爬虫五之Selenium
Selenium
自动化测试工具,支持多种浏览器;
爬虫中主要用来解决JavaScript渲染问题。
用法详解
基本使用

声明浏览器对象
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Safari()
访问页面
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
print(browser.page_source)
browser.close()
查找元素
单个元素
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element_by_id('q')
input_second = browser.find_element_by_css_selector('#q')
input_third = browser.find_element_by_xpath('//*[@id="q"]')
print(input_first, input_second, input_third)#这些方法效果是同样的
browser.close()
一样的方法
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element(By.ID,'q')
print(input_first)
browser.close()
多个元素
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
lis = browser.find_elements_by_css_selector('.service-bd Ii')
print(lis)
browser.close()
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
lis = browser.find_elements(By.CSS_SELECTOR,'.service-bd li')
print(lis)
browser.close()
元素交互操作
对获取的元素调用交互方法

交互动作
将动作附加到动作链中串行执行

执行JavaScript
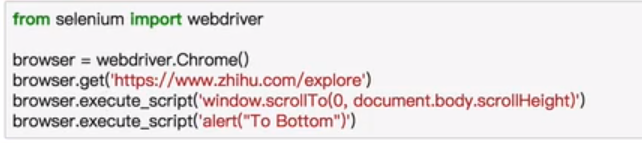
获取元素信息


Frame

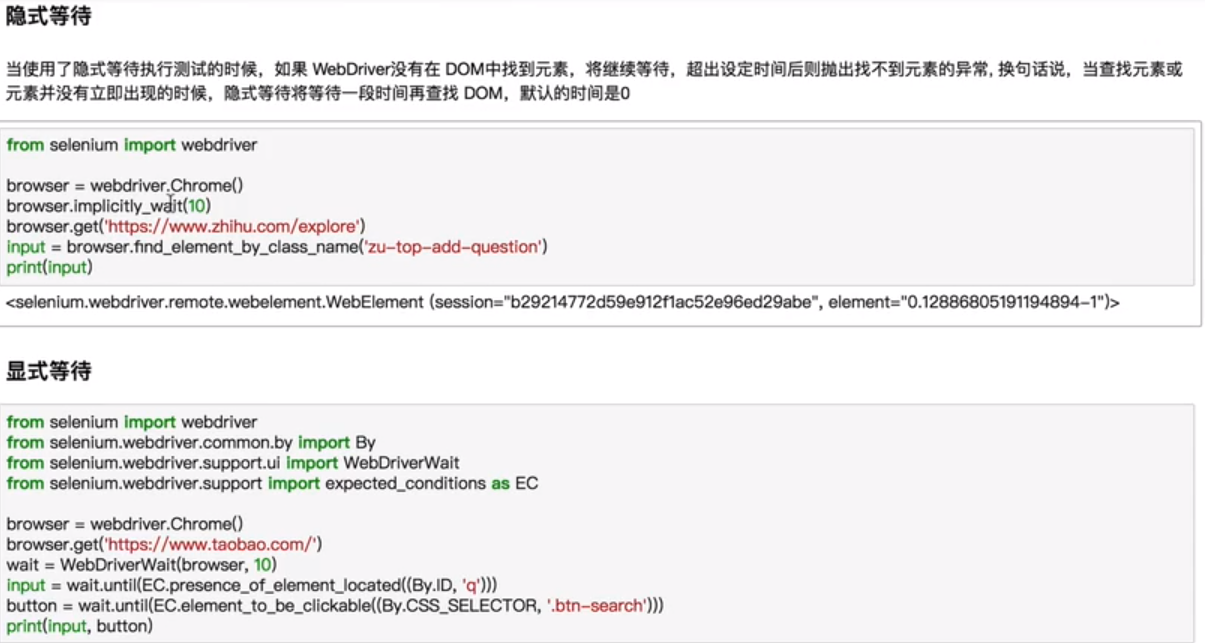
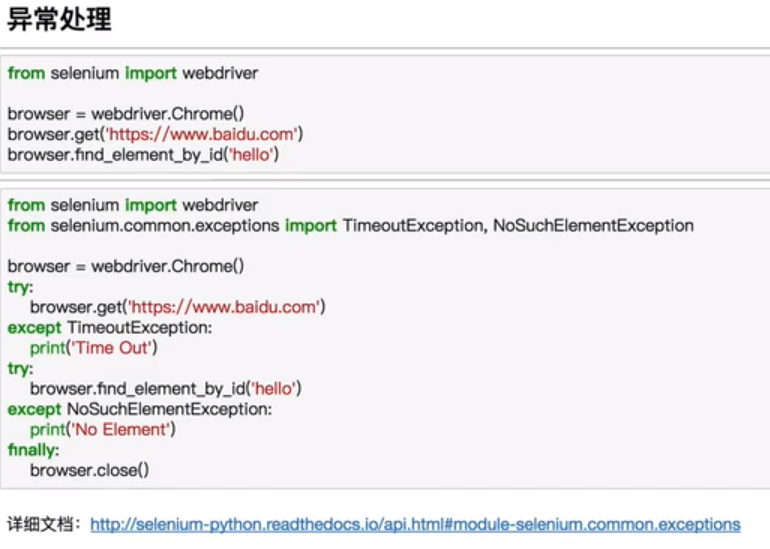
等待


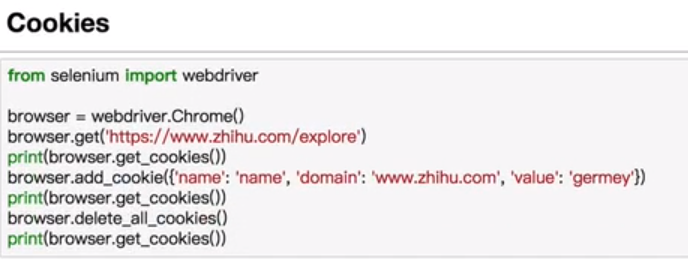
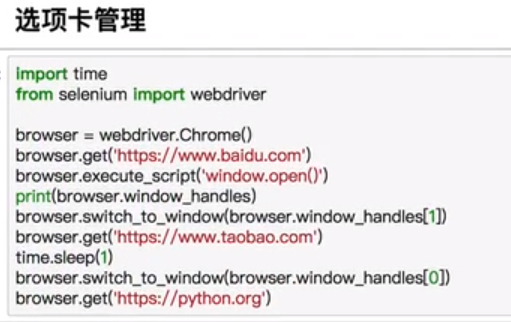
爬虫五之Selenium的更多相关文章
- Python爬虫之设置selenium webdriver等待
Python爬虫之设置selenium webdriver等待 ajax技术出现使异步加载方式呈现数据的网站越来越多,当浏览器在加载页面时,页面上的元素可能并不是同时被加载完成,这给定位元素的定位增加 ...
- python爬虫动态html selenium.webdriver
python爬虫:利用selenium.webdriver获取渲染之后的页面代码! 1 首先要下载浏览器驱动: 常用的是chromedriver 和phantomjs chromedirver下载地址 ...
- scrapy爬虫框架和selenium的配合使用
scrapy框架的请求流程 scrapy框架? Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架.因此Scrapy使用了一种非阻塞(又名异步)的 ...
- # Python3微博爬虫[requests+pyquery+selenium+mongodb]
目录 Python3微博爬虫[requests+pyquery+selenium+mongodb] 主要技术 站点分析 程序流程图 编程实现 数据库选择 代理IP测试 模拟登录 获取用户详细信息 获取 ...
- [Python爬虫] 之十五:Selenium +phantomjs根据微信公众号抓取微信文章
借助搜索微信搜索引擎进行抓取 抓取过程 1.首先在搜狗的微信搜索页面测试一下,这样能够让我们的思路更加清晰 在搜索引擎上使用微信公众号英文名进行“搜公众号”操作(因为公众号英文名是公众号唯一的,而中文 ...
- python爬虫入门(五)Selenium模拟用户操作
爬虫(Spider),反爬虫(Anti-Spider),反反爬虫(Anti-Anti-Spider) 之间恢宏壮阔的斗争... 小莫想要某站上所有的电影,写了标准的爬虫(基于HttpClient库), ...
- 爬虫(五)—— selenium模块启动浏览器自动化测试
目录 selenium模块 一.selenium介绍 二.环境搭建 三.使用selenium模块 1.使用chrome并设置为无GUI模式 2.使用chrome有GUI模式 3.查找元素 4.获取标签 ...
- Python爬虫利器五之Selenium的用法
1.简介 Selenium 是什么?一句话,自动化测试工具.它支持各种浏览器,包括 Chrome,Safari,Firefox 等主流界面式浏览器,如果你在这些浏览器里面安装一个 Selenium 的 ...
- [Python爬虫] 之二十五:Selenium +phantomjs 利用 pyquery抓取今日头条网数据
一.介绍 本例子用Selenium +phantomjs爬取今日头条(http://www.toutiao.com/search/?keyword=电视)的资讯信息,输入给定关键字抓取资讯信息. 给定 ...
随机推荐
- Spring使用@AspectJ开发AOP(零配置文件)
前言: AOP并不是Spring框架特有的.Spring只是支持AOP编程 (面向切面编程) 的框架之一. 概念: 1.切面(Aspect) 一系列Advice + Pointcut 的集合. 2.通 ...
- shell学习——关于shell函数库的使用
shell函数库的理解: 个人理解,shell函数库实质为一个脚本,脚本内包含了多个函数(函数具有普遍适用性). shell函数库的调用: 通过 . /path/lib/file.lib 或者 so ...
- MHA配置
1,背景 MHA的目的在于维持MySQL Replication中Master库的高可用性,其最大特点是可以修复多个Slave之间的差异日志,最终使所有Slave保持数据一致,然后从中选择一个充当新的 ...
- python 创建实例对象
实例化类其他编程语言中一般用关键字 new,但是在 Python 中并没有这个关键字,类的实例化类似函数调用方式. 以下使用类的名称 Employee 来实例化,并通过 __init__ 方法接收参数 ...
- C# socket 与网页通讯
class Program { static Socket _socket = new Socket(AddressFamily.InterNetwork, SocketType.Stream, Pr ...
- 【封装工程】OI/ACM常用封装
前言 笔者有的时候无聊,就将一些奇怪的东西封装起来. 范围主要是在\(OI\)或者\(ACM\)中的常见数据结构等. 随着笔者的能力的提升,可能会对原来的封装程序进行修改,并且保留原来的版本. [ST ...
- 【清华集训2016】Alice和Bob又在玩游戏
不难的题目.因为SG性质,所以只需要对一棵树求出. 然后如果发现从上往下DP不太行,所以从下往上DP. 考虑一个点对子树的合并,考虑下一个删的点在哪一个子树,那么剩下的状态实际上就是把一个子树所有能达 ...
- JavaWeb_(设计模式)单例模式
菜鸟教程 传送门 单例模式(Singleton Pattern)是 Java 中最简单的设计模式之一.这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式. 这种模式涉及到一个单一的类,该 ...
- 解决zbx的web界面zabbix服务器端运行中 显示为不(启动命令)
zabbix装完,发现server和agent服务都起来了,端口监听了,但是web界面zabbix服务器端运行中为 不 解决: 打开浏览器,到zabbix的setup.php界面 一般输入 ip/za ...
- 两个html之间进行传值,如何进行?
function turnto(){ var getval=document.getElementById("text").value; turngetval=escape(get ...