经典的损失函数:交叉熵和MSE
经典的损失函数:
①交叉熵(分类问题):判断一个输出向量和期望向量有多接近。交叉熵刻画了两个概率分布之间的距离,他是分类问题中使用比较广泛的一种损失函数。概率分布刻画了不同事件发生的概率。
熵的定义:解决了对信息的量化度量问题,香农用信息熵的概念来描述信源的不确定度,第一次用数学语言阐明了概率与信息冗余度的关系。



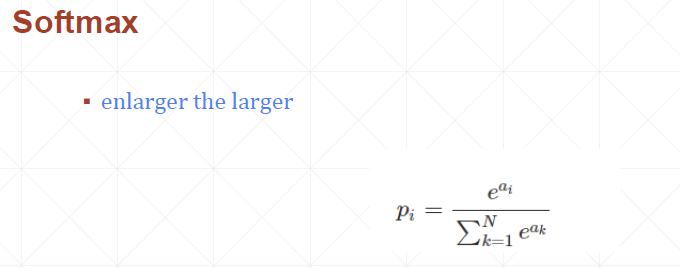
从统计方面看交叉熵损失函数的含义:
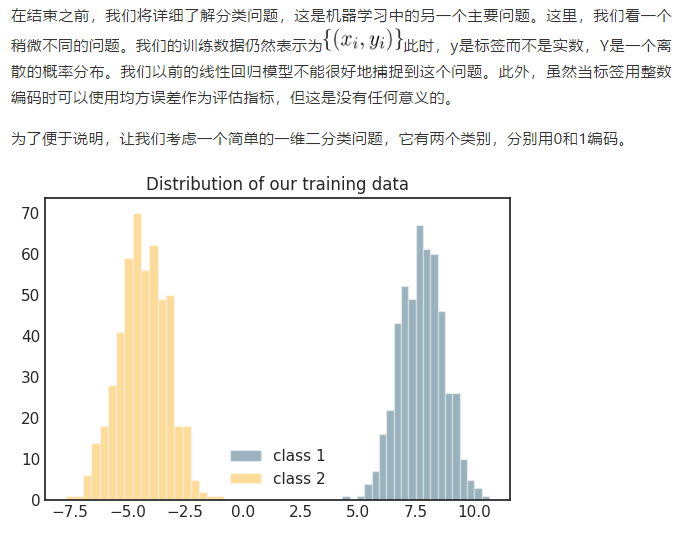


Softmax:原始神经网路的输出被作用在置信度来生成新的输出,新的输出满足概率分布的所有要求。这样就把神经网络的输出变成了一个概率分布,从而可以通过交叉熵来计算预测的概率分布和真实答案的概率分布之间的距离。
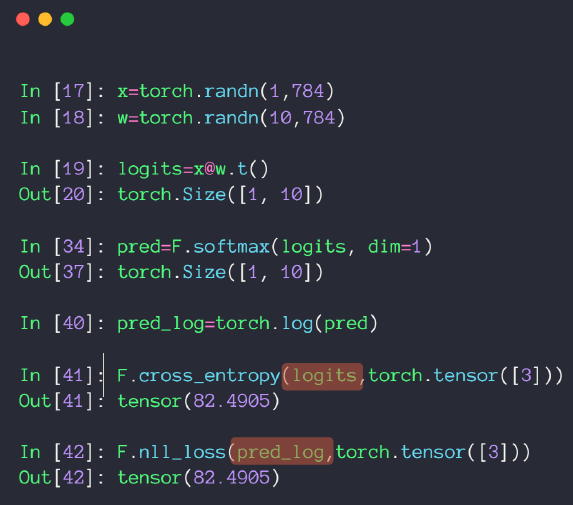
②回归问题解决的是对具体数值的预测。这些问题需要预测的不是一个事先定义好的类别,而是一个任意的实数。解决回归问题的神经网络一般只有一个输出结点,这个结点的输出值就是预测值。对于回归问题,最常用的损失函数就是均方误差(MSE,mean squared error):
经典的损失函数:交叉熵和MSE的更多相关文章
- 机器学习之路:tensorflow 深度学习中 分类问题的损失函数 交叉熵
经典的损失函数----交叉熵 1 交叉熵: 分类问题中使用比较广泛的一种损失函数, 它刻画两个概率分布之间的距离 给定两个概率分布p和q, 交叉熵为: H(p, q) = -∑ p(x) log q( ...
- TensorFlow笔记-06-神经网络优化-损失函数,自定义损失函数,交叉熵
TensorFlow笔记-06-神经网络优化-损失函数,自定义损失函数,交叉熵 神经元模型:用数学公式比表示为:f(Σi xi*wi + b), f为激活函数 神经网络 是以神经元为基本单位构成的 激 ...
- [ch03-02] 交叉熵损失函数
系列博客,原文在笔者所维护的github上:https://aka.ms/beginnerAI, 点击star加星不要吝啬,星越多笔者越努力. 3.2 交叉熵损失函数 交叉熵(Cross Entrop ...
- 【深度学习】softmax回归——原理、one-hot编码、结构和运算、交叉熵损失
1. softmax回归是分类问题 回归(Regression)是用于预测某个值为"多少"的问题,如房屋的价格.患者住院的天数等. 分类(Classification)不是问&qu ...
- 第五节,损失函数:MSE和交叉熵
损失函数用于描述模型预测值与真实值的差距大小,一般有两种比较常见的算法——均值平方差(MSE)和交叉熵. 1.均值平方差(MSE):指参数估计值与参数真实值之差平方的期望值. 在神经网络计算时,预测值 ...
- 经典损失函数:交叉熵(附tensorflow)
每次都是看了就忘,看了就忘,从今天开始,细节开始,推一遍交叉熵. 我的第一篇CSDN,献给你们(有错欢迎指出啊). 一.什么是交叉熵 交叉熵是一个信息论中的概念,它原来是用来估算平均编码长度的.给定两 ...
- 深度学习原理与框架-神经网络结构与原理 1.得分函数 2.SVM损失函数 3.正则化惩罚项 4.softmax交叉熵损失函数 5. 最优化问题(前向传播) 6.batch_size(批量更新权重参数) 7.反向传播
神经网络由各个部分组成 1.得分函数:在进行输出时,对于每一个类别都会输入一个得分值,使用这些得分值可以用来构造出每一个类别的概率值,也可以使用softmax构造类别的概率值,从而构造出loss值, ...
- 【联系】二项分布的对数似然函数与交叉熵(cross entropy)损失函数
1. 二项分布 二项分布也叫 0-1 分布,如随机变量 x 服从二项分布,关于参数 μ(0≤μ≤1),其值取 1 和取 0 的概率如下: {p(x=1|μ)=μp(x=0|μ)=1−μ 则在 x 上的 ...
- 【机器学习基础】交叉熵(cross entropy)损失函数是凸函数吗?
之所以会有这个问题,是因为在学习 logistic regression 时,<统计机器学习>一书说它的负对数似然函数是凸函数,而 logistic regression 的负对数似然函数 ...
随机推荐
- 5个容易忽视的PostgreSQL查询性能瓶颈
PostgreSQL 查询计划器充满了惊喜,因此编写高性能查询的常识性方法有时会产生误导.在这篇博文中,我将描述借助 EXPLAIN ANALYZE 和 Postgres 元数据分析优化看似显而易见的 ...
- 普罗米修斯!Ubuntu下prometheus监控软件安装使用
*Prometheus* 是一个开源的服务监控系统和时间序列数据库 官方网站:prometheus.io 一.安装prometheus cd /usr/local/ #进入安装目录 wg ...
- “如何实现集中管理、灵活高效的CI/CD”研讨会报名即将截止
如何实现集中管理.灵活高效的CI/CD ZOOM中文在线研讨会将于 2022年3月29日,星期二,下午3:00-5:00, 也就是 明天 举行, 如果您还未注册,点击按钮,立即注册此次研讨会(注册即可 ...
- mybaitis查询 (数据库与实体类字段名不相同)
1.这是我的数据库字段名和实体类字段名 2.方法 方法一: 查询的结果标题 会跟实体类的属性一一匹配,一定要一致就算数据库字段和属性不一致,我们可以把查询结果设置一个别名,让别名=属性名 方法二:使用 ...
- 深度长文:深入理解Ceph存储架构
点击上方"开源Linux",选择"设为星标" 回复"学习"获取独家整理的学习资料! 本文是一篇Ceph存储架构技术文章,内容深入到每个存储特 ...
- drools session理解
一.理解 在drools中存在2种session,一种是有状态的Session (Stateful Session),另外一种一种是无状态的Session (Stateless Session). 1 ...
- 请求扩展、蓝图、g对象
今日内容概要 请求扩展 蓝图 g对象 内容详细 1.请求扩展 # 在请求来了,请求走了,可以做一些校验和拦截,通过装饰器来实现 7 个 # 1 before_request 类比django中间件中的 ...
- Spring-Batch处理MySQL数据后存到CSV文件
1 介绍 用Spring Batch实现了个简单的需求,从MySQL中读取用户表数据,根据生日计算年龄,将结果输出到csv文件. 1.1 准备表及数据 user test; DROP TABLE IF ...
- 我使用Spring AOP实现了用户操作日志功能
我使用Spring AOP实现了用户操作日志功能 今天答辩完了,复盘了一下系统,发现还是有一些东西值得拿出来和大家分享一下. 需求分析 系统需要对用户的操作进行记录,方便未来溯源 首先想到的就是在每个 ...
- [C++STL] set 容器的入门
set 容器的入门 unordered_set:另外头文件,乱序排放,使用哈希表(便于查找) multiset:可以重复存在的集合.用count()读取个数 创建set的几种方式 常规 set< ...