目标检测 | Spatially Sparse Convolution
Spatially Sparse Convolution
导言
为什么需要稀疏化?
在3D表示中,除了点云(Point Cloud)和网格模型(Mesh),我们常常还会使用到一种称为体素(Voxel)的表示方式。类似于像素(Pixel),这种表示方式将空间均匀地切割为一个个方块,TSDF和占据网格(Occupancy Network)都可以视为体素的一种变形。
最朴素的体素表示方式,这是一种稠密(Dense)的表示形式,我们给定一个\(L\times W\times H\)的包围盒,体素尺寸为\(1\times 1\times 1\),那么我们将得到一个\(L\times W\times H\)的\(bool\)矩阵:
\begin{cases}
1 & \text{if voxel } (x, y, z) \text{ is occupied.}, \\
0 & otherwise.
\end{cases}
\\
\text{where } 0 \leq x < L, \ 0 \leq y < W, \ 0 \leq z < H
\]
那么假设我们有一个\(70.4m\times80m\times4m\)的室外点云场景(KITTI点云格式的感知范围),给定每个体素大小为\(0.16m\times0.16m\times4m\)(PointPillar将点云体素化的参数),那么将得到一个大小为\(440\times 500\times1=220,000\)的体素网格,而最终有效的体素数量不会超过\(40,000\)个,即利用率不会超过\(18\%\),稠密表示形式下,有\(80\%\)的存储空间是被浪费的。
我们在模拟器中简单采集一帧点云做个实验就可以看到,当体素大小为\(0.05m\)时,基本保留原始点云的细节,但此时占用率不足千分之一。
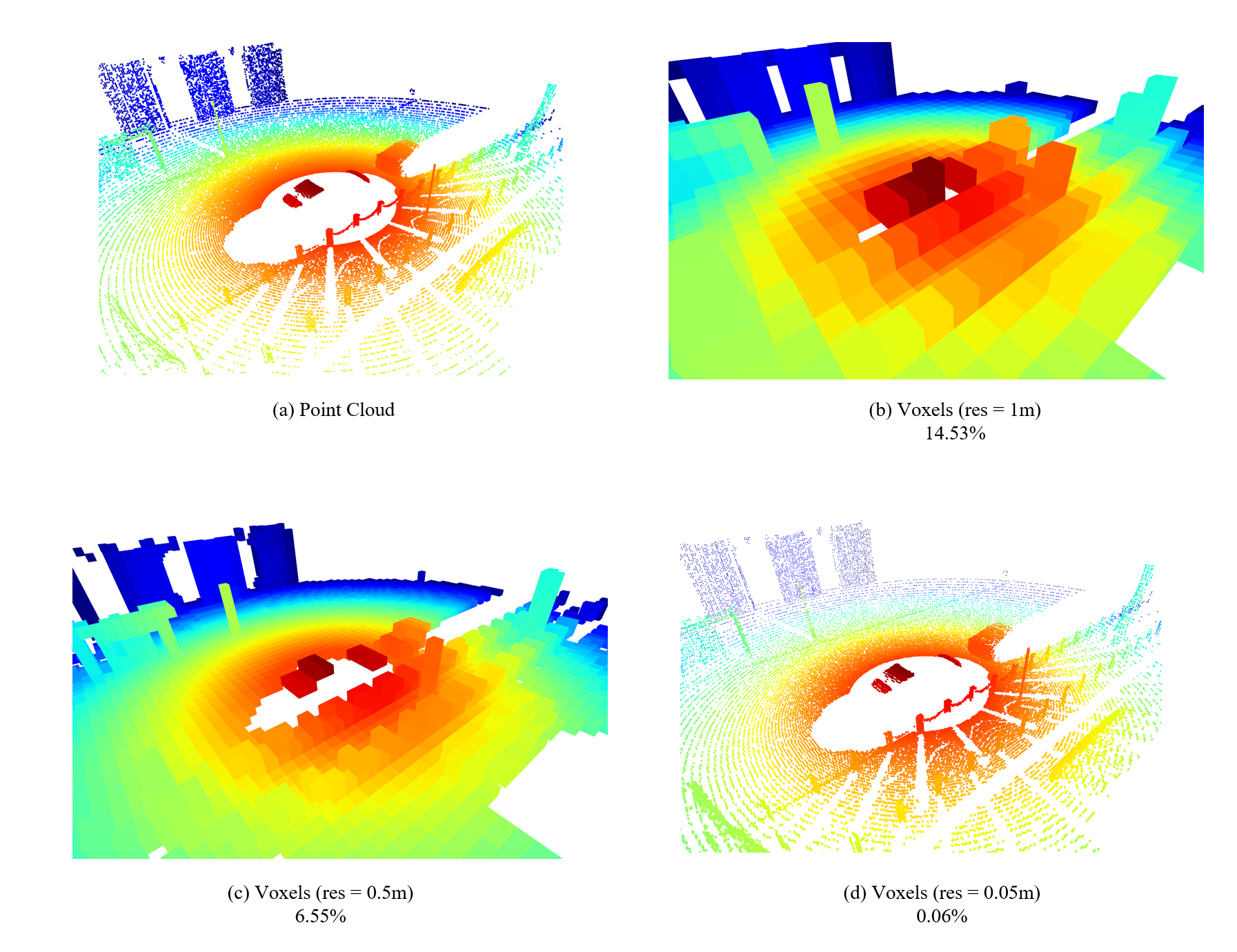
所以只表示有效体素的稀疏化表示就这样提出了,这种表示有效降低了内存的冗余,并加速了对体素的处理。
稀疏卷积
最常用的稀疏卷积分为Spatially Sparse Convolution(SparseConv)和Submanifold Sparse Convolution(SubMConv),前者是常规卷积操作的稀疏化版本,后者是保证不破坏特征图稀疏度的卷积操作。
现代通用版本的SparseConv实现出自于SECOND: Sparsely Embedded Convolutional Detection
SubMConv出自于3D Semantic Segmentation with Submanifold Sparse Convolutional Networks
稀疏卷积主要分为四个步骤:
- 张量稀疏化
- 建立indice pair
- 稀疏特征收集
- 稀疏卷积计算
稀疏卷积
我们给出一个简单的稀疏卷积例子
如下图所示,P1与P2两个输入分别在SparseConv与SubMConv所关联的输出为A1与A2
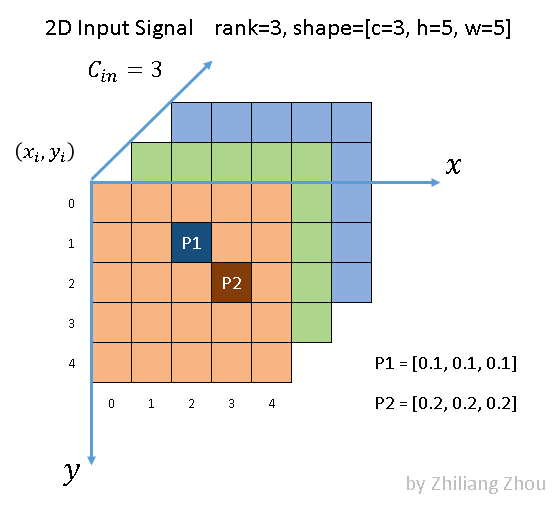
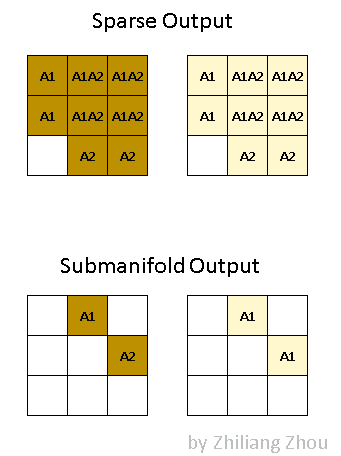
张量稀疏化
张量稀疏化就是顾名思义将一个张量从稠密表示形式变换为稀疏表示形式,我们给出常用的COO内存的定义,给定一个张量\(\mathbf X\in \mathbf{R}^{N_1\times N_2\times\cdots \times N_m}\)与稀疏维度\(d\ge1\),得到一个索引\(\mathbf{I}\in\mathbf{R}^{n\times d}\)以及值\(\mathbf{V}\in\mathbf{R}^{n\times N_{d+1}\times\cdots \times N_m}\),其中\(n\ge 0\)为张量中的非\(0\)量的数量
- 给定\(\mathbf X\in\mathbf{R}^{2\times 2} = \begin{bmatrix} 0 & 2 \\ 3 & 0 \end{bmatrix}\),\(d=2\),得到\(\mathbf I\in{2\times 2} =\text{[[0, 1], [1, 0]]}\)以及\(\mathbf{V}\in\mathbf{R}^{2}=\text{[2., 3.]}\)
- 给定\(\mathbf X\in\mathbf{R}^{2\times 2\times 2} = \begin{bmatrix} \begin{bmatrix} 0 & 0 \\ 1 & 2 \end{bmatrix} \\ \begin{bmatrix} 0 & 0 \\ 3 & 4 \end{bmatrix} \end{bmatrix}\),\(d=2\),得到\(\mathbf I\in{2\times 2} =\text{[[0, 1], [1, 1]]}\)以及\(\mathbf{V}\in\mathbf{R}^{2\times2}=\text{[[1., 2.],[3., 4.]]}\)
五种内存管理形式
建立indice pair
在输入中,稀疏矩阵中非空量我们称为active input (actIn),那么每个actIn在输出中存在关联的量称为active output (actOut)
indice pair是一个\(k\times n\)的表结构,每个元素是一个索引对\((i, j)\),表示的是\(\text{actIn}[i]\)乘以卷积核中的第\(k\)个权重,其结果输出到\(\text{actOut}[j]\)中,建立indice pair如下进行:
初始化actOut
计算actIn所关联的每个actOut
给定一个\(\text{actIn}[i]=(x,y)\),可以算出每个输出坐标\((x^\prime,y^\prime)\)以及其对应卷积核位移\(k\)
在actOut寻找\((x^\prime,y^\prime)\)是否存在,没有就开辟一个新空间,返回其索引\(j\)
建立索引indicePair[k].append(i,j)
可以如下写成伪代码形式:
vector[K] get_indice_pair(act_in: vector, act_out: vector) {
initialize indice_pair = vector[K];
for i in enumerate(act_in.length()) {
pos_act_In = act_in[i];
for k, {x, y} in get_valid_out_pos(pos_act_In) {
j = act_out.find({x, y});
if(j == -1) {
j = act_out.length();
act_out.append({x, y});
}
indice_pair[k].append({i, j});
}
}
return indice_pair;
}
如果是SubMConv操作,在get_valid_out_pos中检查输出坐标在输入所对应的坐标中是否为actIn,否则过滤掉即可
注意:这里只是为了方便理解把indice pair写成了\(k\times n\)的表,实际indice pair一般都是一张\(2\times k\times n\)的表,其中\(\text{indice_pair}(0,k,n)=i,\ \text{indice_pair}(1,k,n)=j\),这样在特征收集与计算阶段就只需要读入半张表,提高性能
稀疏特征收集
这一步的目的在于通过indice_pair收集读入指定位置的特征feats,用于下一步的卷积计算。我们可以用公式表示:
\]
稀疏卷积计算
稀疏卷积计算分为两步:相乘与求和
相乘阶段
相乘阶段的目的在于将特征feats与指定位置的权重相乘
\[\text{feats}^\prime\in \mathbf{R}^{k\times n\times f} = \text{feats} \in\mathbf{R}^{k\times n\times f} \odot \text{kernal}\in \mathbf{R}^{k}
\]其中$\odot $是逐元素乘积
求和阶段
将上一阶段相乘的特征进行求和
\[\mathbf I = \text{actOut},\mathbf{V}(j)=\sum_{k}\text{feats}^\prime(k,n) \\\text{where}\ \text{indice_pair}[n]=\{i, j\}
\]可以如下写成伪代码形式:
vector[K] sparse_scatter_add_cpu(act_out: vector[N], indice_pair: vector[K], feats: Tensor[k, n, f], kernal[k]) {
feats = feats * kernal; \\Tensor[k, n, f]
value = tensor::zeros((act_out.length(), feats.size(2))); \\Initialize a full 0 Tensor with size [N, f]
for k in range(K) {
for index in range(indice_pair[k].length()) {
{i, j} = indice_pair[k, index];
value[j] += feats[k, index];
}
} return value;
}
并行版本的稀疏卷积
参考文献
目标检测 | Spatially Sparse Convolution的更多相关文章
- QueryDet: Cascaded Sparse Query for Accelerating High-Resolution Small Object Detection(QueryDet:用于加速高分辨率小目标检测的级联稀疏查询)
QueryDet: Cascaded Sparse Query for Accelerating High-Resolution Small Object Detection(QueryDet:用于加 ...
- CVPR2020论文解读:3D Object Detection三维目标检测
CVPR2020论文解读:3D Object Detection三维目标检测 PV-RCNN:Point-Voxel Feature Se tAbstraction for 3D Object Det ...
- 目标检测----ImageAI使用
1.开源项目 github地址 https://github.com/OlafenwaMoses/ImageAI 2.目标检测(Object Detection)入门概要 3.Pycharm中无法 ...
- (转)如何用TensorLayer做目标检测的数据增强
数据增强在机器学习中的作用不言而喻.和图片分类的数据增强不同,训练目标检测模型的数据增强在对图像做处理时,还需要对图片中每个目标的坐标做相应的处理.此外,位移.裁剪等操作还有可能使得一些目标在处理后只 ...
- 目标检测网络之 R-FCN
R-FCN 原理 R-FCN作者指出在图片分类网络中具有平移不变性(translation invariance),而目标在图片中的位置也并不影响分类结果;但是检测网络对目标的位置比较敏感.因此Fas ...
- 从YOLOv1到YOLOv3,目标检测的进化之路
https://blog.csdn.net/guleileo/article/details/80581858 本文来自 CSDN 网站,作者 EasonApp. 作者专栏: http://dwz.c ...
- 目标检测算法—YOLO-V1
为什么会叫YOLO呢? YOLO:you only look once.只需要看一眼,就可以检测识别出目标,主要是突出这个算法 快 的特点.(原文:Yolo系列之前的文章:主要是rcnn系列的,他们的 ...
- [转]CNN目标检测(一):Faster RCNN详解
https://blog.csdn.net/a8039974/article/details/77592389 Faster RCNN github : https://github.com/rbgi ...
- [DeeplearningAI笔记]卷积神经网络3.1-3.5目标定位/特征点检测/目标检测/滑动窗口的卷积神经网络实现/YOLO算法
4.3目标检测 觉得有用的话,欢迎一起讨论相互学习~Follow Me 3.1目标定位 对象定位localization和目标检测detection 判断图像中的对象是不是汽车--Image clas ...
- 语义分割(semantic segmentation) 常用神经网络介绍对比-FCN SegNet U-net DeconvNet,语义分割,简单来说就是给定一张图片,对图片中的每一个像素点进行分类;目标检测只有两类,目标和非目标,就是在一张图片中找到并用box标注出所有的目标.
from:https://blog.csdn.net/u012931582/article/details/70314859 2017年04月21日 14:54:10 阅读数:4369 前言 在这里, ...
随机推荐
- Dapr-3: 从 20000 英尺之上俯瞰 Dapr
第 3 章 从 20000 英尺之上俯瞰 Dapr Dapr at 20,000 feet | Microsoft Docs 在第 1 章中,我们讨论了分布式微服务应用的吸引力.但是,我们也指出了它会 ...
- JVM简介—2.垃圾回收器和内存分配策略
大纲 1.垃圾回收概述 2.如何判断对象存活 3.各种引用介绍 4.垃圾收集的算法 5.垃圾收集器的设计 6.垃圾回收器列表 7.各种垃圾回收器详情 8.Stop The World现象 9.内存分配 ...
- 干掉EasyExcel!FastExcel初体验
我们知道 EasyExcel 在作者从阿里离职之后就停止维护了,但在前两周 EasyExcel 原作者推出了他的升级版框架 FastExcel.以下是 FastExcel 的上手实战过程,带大家一起提 ...
- Qt/C++中英输入法/嵌入式输入法/小数字面板/简繁切换/特殊字符/支持Qt456
一.前言 在嵌入式板子上由于没有系统层面的输入法支持,所以都绕不开一个问题,那就是在需要输入的UI软件中,必须提供一个输入法来进行输入,大概从Qt5.7开始官方提供了输入法的源码,作为插件的形式加入到 ...
- Qt/C++音视频开发46-音视频同步保存到MP4
一.前言 用ffmpeg单独做视频保存不难,单独做音频保存也不难,难的是音视频同步保存到MP4中,重点是音视频要同步,其实这也不难,只要播放那边音视频同步后的数据,写入到文件即可.最难的是在播放过程中 ...
- Qt音视频开发16-mpv通用接口
一.前言 前面几篇文章,依次讲了解码播放.录像存储.读取和控制.事件订阅等,其实这些功能的实现都离不开封装的通用的接口,最开始本人去调用一些设置的时候,发现多参数的不好实现,原来需要用mpv_node ...
- [转]OpenCV使用之-----BruteForceMatcher无法使用
最近Opencv升级比较快,从2.4.0到2.4.1到2.4.2,使得我这个还在使用2.3.1的人很不好意思,而且听说新版本里添加了tbb并行功能,急着想用这些功能的我赶紧下了2.4.2. 按部就班的 ...
- Win10离线安装.NET Framework 3.5的方法技巧
Win10离线安装.NET Framework 3.5的方法技巧 PC系统为win10,在使用过程中,曾遇到提示说 "你的电脑上的应用需要使用以下Windows功能:.NET Framewo ...
- uniapp请求封装-token无感刷新
当前是vue3+ts版本的封装 vue3+js版本请求封装可参考 https://www.cnblogs.com/lovejielive/p/14343619.html token无感刷新,可自行删除 ...
- 在Deepin系统上配置微软Windows远程桌面服务
. 前言 本文主要讲解如何在deepin系统上安装和配置Xrdp远程桌面. Xrdp是微软的远程桌面协议(Remote Desktop Protocol, RDP)的开源版本.在Linux系统上安装X ...