大数据之路Week08_day02 (Flume 三个组件Source, channel, sink)
在使用之前,先介绍组件Flume的特点和一些组件
Flume的优势:
1. Flume可以将应用产生的数据存储到任何集中存储器中,比如HDFS,HBase
2. 当收集数据的速度超过将写入数据的时候,也就是当收集信息遇到峰值时,这时候收集的信息非常大,甚至超过了系统的写入数据能力,这时候,Flume会在数据生产者和数据收容器间做出调整,保证其能够在两者之间提供平稳的数据.
3. 提供上下文路由特征
4. Flume的管道是基于事务,保证了数据在传送和接收时的一致性.
5. Flume是可靠的,容错性高的,可升级的,易管理的,并且可定制的。
Flume的特征:
1. Flume可以高效率的将多个网站服务器中收集的日志信息存入HDFS/HBase中
2. 使用Flume,我们可以将从多个服务器中获取的数据迅速的移交给Hadoop中
3. 除了日志信息,Flume同时也可以用来接入收集规模宏大的社交网络节点事件数据,比如facebook,twitter,电商网站如亚马逊,flipkart等
4. 支持各种接入资源数据的类型以及接出数据类型
5. 支持多路径流量,多管道接入流量,多管道接出流量,上下文路由等
6. 可以被水平扩展
============================================================================================================================================================
Flume的三个组件:
1、Source
是数据的收集端,负责将数据捕获后进行特殊的格式化,将数据封装到事件(event) 里,然后将事件推入Channel中。 Flume提供了很多内置的Source, 支持 Avro, log4j, syslog 和 http post(body为json格式)。可以让应用程序同已有的Source直接打交道,如AvroSource 如果内置的Source无法满足需要, Flume还支持自定义Source。
source的类型:
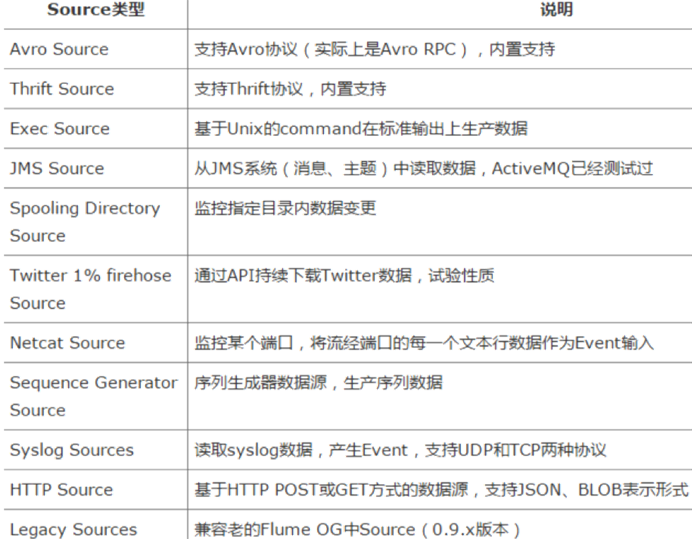
Source具体作用:
AvroSource:监听一个avro服务端口,采集Avro数据序列化后的数据;
Thrift Source:监听一个Thrift 服务端口,采集Thrift数据序列化后的数据;
Exec Source:基于Unix的command在标准输出上采集数据;
JMS Source:Java消息服务数据源,Java消息服务是一个与具体平台无关的API,这是支持jms规范的数据源采集;
Spooling Directory Source:通过文件夹里的新增的文件作为数据源的采集;【测试header】
Kafka Source:从kafka服务中采集数据。
NetCat Source: 绑定的端口(tcp、udp),将流经端口的每一个文本行数据作为Event输入
HTTP Source:监听HTTP POST和 GET产生的数据的采集
=================================================================================================================================================
2、Channel
Channel是连接Source和Sink的组件,大家可以将它看做一个数据的缓冲区(数据队列),它可以将事件暂存到内存中也可以持久化到本地磁盘上, 直到Sink处理完该事件。
介绍两个较为常用的Channel : MemoryChannel和FileChannel。

Channel:一个数据的存储池,中间通道。
主要作用:接受source传出的数据,向sink指定的目的地传输。Channel中的数据直到进入到下一个channel中或者进入终端才会被删除。当sink写入失败后,可以自动重写,不会造成数据丢失,因此很可靠。 channel的类型很多比如:内存中、jdbc数据源中、文件形式存储等。
常见采集的数据类型: Memory Channel、File Channel、JDBC Channel、Kafka Channel等
详细查看: http://flume.apache.org/FlumeUserGuide.html#flume-channels
Channel具体作用:
Memory Channel:使用内存作为数据的存储。
JDBC Channel:使用jdbc数据源来作为数据的存储。
Kafka Channel:使用kafka服务来作为数据的存储。
File Channel:使用文件来作为数据的存储。
Spillable Memory Channel:使用内存和文件作为数据的存储,即:先存在内存中,如果内存中数据达到阀值则flush到文件中。
=============================================================================================================================================================
3、Sink
Sink从Channel中取出事件,然后将数据发到别处,可以向文件系统、数据库、 hadoop存数据, 也可以是其他agent的Source。在日志数据较少时,可以将数据存储在文件系统中,并且设定一定的时间间隔保存数据。
Sink:数据的最终的目的地.
主要作用:接受channel写入的数据以指定的形式表现出来(或存储或展示)。 sink的表现形式很多比如:打印到控制台、hdfs上、avro服务中、文件中等。
常见采集的数据类型: HDFS Sink、Hive Sink、Logger Sink、Avro Sink、Thrift Sink、File Roll Sink、HBaseSink、Kafka Sink等
详细查看: http://flume.apache.org/FlumeUserGuide.html#flume-sinks HDFSSink需要有hdfs的配置文件和类库。
一般采取多个sink汇聚到一台采集机器负责推送到hdfs。
Sink具体作用:
HDFS Sink:将数据传输到hdfs集群中。
Hive Sink:将数据传输到hive的表中。
Logger Sink:将数据作为日志处理(根据flume中的设置的日志的级别显示)。
Avro Sink:数据被转换成Avro Event,然后发送到配置的RPC端口上。
Thrift Sink:数据被转换成Thrift Event,然后发送到配置的RPC端口上。
IRC Sink:数据向指定的IRC服务和端口中发送。
File Roll Sink:数据传输到本地文件中。
Null Sink:取消数据的传输,即不发送到任何目的地。
HBaseSink:将数据发往hbase数据库中。
MorphlineSolrSink:数据发送到Solr搜索服务器(集群)。
ElasticSearchSink:数据发送到Elastic Search搜索服务器(集群)。
Kafka Sink:将数据发送到kafka服务中。
Flume 使用事务性的方式保证传送Event整个过程的可靠性。
Sink 必须在Event 被存入Channel 后,或者,已经被传达到下一站agent里,又或者,已经被存入外部数据目的地之后,才能把 Event 从 Channel 中 remove 掉。这样数据流里的 event 无论是在一个 agent 里还是多个 agent 之间流转,都能保证可靠,因为以上的事务保证了 event 会被成功存储起来。比如 Flume支持在本地保存一份文件 channel 作为备份,而memory channel 将event存在内存 queue 里,速度快,但丢失的话无法恢复。
大数据之路Week08_day02 (Flume 三个组件Source, channel, sink)的更多相关文章
- 大数据入门第十二天——flume入门
一.概述 1.什么是flume 官网的介绍:http://flume.apache.org/ Flume is a distributed, reliable, and available servi ...
- 大数据之路week04--day03(网络编程)
哎,怎么感觉自己变得懒了起来,更新博客的频率变得慢了起来,可能是因为最近得知识开始变得杂变得难了起来,之前在上课的时候,也没有好好听这一方面的知识,所以,现在可以说是在学的新的知识,要先去把新的知识思 ...
- 大数据【八】Flume部署
如果说大数据中分布式收集日志用的是什么,你完全可以回答Flume!(面试小心问到哦) 首先说一个复制本服务器文件到目标服务器上,需要目标服务器的ip和密码: 命令: scp filename i ...
- 大数据之路week06--day07(Hadoop生态圈的介绍)
Hadoop 基本概念 一.Hadoop出现的前提环境 随着数据量的增大带来了以下的问题 (1)如何存储大量的数据? (2)怎么处理这些数据? (3)怎样的高效的分析这些数据? (4)在数据增长的情况 ...
- 大数据之路week04--day06(I/O流阶段一 之异常)
从这节开始,进入对I/O流的系统学习,I/O流在往后大数据的学习道路上尤为重要!!!极为重要,必须要提起重视,它与集合,多线程,网络编程,可以说在往后学习或者是工作上,起到一个基石的作用,没了地基,房 ...
- C#码农的大数据之路 - 使用C#编写MR作业
系列目录 写在前面 从Hadoop出现至今,大数据几乎就是Java平台专属一般.虽然Hadoop或Spark也提供了接口可以与其他语言一起使用,但作为基于JVM运行的框架,Java系语言有着天生优势. ...
- 胖子哥的大数据之路(11)-我看Intel&&Cloudera的合作
一.引言 5月8日,作为受邀嘉宾,参加了Intel与Cloudera在北京中国大饭店新闻发布会,两家公司宣布战略合作,该消息成为继Intel宣布放弃大数据平台之后的另外一个热点新闻.对于Intel的放 ...
- 胖子哥的大数据之路(10)- 基于Hive构建数据仓库实例
一.引言 基于Hive+Hadoop模式构建数据仓库,是大数据时代的一个不错的选择,本文以郑商所每日交易行情数据为案例,探讨数据Hive数据导入的操作实例. 二.源数据-每日行情数据 三.建表脚本 C ...
- 胖子哥的大数据之路(9)-数据仓库金融行业数据逻辑模型FS-LDM
引言: 大数据不是海市蜃楼,万丈高楼平地起只是意淫,大数据发展还要从点滴做起,基于大数据构建国家级.行业级数据中心的项目会越来越多,大数据只是技术,而非解决方案,同样面临数据组织模式,数据逻辑模式的问 ...
- 胖子哥的大数据之路(7)- 传统企业切入核心or外围
一.引言 昨天和一个做互联网大数据(零售行业)的朋友交流,关于大数据传统企业实施的切入点产生了争执,主要围绕两个问题进行了深入的探讨: 问题1:对于一个传统企业而言什么是核心业务,什么是外围业务? 问 ...
随机推荐
- Kettle用查出来的数据自动创建表
Kettle在表输入的时候,写好很复杂的SQL,有种场景,就是想把这个很复杂的查出来的数据,自动创建一个表. 其实,操作步骤不复杂. 跟着我来做就是了. 1,新建表输出,Shift按住,从表输入拖动 ...
- VS Code 变身小霸王游戏机!
在韩老师的<Visual Studio Code 权威指南>一书中,我向大家推荐了许多好用的插件,其中也不乏许多摸鱼插件,刷知乎.炒股票.看电影.听音乐.追番.看小说,一应俱全. 今天,就 ...
- Not all slots covered! Only 5461 slots are available. Set checkSlotsCoverage = false to avoid this check
Not all slots covered! Only 5461 slots are available. Set checkSlotsCoverage = false to avoid this c ...
- Qt编写地图综合应用13-获取边界点
一.前言 获取边界点一般和行政区划搭配起来使用,比如用户输入一个省市的名称,然后自动定位到该省市,然后对该轮廓获取所有边界点集合输出到js文件,最后供离线使用,获取边界点还有一个功能就是获取当前区域内 ...
- C#HTTP网络编程的一般流程
1.同步HTTP网络要求 //第1步: 送出要求 string url="https://www.baidu.com/"; HttpWebRequest request = (Ht ...
- 在已有的项目中使用vuiew ui库
官方提供了三种方式,但是我觉得在已有的项目中使用是比较常见的 我在刚开始使用的时候不知道如何使用,我希望这个对大家有点帮助,特此来记录下! 我用的是创建了一个uview插件的项目,然后把里面uview ...
- LOL(英雄联盟) API 接口
/*LOL(英雄联盟) API 接口 By wgscd /*LOL(英雄联盟) API 接口 By wgscd QQ:1009374598 */ GET https://127.0.0.1:58182 ...
- MySQL-进阶篇
一.连接查询 图解示意图 1.建表语句 部门和员工关系表: CREATE TABLE `tb_dept` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT ...
- kafka的server.properties文件描述
版本:基于 kafka 2.4.0 http://archive.apache.org/dist/kafka/2.4.0/kafka_2.11-2.4.0.tgz # Licensed to the ...
- 脱离实体类操作数据库(mysql版本)
原理很简单:1.利用mysql的information_schema库,获取对用表的信息: 2.使用DataSource,建立数据库连接,并执行sql脚本: 3.Map的keySet和values集合 ...