Python数据分析教程(二):Pandas
Pandas导入
- Pandas是Python第三方库,提供高性能易用数据类型和分析工具
- Pandas基于NumPy实现,常与NumPy和Matplotlib一同使用
- 两个数据类型:Series, DataFrame
import pandas as pd
Pandas与numpy的比较

Pandas的Series类型
由一组数据及与之相关的数据索引组成

Pandas的Series类型的创建
Series类型可以由如下类型创建:
- Python列表,index与列表元素个数一致
- 标量值,index表达Series类型的尺寸
- Python字典,键值对中的“键”是索引,index从字典中进行选择操作
- ndarray,索引和数据都可以通过ndarray类型创建
- 其他函数,range()函数等


Pandas的Series类型的基本操作
Series类型包含index和values两个部分:
- index 获得索引
- values 获得数据
由ndarray或字典创建的Series,操作类似ndarray或字典类型

pandas的DataFrame类型
DataFrame类型由共用相同索引的一组列组成
DataFrame是一个表格型的数据类型,每列值类型可以不同
DataFrame既有行索引、也有列索引
DataFrame常用于表达二维数据,但可以表达多维数据
DataFrame是二维带“标签”数组
DataFrame基本操作类似Series,依据行列索引

pandas的DataFrame类型创建
DataFrame类型可以由如下类型创建:
- 二维ndarray对象
- 由一维ndarray、列表、字典、元组或Series构成的字典
- Series类型
- 其他的DataFrame类型
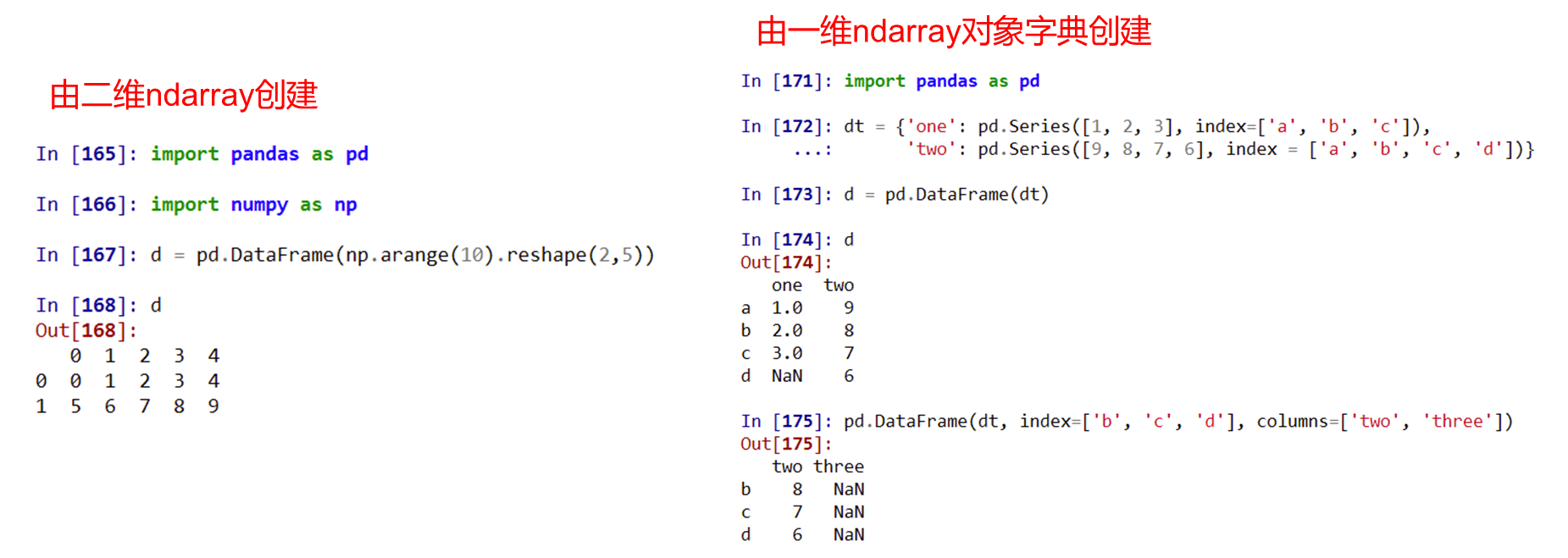

Pandas的Dataframe类型的基本操作
pandas索引操作
pandas重新索引
reindex()能够改变或重排Series和DataFrame索引
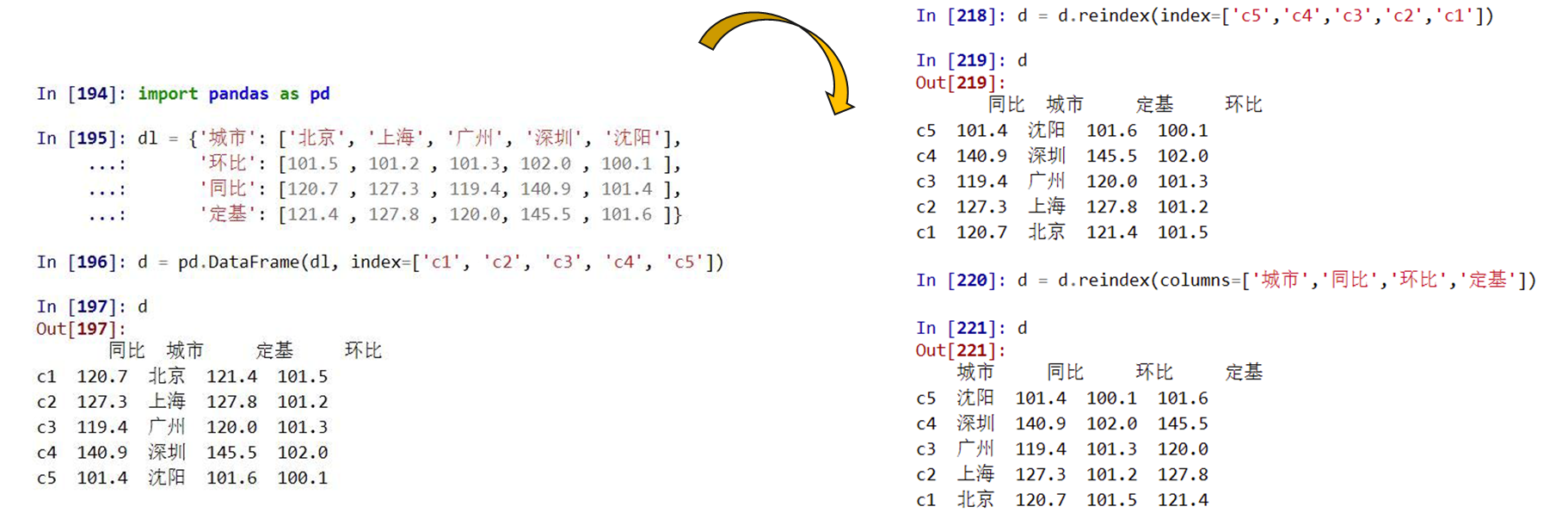
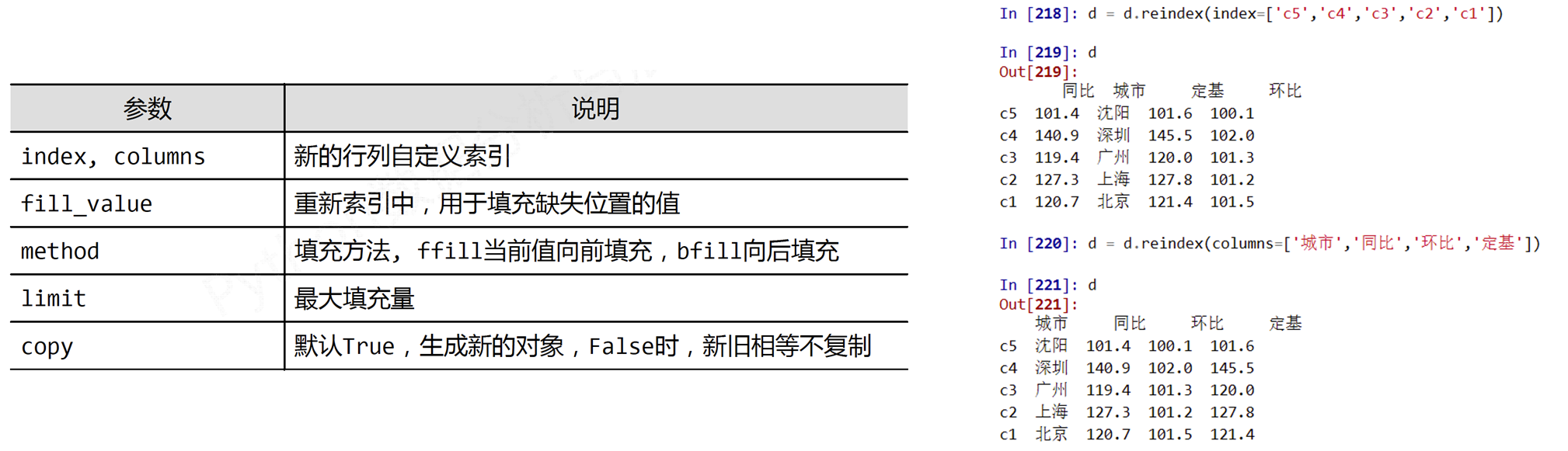
reindex(index=None, columns=None, …)的参数
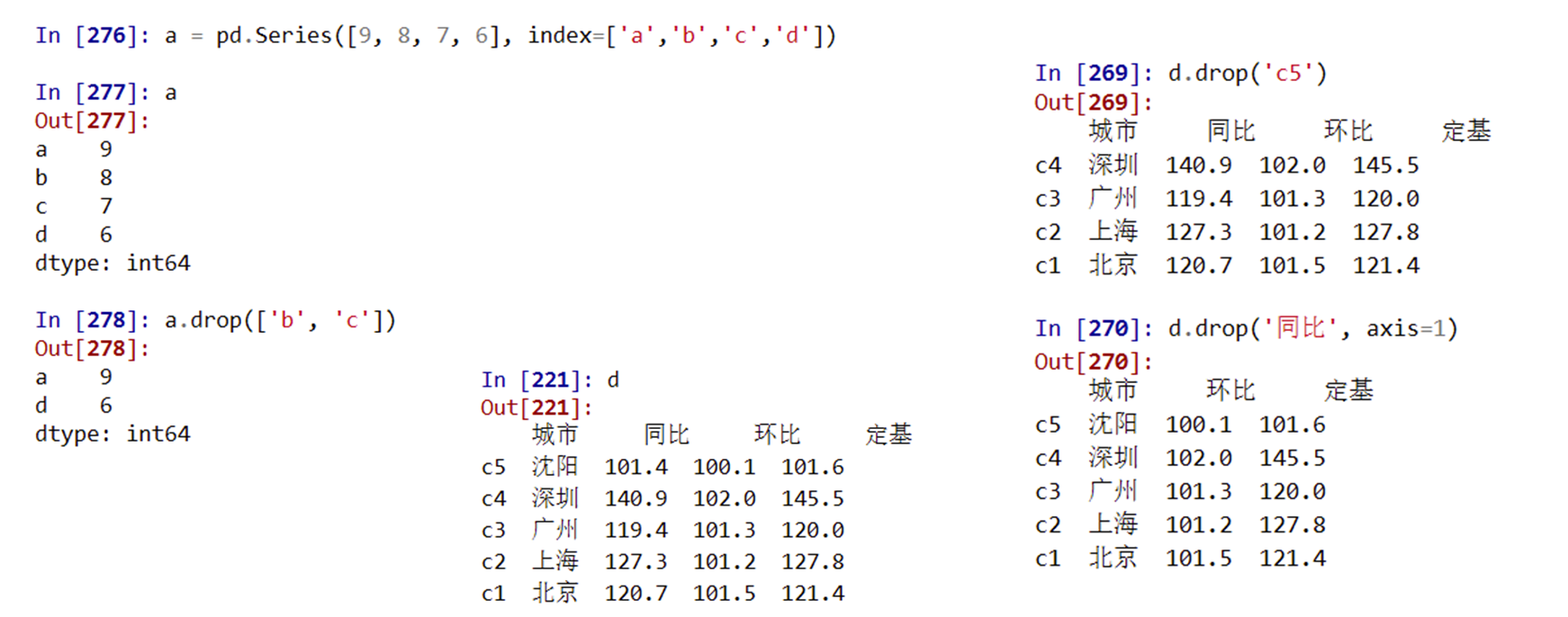
pandas删除索引
drop()能够删除Series和DataFrame指定行或列索引
pandas数据运算
- 算术运算根据行列索引,补齐后运算,运算默认产生浮点数
- 补齐时缺项填充NaN (空值)
- 二维和一维、一维和零维间为广播运算
- 采用+ ‐ * /符号进行的二元运算产生新的对象

算术运算
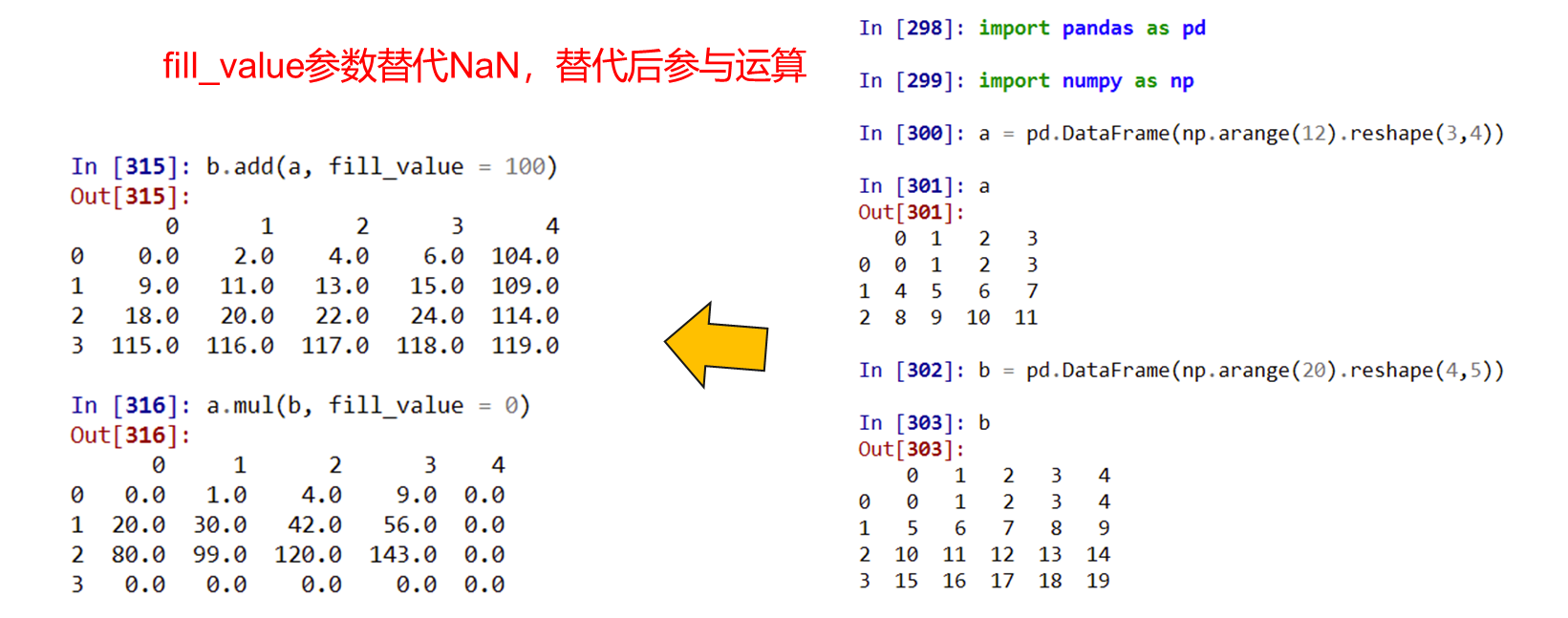
- 不同维度间为广播运算,一维Series默认在轴1参与运算
- 使用运算方法可以令一维Series参与轴0运算
Pandas数据分析
pandas导入与导出数据
导入数据
pd.read_csv(filename):从CSV文件导入数据
pd.read_table(filename):从限定分隔符的文本文件导入数据
pd.read_excel(filename):从Excel文件导入数据
pd.read_sql(query, connection_object):从SQL表/库导入数据
pd.read_json(json_string):从JSON格式的字符串导入数据
pd.read_html(url):解析URL、字符串或者HTML文件,抽取其中的tables表格
pd.read_clipboard():从你的粘贴板获取内容,并传给read_table()
pd.DataFrame(dict):从字典对象导入数据,Key是列名,Value是数据
导出数据
df.to_csv(filename):导出数据到CSV文件
df.to_excel(filename):导出数据到Excel文件
df.to_sql(table_name, connection_object):导出数据到SQL表
df.to_json(filename):以Json格式导出数据到文本文件
Pandas查看、检查数据
df.head(n):查看DataFrame对象的前n行
df.tail(n):查看DataFrame对象的最后n行
df.shape():查看行数和列数
http://df.info():查看索引、数据类型和内存信息
df.describe():查看数值型列的汇总统计
s.value_counts(dropna=False):查看Series对象的唯一值和计数
df.apply(pd.Series.value_counts):查看DataFrame对象中每一列的唯一值和计数
Pandas数据选取
df[col]:根据列名,并以Series的形式返回列
df[[col1, col2]]:以DataFrame形式返回多列
s.iloc[0]:按位置选取数据
s.loc['index_one']:按索引选取数据
df.iloc[0,:]:返回第一行
df.iloc[0,0]:返回第一列的第一个元素
pandas数据清理
df.columns = ['a','b','c']:重命名列名
pd.isnull():检查DataFrame对象中的空值,并返回一个Boolean数组
pd.notnull():检查DataFrame对象中的非空值,并返回一个Boolean数组
df.dropna():删除所有包含空值的行
df.dropna(axis=1):删除所有包含空值的列
df.dropna(axis=1,thresh=n):删除所有小于n个非空值的行
df.fillna(x):用x替换DataFrame对象中所有的空值
s.astype(float):将Series中的数据类型更改为float类型
s.replace(1,'one'):用‘one’代替所有等于1的值
s.replace([1,3],['one','three']):用'one'代替1,用'three'代替3
df.rename(columns=lambda x: x + 1):批量更改列名
df.rename(columns={'old_name': 'new_ name'}):选择性更改列名
df.set_index('column_one'):更改索引列
df.rename(index=lambda x: x + 1):批量重命名索引
Pandas数据处理
df.columns = ['a','b','c']:重命名列名
pd.isnull():检查DataFrame对象中的空值,并返回一个Boolean数组
pd.notnull():检查DataFrame对象中的非空值,并返回一个Boolean数组
df.dropna():删除所有包含空值的行
df.dropna(axis=1):删除所有包含空值的列
df.dropna(axis=1,thresh=n):删除所有小于n个非空值的行
df.fillna(x):用x替换DataFrame对象中所有的空值
s.astype(float):将Series中的数据类型更改为float类型
s.replace(1,'one'):用‘one’代替所有等于1的值
s.replace([1,3],['one','three']):用'one'代替1,用'three'代替3
df.rename(columns=lambda x: x + 1):批量更改列名
df.rename(columns={'old_name': 'new_ name'}):选择性更改列名
df.set_index('column_one'):更改索引列
df.rename(index=lambda x: x + 1):批量重命名索引
df[df[col] > 0.5]:选择col列的值大于0.5的行
df.sort_values(col1):按照列col1排序数据,默认升序排列
df.sort_values(col2, ascending=False):按照列col1降序排列数据
df.sort_values([col1,col2], ascending=[True,False]):先按列col1升序排列,后按col2降序排列数据
df.groupby(col):返回一个按列col进行分组的Groupby对象
df.groupby([col1,col2]):返回一个按多列进行分组的Groupby对象
df.groupby(col1)[col2]:返回按列col1进行分组后,列col2的均值
df.pivot_table(index=col1, values=[col2,col3], aggfunc=max):创建一个按列col1进行分组,并计算col2和col3的最大值的数据透视表
df.groupby(col1).agg(np.mean):返回按列col1分组的所有列的均值
data.apply(np.mean):对DataFrame中的每一列应用函数np.mean
data.apply(np.max,axis=1):对DataFrame中的每一行应用函数np.max
Pandas数据合并
df1.append(df2):将df2中的行添加到df1的尾部
df.concat([df1, df2],axis=1):将df2中的列添加到df1的尾部
df1.join(df2,on=col1,how='inner'):对df1的列和df2的列执行SQL形式的join
Pandas数据统计
df.describe():查看数据值列的汇总统计
df.mean():返回所有列的均值
df.corr():返回列与列之间的相关系数
df.count():返回每一列中的非空值的个数
df.max():返回每一列的最大值
df.min():返回每一列的最小值
df.median():返回每一列的中位数
df.std():返回每一列的标准差
原创作者:孤飞-博客园
原文链接:https://blog.onefly.top/posts/13141.html
Python数据分析教程(二):Pandas的更多相关文章
- Python 数据分析(二 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识
Python 数据分析(二) 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识 第1节 groupby 技术 第2节 数据聚合 第3节 分组级运算和转换 第4 ...
- Python数据分析入门之pandas基础总结
Pandas--"大熊猫"基础 Series Series: pandas的长枪(数据表中的一列或一行,观测向量,一维数组...) Series1 = pd.Series(np.r ...
- Python数据分析工具:Pandas之Series
Python数据分析工具:Pandas之Series Pandas概述Pandas是Python的一个数据分析包,该工具为解决数据分析任务而创建.Pandas纳入大量库和标准数据模型,提供高效的操作数 ...
- Python学习教程:Pandas中第二好用的函数
从网上看到一篇好的文章是关于如何学习python数据分析的迫不及待想要分享给大家,大家也可以点链接看原博客.希望对大家的学习有帮助. 本次的Python学习教程是关于Python数据分析实战基础相关内 ...
- 《Python 数据分析》笔记——pandas
Pandas pandas是一个流行的开源Python项目,其名称取panel data(面板数据)与Python data analysis(Python 数据分析)之意. pandas有两个重要的 ...
- Python数据分析(二)pandas缺失值处理
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5, 3), index=['a', 'c', 'e' ...
- Python 数据分析包:pandas 基础
pandas 是基于 Numpy 构建的含有更高级数据结构和工具的数据分析包 类似于 Numpy 的核心是 ndarray,pandas 也是围绕着 Series 和 DataFrame 两个核心数据 ...
- 快速学习 Python 数据分析包 之 pandas
最近在看时间序列分析的一些东西,中间普遍用到一个叫pandas的包,因此单独拿出时间来进行学习. 参见 pandas 官方文档 http://pandas.pydata.org/pandas-docs ...
- python数据分析三剑客之: pandas操作
pandas的操作 pandas的拼接操作 # pandas的拼接操作 级联 pd.concat , pd.append 合并 pd.merge , pd.join 一丶pd.concat()级联 # ...
随机推荐
- Windows版pytorch,torch简明安装
好消息!!目前pytorch已经提供windows官方支持,可以直接安装了,请移步这里. pytorch是facebook开发的深度学习库,其目标是想成为深度学习领域整合gpu加速的numpy.笔者研 ...
- Whats On Tap | Tapdata Cloud 如何助力大型家居连锁商城推进数字化经营?
Tapdata Cloud 的操作有多便捷,上手试一下就能充分了解了.--Tapdata Cloud 用户 | 报表实施 @某大型家居服务平台 一边是监管政策趋严,推动房地产回归本源,存量竞争时代开启 ...
- Tapdata 在“疫”线:携手张家港市卫健委争分夺秒实时抗疫
"抗疫两年以来最困难的时期,是漫长冬夜还是倒春寒?"--国家传染病医学中心主任张文宏 于3月14日凌晨 "等到疫情结束了,我一定要--",常怀这样的期许 ...
- IDEA快捷键之晨讲篇
IDEA之html快捷键 快捷键 释义 ! 生成HTML的初始格式 ---- ---- 标签名*n 生成n个相同的标签 ---- ---- 标签>标签 生成父子级标签(包含) ---- ---- ...
- 【Kaggle】如何有效避免OOM(out of memory)和漫长的炼丹过程
本文介绍一些避免transformers的OOM以及训练等流程太漫长的方法,主要参考了kaggle notebook Optimization approaches for Transformers ...
- ETL工具 (二)sqoop 数据同步工具
Sqoop简介 将关系数据库(oracle.mysql.postgresql等)数据与hadoop数据进行转换的工具. 官网: http://sqoop.apache.org/ 版本:(两个版本完全不 ...
- 86开关、家电、台扇等6键6路6感应通道高抗干扰触摸IC-VK3606D,稳定性好,抗干扰能力强
概述: VK3606D SOP16具有6个触摸按键,可用来检测外部触摸按键上人手的触摸动作.该芯片具有较高的集成度,仅需极少的外部组件便可实现触摸按键的检测.提供了6路1对1直接输出低电平有效.最长输 ...
- wdos centos64位通过yum来升级PHP
通过yum list installed | grep php可以查看所有已安装的php软件 使用yum remove php -- 将所有的包删除 通过yum list php*查看是否有自己需要安 ...
- 万答#19,MySQL可以禁用MyISAM引擎吗?
GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源. MyISAM的适用场景越来越少了. 随着MySQL 8.0的推出,系统表已经全面采用InnoDB引擎,不再需要MyISAM ...
- Redis 11 配置
参考源 https://www.bilibili.com/video/BV1S54y1R7SB?spm_id_from=333.999.0.0 版本 本文章基于 Redis 6.2.6 基本配置 Re ...