使用batch-import工具向neo4j中导入海量数据【转】
转载备忘
链接:https://www.yisu.com/zixun/496254.html
这篇文章给大家分享的是有关数据库中怎么使用batch-import工具向neo4j中导入海量数据的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
1、batch-import原始项目地址:https://github.com/jexp/batch-import
这个工具是neo4j的作者之一Michael Hunger所编写,是在neo4j自带批量导入工具基础之上做的进一步优化,但是它在导入.gz压缩文件时,会出现关系无法导入的情况,所以如果要使用.gz压缩包进行导入,请使用我修改过的版本:https://github.com/mo9527/batch-import
2、环境准备
jdk:7以上
内存:8G以上,导入数据多的话会非常消耗内存,我自己导入的是将近1.5亿节点,3亿关系,用的是32G内存
3、导入步骤
a)从github上clone下代码,并使用maven进行打包,打完包后的jar文件,与项目本身的依赖jar一起放到lib文件夹下,batch.properties文件和执行导入的脚本放在lib同级目录下,***的目录结构如下图:
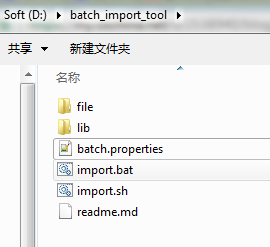
数据库中怎么使用batch-import工具向neo4j中导入海量数据
ps:file文件夹是我自己将要导入的csv文件和.gz压缩包。
b)组装csv文件
说起这一步,可能需要你们根据自己的实际业务需求,手动写代码导csv文件了,这里我只讲一下csv文件格式一些要点:
1)、节点csv文件
节点csv文件的***列是固定的,列值为此节点的label名称,第二列是index,它的列头是id:string:indexName 这种格式,解释一下,id是这一列的property名字,可以根据需要自己命名,string为字段的数据类型,indexName是neo4j数据库中将要导入的索引名称,我自己的文件格式如下:
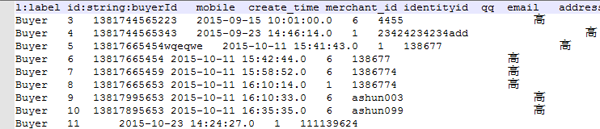
数据库中怎么使用batch-import工具向neo4j中导入海量数据
然后,后面的列就是节点的property了,没什么特别的要求
2)、关系csv文件
先看下我的关系csv文件:
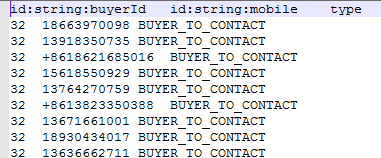
数据库中怎么使用batch-import工具向neo4j中导入海量数据
关系的csv文件前两列要特别注意,***列是关系的起始节点,第二列是关系的结束节点,第三列是关系类型,后面的列是关系的property,可以随意了。他github上的说明没有说出一些注意点,这里要特别标明:
***列的起始节点的列头,也就是id:string:buyerId这个东西,这个玩意一定要和节点csv文件(上图)中定义的一模一样,第二列也是如此,要和结束节点的csv文件里的一样,不然他会找不到对应的关系。
3)、修改batch.properties文件
主要修改两个地方,
如果是在现有的neo4j数据库中进行导入,请设置:
batch_import.keep_db=true
将节点csv文件中所有的索引名称加入到文件中,例如上面这个节点csv文件中的索引名称是buyerId,那就在文件中加入batch_import.node_index.buyerId=exact
以下是我本人的配置文件:
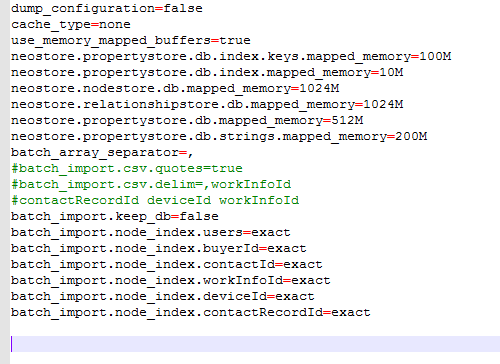
数据库中怎么使用batch-import工具向neo4j中导入海量数据
4、导入
linux和win环境的导入都差不多,只不过执行的脚本不一样,这里以win环境为例。
文件都准备好了,现在开始导入了。
打开cmd,cd到导入脚本的目录,也就是import.bat所在目录,执行命令:
import.bat test.db node.csv rel.csv
解释一下命令的几个参数:个参数是数据库的目录,可以绝对路径指定到任意位置,第二个参数是节点csv文件,多个csv文件用逗号分隔,如果是压缩包,一定要注意,这里有个坑,不能把所有类型的node都放到一个压缩包中,一定要每个类型的node分开压缩,不然它只会导入个类型的node节点,同理,关系的压缩包也要分开压缩,然后导入时用逗号分隔.gz文件。
好了,如果你的csv文件没有问题,内存足够用的话,现在就开始等待吧。
如果想修改导入工具的Heap大小,可以修改脚本文件中的 set HEAP=4G
数据库中怎么使用batch-import工具向neo4j中导入海量数据
温馨提示:如果节点文件中有中文的话,导入会非常慢的,除非你内存有128G,我有一个节点文件,里面只有一列是中文,而且中文最长不超过4个汉字,2000多万记录导了2个小时,注意我是32G内存,其他4000多万的节点,没有汉字的,基本上不超过2分钟。
感谢各位的阅读!关于“数据库中怎么使用batch-import工具向neo4j中导入海量数据”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/2538940/blog/883829
使用batch-import工具向neo4j中导入海量数据【转】的更多相关文章
- 使用neo4j图数据库的import工具导入数据 -方法和注意事项
背景 最近我在尝试存储知识图谱的过程中,接触到了Neo4j图数据库,这里我摘取了一段Neo4j的简介: Neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中.它是一个嵌 ...
- neo4j批量导入数据的两种解决方案
neo4j批量导入数据有两种方法,第一种是使用cypher语法中的LOAD CSV,第二种是使用neo4j自带的工具neo4j-admin import. LOAD CSV 导入的文件必须是csv文件 ...
- 使用GDAL工具对FY3系列卫星数据进行校正
本文档主要对如何使用GDAL提供的工具对FY3系列卫星数据进行校正处理.FY3系列卫星提供的数据一般是以HDF5格式下发,一个典型的FY3A和FY3B的数据文件名如下: FY3A_MERSI_GBAL ...
- spring batch 以游标的方式 数据库读取数据 然后写入目标数据库
前面关于Spring Batch的文章,讲述了SpringBatch对Flat.XML等文件的读写操作,本文将和大家一起讨论Spring Batch对DB的读写操作.Spring Batch对DB数据 ...
- Neo4j与ElasticSearch数据同步
Neo4j与ElasticSearch数据同步 针对节点删除,加了一些逻辑,代码地址 背景 需要强大的检索功能,所有需要被查询的数据都在neo4j. 方案 在Server逻辑中直接编写.后端有一个St ...
- Navicat工具、pymysql模块、数据备份
IDE工具介绍(Navicat) 生产环境还是推荐使用mysql命令行,但为了方便我们测试,可以使用IDE工具,我们使用Navicat工具,这个工具本质上就是一个socket客户端,可视化的连接mys ...
- web组件工具之获取表单数据:webUtils
本文需要的架包:commons-beanutils-1.8.3.jar.commons-logging-1.1.3.jar.servlet-api.jar. 本文共分为五部分:1)封装通用工具类:从表 ...
- [知识图谱]利用py2neo从Neo4j数据库获取数据
# -*- coding: utf-8 -*- from py2neo import Graph import json import re class Neo4jToJson(object): &q ...
- 使用POI导出EXCEL工具类并解决导出数据量大的问题
POI导出工具类 工作中常常会遇到一些图表需要导出的功能,在这里自己写了一个工具类方便以后使用(使用POI实现). 项目依赖 <dependency> <groupId>org ...
- 借助Spring工具类如何实现支持数据嵌套的赋值操作
假设有两个Bean A和B,想将B中的属性赋值到A实体中,可以使用get set来实现,当属性过多时,就会显得很冗余,可以使用spring提供的BeanUtils.copyProperties()来实 ...
随机推荐
- HBase详解(05) - HBase优化 整合Phoenix 集成Hive
HBase详解(05) - HBase优化 整合Phoenix 集成Hive HBase优化 预分区 每一个region维护着startRow与endRowKey,如果加入的数据符合某个region维 ...
- CVE-2022-32532 Apache Shiro 身份认证绕过
漏洞名称 CVE-2022-32532 Apache Shiro 身份认证绕过 利用条件 Apache Shiro < 1.9.1 漏洞原理 使用RegexRequestMatcher进行权限配 ...
- 消息队列(Message Query)的初学习
消息队列(Message Query)的初学习 摘要:本篇笔记主要记录了对于消息队列概念的初次学习.消息队列的基础知识. 目录 消息队列(Message Query)的初学习 1.何为消息? 2. ...
- .Net开发的系统安装或更新时如何避免覆盖用户自定义的配置
我们开发的系统,有时候会包含一些配置信息,需要用户在系统安装后自己去设置,例如我们有一个GPExSettings.xml文件,内容如下. <GPExSettings ArcPythonPath= ...
- forms组件渲染标签、展示信息、校验数据的一些补充,forms组件参数和源码剖析,modelform组件,Django中间
今日内容 forms组件渲染标签 forms组件渲染标签的方式1 <p>forms组件渲染标签的方式1</p> {{ form_obj.as_p }} {{ form_obj. ...
- 转载:SQL分页查询总结
[转载]SQL分页查询总结 开发过程中经常遇到分页的需求,今天在此总结一下吧. 简单说来方法有两种,一种在源上控制,一种在端上控制.源上控制把分页逻辑放在SQL层:端上控制一次性获取所有数据,把 ...
- 二、typora软件的安装与markdown语法
目录 一.typora软件的安装与使用 1.软件的安装 2.破解使用的方法 3.功能描述(markdown语法讲解) 标题 小标题 语言环境 表格 表情 图片 查看源代码 数学公式 流程图 高亮文本 ...
- spring-cloud03-consul
官网的安装说明https://learn.hashicorp.com/tutorials/consul/get-started-install 1.下载安装 环境:阿里云服务器,consul1.9.5 ...
- boot-repair
sudo add-apt-repository ppa:yannubuntu/boot-repair && sudo apt-get update sudo apt-get insta ...
- 编译报错,提示:This dependency was not found:* vue-editor-bridge
前端代码引入了: 1 import func from 'vue-editor-bridge'; 工具自动填充,导致引入上述JS去掉重新编译,问题解决