条件在knn的filter语句中
{"knn": {
"field": "vectors",
"query_vector": [-0.0574951171875, 0.0222320556640625, ...],
"num_candidates": 3,
"filter": [{
"range": {
"publishDate": {
"lte": "2025-04-22",
"gte": "2023-04-22",
"format": "yyyy-MM-dd"
}
}
}
]
}
}
- post filter:过滤条件在bool的filter语句中
{
"bool": {
"must": [{
"knn": {
"field": "vectors",
"query_vector": [-0.0574951171875, 0.0222320556640625, ...],
"num_candidates": 3,
}
}],
"filter": [{
"range": {
"publishDate": {
"lte": "2025-04-22",
"gte": "2023-04-22",
"format": "yyyy-MM-dd"
}
}
}]
}
}
- 过滤条件在must语句中
{
"bool": {
"must": [{
"range": {
"publishDate": {
"lte": "2025-04-22",
"gte": "2023-04-22",
"format": "yyyy-MM-dd"
}
}
},
{
"knn": {
"field": "vectors",
"query_vector": [-0.0574951171875, 0.0222320556640625, ...],
"num_candidates": 3,
}
}]
}
}
以上三种查询方式的对比如下
| Filter方式 | 查询效率 |
|---|---|
| Pre Filter | 查询效率最高,前置过滤会缩减knn查询范围提高查询效率 |
| Post Filter | 查询效率较低,在非KNN的其他查询场景这是查询效率最高的写法。但在KNN场景中会比只用KNN更慢,因为是在KNN搜索结果拿到后进行后置过滤,同时会导致最终返回的数量可能少于查询数量 |
| 过滤条件在must语句中 | 查询效率最低,在filter语句中ES会直接忽略不满足条件的文档,而在must语句中所有文档都会参与评分。并且Filter语句ES会缓存过滤条件使得后续查询更快而must不会进行缓存 |
ES查询优化随记1: 多路向量查询 & KNN IO排查 & 高效Filter使用的更多相关文章
- ES 入门记录之 match和term查询的区别
ElasticSearch 系列文章 1 ES 入门之一 安装ElasticSearcha 2 ES 记录之如何创建一个索引映射 3 ElasticSearch 学习记录之Text keyword 两 ...
- 并发式IO的解决方案:多路非阻塞式IO、多路复用、异步IO
在Linux应用编程中的并发式IO的三种解决方案是: (1) 多路非阻塞式IO (2) 多路复用 (3) 异步IO 以下代码将以操作鼠标和键盘为实例来演示. 1. 多路非阻塞式IO 多路非阻塞式IO访 ...
- 白日梦的Elasticsearch实战笔记,ES账号免费借用、32个查询案例、15个聚合案例、7个查询优化技巧。
目录 一.导读 二.福利:账号借用 三._search api 搜索api 3.1.什么是query string search? 3.2.什么是query dsl? 3.3.干货!32个查询案例! ...
- es查询优化思路
尽可能的利用内存 将尽可能的索引留在内存,即留更多的堆外内存给es 不查询的字段尽量不要往es插入,节省索引的空间大小(es + hbase) 数据预热 冷热数据分离 文档字段设计 根据查询场景设计字 ...
- 记一次Hbase查询速度优化经历
项目背景: 在这次影像系统中,我们利用大数据平台做的是文件(图片.视频等)批次的增删改查,每个批次都包含多个文件,上传完成以后要添加文件索引(文件信息及批次信息),由于在Hbase存储的过程中,每个文 ...
- ES系列十九、kibana基本查询、可视化、仪表盘用法
一. 定义索引模式匹配 1.前缀模糊匹配,一个模式匹配多个索引 每一个数据集导入到Elasticsearch后会有一个索引匹配模式,在上段内容莎士比亚数据集有一个索引名称为shakespeare,账户 ...
- 记一次JPA查询分页导致的数据丢失问题
使用JPA查询,共17条数据,每页10条数据. 第一页与第二页有一条重复的数据,导致丢失一条数据 后查明原因发现,该查询使用了排序,排序字段的值在多条数据中相同,比如在3-11条是相同的值.此时跳到第 ...
- ES cross cluster search跨集群查询
ES 5.3以后出的新功能.测试demo如下: 下载ES 5.5版本,然后分别本机创建2个实例,配置如下: cluster.name: xx1 network.host: 127.0.0.1 http ...
- 记一次newApiHadoopRdd查询数据不一致问题
现象: +----------+-------+--------+-----+-----+-----+----+----+------+---------+-------+--------+----- ...
- ES搜索- term与match区别&bool查询
term属于精确匹配,只能查单个词,tems可以匹配多个词(满足其中之一词的都会被搜索出来),多个词如果要同时匹配使用bool的must(must中带多个term): match进行搜索的时候,会先进 ...
随机推荐
- hbase - [05] hbase关联hive
一.配置 1.在hive的配置文件中配置HBASE_HOME(conf/hive-env.sh) export HBASE_HOME=/opt/module/hbase 2.将 conf/hive-e ...
- Processing多窗口程序范例(二)
多窗口范例(二),做一个划线生成图像的应用,最后结果: 子窗口划线,主窗口复制多个画布叠加并添加了旋转动画. 范例程序 主程序: package syf.demo.multiwindow2; impo ...
- Flink学习(十六) ProcessFunctionAPI(底层API)
我们之前学习的转换算子是无法访问时间的时间戳信息和水位线信息的.而这些在一些应用场景下,极为重要,例如MapFunction这样的map转换算子就无法访问时间戳或者当前事件的事件时间. 基于此,Dat ...
- 大数据之路Week08_day06 (Zookeeper初识)
让我们来回顾一下我们在学习Hadoop中的HDFS的时候,肯定见过下面这样的两幅图: 这副图代表着什么呢?它介绍的是Hadoop集群的高可靠,也就是前面提过的HA,仔细观察一下这副图,我们发现有两个N ...
- sql---索引总结
索引:是为了提高数据查询的效率 常见模型: 哈希表(以键值对key-value存储数据的结构) 适应场景:哈希表这种结构适用于只有等值查询的场景 思路:把值放在数组里,用一个哈希函数把key换算成一个 ...
- Windows编程----CreateProcess函数
CreateProcess函数原型 CreateProcess 函数用于创建一个新进程(子进程)及其主线程,其函数原型如下: BOOL CreateProcess( LPCWSTR lpApplica ...
- Windows 提权-内核利用_1
本文通过 Google 翻译 Kernel Exploits Part 1 – Windows Privilege Escalation 这篇文章所产生,本人仅是对机器翻译中部分表达别扭的字词进行了校 ...
- Linux基础知识之:crontab定时任务
目录 5.3 定时(计划)任务crontab 5.3.1 定时任务的概念 5.3.2 定时任务的作用 5.3.3 crontab命令语法 5.3.4. crontab编辑语法 5.4.5 定时任务的编 ...
- Camel多智能体框架初探
Camel介绍 CAMEL 是一个开源社区,致力于探索代理的扩展规律.我们相信,在大规模研究这些代理可以提供对其行为.能力和潜在风险的宝贵见解.为了促进该领域的研究,我们实现了并支持各种类型的代理.任 ...
- 文件转十六进制出现转义字符直接通过ASCII码逐字符展开的问题与修复
近日工作中遇到某品牌电子签章系统生成的PDF文件若直接使用十六进制查看器打开,会出现转义字符被直接以ASCII编码转换为16进制字符串的问题,导致提取的文件无法匹配ASN.1格式,无法进一步对签章有效 ...