count(*) count(1) count(字段)效率问题
COUNT(字段名)和COUNT(*)的查询结果有什么不同?
COUNT(1)和COUNT(*)之间的效率哪个更高?
你知道答案吗?很多人都认为COUNT(1)比COUNT(*)效率高,真的是这样吗?
1、认识COUNT
关于COUNT函数,在MySQL官网中有详细介绍:
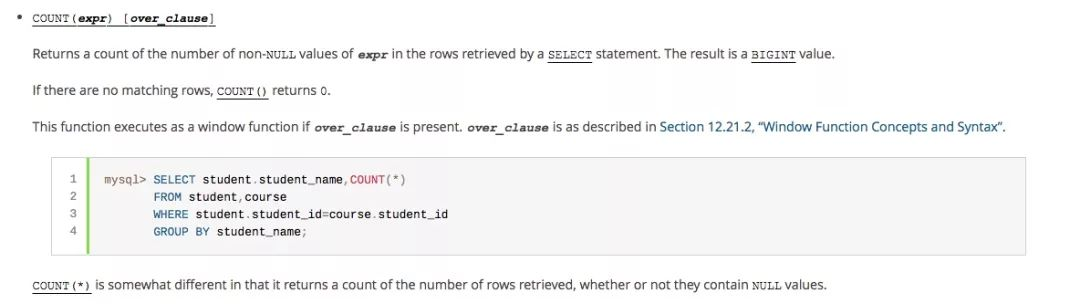
简单翻译一下:
1、COUNT(expr) ,返回SELECT语句检索的行中expr的值不为NULL的数量。结果是一个BIGINT值。
2、如果查询结果没有命中任何记录,则返回0
3、但是,值得注意的是,COUNT(*) 的统计结果中,会包含值为NULL的行数。
即以下表记录
create table #bla(id int,id2 int)
insert #bla values(null,null)
insert #bla values(1,null)
insert #bla values(null,1)
insert #bla values(1,null)
insert #bla values(null,1)
insert #bla values(1,null)
insert #bla values(null,null)
使用语句count(*),count(id),count(id2)查询结果如下:
select count(*),count(id),count(id2)
from #bla
results 7 3 2
除了COUNT(id)和COUNT(*)以外,还可以使用COUNT(常量)(如COUNT(1))来统计行数,那么这三条SQL语句有什么区别呢?到底哪种效率更高呢?为什么《阿里巴巴Java开发手册》中强制要求不让使用 COUNT(列名)或 COUNT(常量)来替代 COUNT(*)呢?
COUNT(列名)、COUNT(常量)和COUNT(*)之间的区别
前面我们提到过COUNT(expr)用于做行数统计,统计的是expr不为NULL的行数,那么COUNT(列名)、 COUNT(常量) 和 COUNT(*)这三种语法中,expr分别是列名、 常量 和 *。
那么列名、 常量 和 *这三个条件中,常量 是一个固定值,肯定不为NULL。*可以理解为查询整行,所以肯定也不为NULL,那么就只有列名的查询结果有可能是NULL了。
所以, COUNT(常量) 和 COUNT(*)表示的是直接查询符合条件的数据库表的行数。而COUNT(列名)表示的是查询符合条件的列的值不为NULL的行数。
除了查询得到结果集有区别之外,COUNT(*)相比COUNT(常量) 和COUNT(列名)来讲,COUNT(*)是SQL92定义的标准统计行数的语法,因为他是标准语法,所以MySQL数据库对他进行过很多优化。
SQL92,是数据库的一个ANSI/ISO标准。它定义了一种语言(SQL)以及数据库的行为(事务、隔离级别等)。
COUNT(*)的优化
前面提到了COUNT(*)是SQL92定义的标准统计行数的语法,所以MySQL数据库对他进行过很多优化。那么,具体都做过哪些事情呢?
这里的介绍要区分不同的执行引擎。MySQL中比较常用的执行引擎就是InnoDB和MyISAM。
MyISAM和InnoDB有很多区别,其中有一个关键的区别和我们接下来要介绍的COUNT(*)有关,那就是MyISAM不支持事务,MyISAM中的锁是表级锁;而InnoDB支持事务,并且支持行级锁。
因为MyISAM的锁是表级锁,所以同一张表上面的操作需要串行进行,所以,MyISAM做了一个简单的优化,那就是它可以把表的总行数单独记录下来,如果从一张表中使用COUNT(*)进行查询的时候,可以直接返回这个记录下来的数值就可以了,当然,前提是不能有where条件。
MyISAM之所以可以把表中的总行数记录下来供COUNT(*)查询使用,那是因为MyISAM数据库是表级锁,不会有并发的数据库行数修改,所以查询得到的行数是准确的。
但是,对于InnoDB来说,就不能做这种缓存操作了,因为InnoDB支持事务,其中大部分操作都是行级锁,所以可能表的行数可能会被并发修改,那么缓存记录下来的总行数就不准确了。
但是,InnoDB还是针对COUNT(*)语句做了些优化的。
在InnoDB中,使用COUNT(*)查询行数的时候,不可避免的要进行扫表了,那么,就可以在扫表过程中下功夫来优化效率了。
从MySQL 8.0.13开始,针对InnoDB的SELECT COUNT(*) FROM tbl_name语句,确实在扫表的过程中做了一些优化。前提是查询语句中不包含WHERE或GROUP BY等条件。
我们知道,COUNT(*)的目的只是为了统计总行数,所以,他根本不关心自己查到的具体值,所以,他如果能够在扫表的过程中,选择一个成本较低的索引进行的话,那就可以大大节省时间。
我们知道,InnoDB中索引分为聚簇索引(主键索引)和非聚簇索引(非主键索引),聚簇索引的叶子节点中保存的是整行记录,而非聚簇索引的叶子节点中保存的是该行记录的主键的值。
所以,相比之下,非聚簇索引要比聚簇索引小很多,所以MySQL会优先选择最小的非聚簇索引来扫表。所以,当我们建表的时候,除了主键索引以外,创建一个非主键索引还是有必要的。
至此,我们介绍完了MySQL数据库对于COUNT(*)的优化,这些优化的前提都是查询语句中不包含WHERE以及GROUP BY条件。
COUNT(*)和COUNT(1)
介绍完了COUNT(*),接下来看看COUNT(1),对于,这二者到底有没有区别,网上的说法众说纷纭。
有的说COUNT(*)执行时会转换成COUNT(1),所以COUNT(1)少了转换步骤,所以更快。
还有的说,因为MySQL针对COUNT(*)做了特殊优化,所以COUNT(*)更快。
那么,到底哪种说法是对的呢?看下MySQL官方文档是怎么说的:
InnoDB handles SELECT COUNT(*) and SELECT COUNT(1) operations in the same way. There is no performance difference.
画重点:same way , no performance difference。所以,对于COUNT(1)和COUNT(*),MySQL的优化是完全一样的,根本不存在谁比谁快!
那既然COUNT(*)和COUNT(1)一样,建议用哪个呢?
建议使用COUNT(*)!因为这个是SQL92定义的标准统计行数的语法,而且本文只是基于MySQL做了分析,关于Oracle中的这个问题,也是众说纷纭的呢。
COUNT(字段)
最后,就是我们一直还没提到的COUNT(字段),他的查询就比较简单粗暴了,就是进行全表扫描,然后判断指定字段的值是不是为NULL,不为NULL则累加。
相比COUNT(*),COUNT(字段)多了一个步骤就是判断所查询的字段是否为NULL,所以他的性能要比COUNT(*)慢。
总结
本文介绍了COUNT函数的用法,主要用于统计表行数。主要用法有COUNT(*)、COUNT(字段)和COUNT(1)。
因为COUNT(*)是SQL92定义的标准统计行数的语法,所以MySQL对他进行了很多优化,MyISAM中会直接把表的总行数单独记录下来供COUNT(*)查询,而InnoDB则会在扫表的时候选择最小的索引来降低成本。当然,这些优化的前提都是没有进行where和group的条件查询。
在InnoDB中COUNT(*)和COUNT(1)实现上没有区别,而且效率一样,但是COUNT(字段)需要进行字段的非NULL判断,所以效率会低一些。
因为COUNT(*)是SQL92定义的标准统计行数的语法,并且效率高,所以请直接使用COUNT(*)查询表的行数!
————————————————
版权声明:本文为CSDN博主「yz_wlkj」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/pyzfirst/article/details/108521334
count(*) count(1) count(字段)效率问题的更多相关文章
- MySQL的统计总数count(*)与count(id)或count(字段)的之间的各自效率性能对比
执行效果: 1. count(1) and count(*) 当表的数据量大些时,对表作分析之后,使用count(1)还要比使用count(*)用时多了! 从执行计划来看,count(1)和cou ...
- mysql 5.7中 count(0) count(*) count(主键) count(非空字段)效率比较
mysql count(0) count(*) count(主键) count(非空字段) 效率比较 写代码的时候经理在背后说了一句count(0)的效率高于count(*) ,索性全部测试了一下 结 ...
- 关于数据库优化1——关于count(1),count(*),和count(列名)的区别,和关于表中字段顺序的问题
1.关于count(1),count(*),和count(列名)的区别 相信大家总是在工作中,或者是学习中对于count()的到底怎么用更快.一直有很大的疑问,有的人说count(*)更快,也有的人说 ...
- MySql-count(*)与count(id)与count(字段)之间的执行结果和性能分析
在mysql数据库中,当我们需要统计数据的时候,一定会用到count()这个方法,那么count(值)里面的这个值,到底应该怎么选择呢!常见有3种选择,(*,数字,列名),分别列出它们的执行结果和性能 ...
- MySQL学习笔记:count(1)、count(*)、count(字段)的区别
关于数据库中行数统计,无论是MySQL还是Oracle,都有一个函数可以使用,那就是COUNT. 但是,就是这个常用的COUNT函数,却暗藏着很多玄机,尤其是在面试的时候,一不小心就会被虐.不信的话请 ...
- count(1)、count(*)、count(字段)的区别
count(1)和count(*): 都为统计所有记录数,包括null 执行效率上:当数据量1W+时count(*)用时较少,1w以内count(1)用时较少 count(字段): 统计字段列的行数, ...
- count(1)比count(*)效率高?
SELECT COUNT(*) FROM table_name是个再常见不过的统计需求了. 本文带你了解下Mysql的COUNT函数. 一.COUNT函数 关于COUNT函数,在MySQL官网中有详细 ...
- 你还在认为 count(1) 比 count(*) 效率高?
你还在认为 count(1) 比 count(*) 效率高? 3 很多人认为count(1)执行的效率会比count()高,原因是count()会存在全表扫描,而count(1)可以针对一个字段进行查 ...
- 图解MySQL:count(*) 、count(1) 、count(主键字段)、count(字段)哪个性能最好?
大家好,我是小林. 当我们对一张数据表中的记录进行统计的时候,习惯都会使用 count 函数来统计,但是 count 函数传入的参数有很多种,比如 count(1).count(*).count(字段 ...
- Count(*), Count(1) 和Count(字段)的区别
1. count(1) and count(*) 当表的数据量大些时,对表作分析之后,使用count(1)还要比使用count(*)用时多了! 从执行计划来看,count(1)和count(*)的 ...
随机推荐
- OSIDP-并发:死锁和饥饿-06
死锁原理 死锁:一组相互竞争系统资源或者进行通信的进程间"永久"阻塞的现象. 资源分为两类:可重用资源和可消耗资源. 可重用资源:一次只能被一个进程使用且不会被耗尽的资源.如处理器 ...
- 【Unity】利用C#反射打印类的字段信息
最近在用protobuf-net序列化功能生成.bytes配置文件时,遇到了需要把.bytes配置文件再另外转成Lua配置文件(Lua配置表内容举例)的需求.Lua配置文件需要记录配置类的各个字段名和 ...
- C++ Primer 15.9文本查找程序
可以通过查询语句的组合进行检索,VS2015. main函数,读取存有数据的文件,进行检索.提供两种入口.查词,与按照表达式查询. 1 #include <iostream> 2 #inc ...
- 用C#语言实现记事本
一.实验内容: 二.记事本所需功能: (1)记事本程序具有文件的新建.打开.保存功能: (2)文字的复制.粘贴.删除功能:字体类型.格式的设置功能: (3)查看日期时间等功能,并且用户可三根据需要显示 ...
- abp框架+mysql 数据库 执行批量新增和修改
protected override async Task ExecuteAsync(CancellationToken stoppingToken) { while (!stoppingToken. ...
- Leecode 53.最大子数组和(Java 贪心算法、动态规划两种方法)
想法(没看解析之前想不出来) -----------------看了解析和答案 1.贪心算法,若当前元素的之前和<0,则丢弃当前元素之前的数列 设一个maxSum作为子序列最大和,一个sum ...
- 华大单片机HC32L13X软件设计时候要注意的事项
1.系统启动时默认设置主频为内部4MHz; 2.调试超低功耗程序或者把SWD端口复用为GPIO功能都会把芯片的SWD功能关掉,仿真器将会与芯片失去连接,建议在main函数开始后加上1到2秒的延时,仿真 ...
- 三天吃透MySQL面试八股文
本文已经收录到Github仓库,该仓库包含计算机基础.Java基础.多线程.JVM.数据库.Redis.Spring.Mybatis.SpringMVC.SpringBoot.分布式.微服务.设计模式 ...
- Flink基本概念及架构
1.基本概念 无界和有界数据.任何类型的数据都可以形成一种事件流.信用卡交易.传感器测量.机器日志.网站或移动应用程序上的用户交互记录,所有这些数据都形成一种流.数据可以被作为 无界 或者 有界 流来 ...
- Django笔记四之字段属性
这篇笔记介绍的 field options,也就是 字段的选项属性. 首先,关于 model,是数据库与 python 代码里的一个映射关系,每一个 model 是django.db.models.M ...