Step-by-step from Markov Process to Markov Decision Process
In this post, I will illustrate Markov Property, Markov Reward Process and finally Markov Decision Process, which are fundamental concepts in Reinforcement Learning.
Markov Property
'The state is independent of the past given the present'
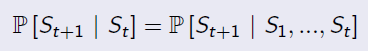
Markov Process (Markov Chain)
Keywords: state, transition matrix
A Markov Process is defined by a Tuple(S,P), in which S is the state space, and P is the transition matrix. The following chart is an example.
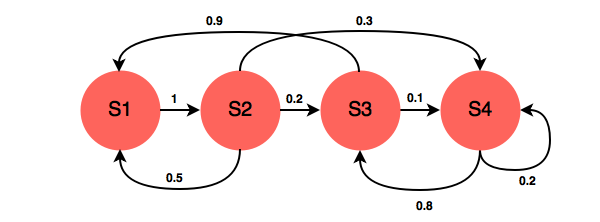
A transition matrix demonstrates the probabilities of transitioning from one state to another.


In the example above, the transition matrix is:

Markov Reward Process: Markov Process with Value Judgement
Keywords: Reward, Return, Discount Factor, Value Function
MRP add two additional properties into Markov Chain: one is Reward, who represents the immediate feedback an agent can receive at time t+1 if he is in state s at time t; another property is Discount Factor γ∈[0,1]. So the representation tuple is [S,P,R,γ].
Formally, Reward is the immediate feedback, which means when agent gets to state s at time t, it can definetly receive this reward at time t+1. It is defined by:

Given reward and discount factor, we can calculate the Return for a given senario by this equation:
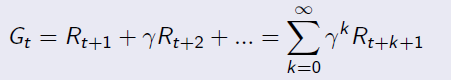
Example for Return calculation:
Senario: Class1->Class2->Class3->Pass->Sleep, and the agent is at state=Class1.
Case 1: when gamma=0, g=-2+(-2)*0+(-2)*0+10*0=-2
Case 2: when gamma=1, g=-2+(-2)*1+(-2)*1+10*1=4
Case 3: when gamma=0.8, g=-2+(-2)*0.8+(-2)*0.64+10*=-4-1.6+5.12=-0.48
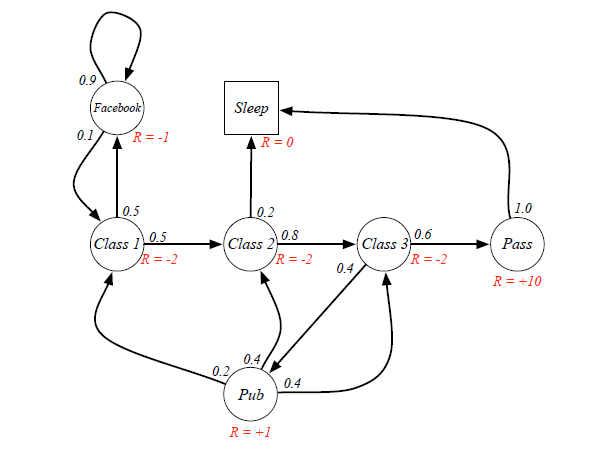
From different γ, we know our agent can be exetremely short-sighted (far-sighted) only for immediate reward, or trying to seek balance between short and long term reward.
When an agent is in a certain state, the way to measure the total reward from this state over time is calculating expected Returns for all possible senarios. The function to calculate it is called Value Function:
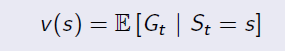
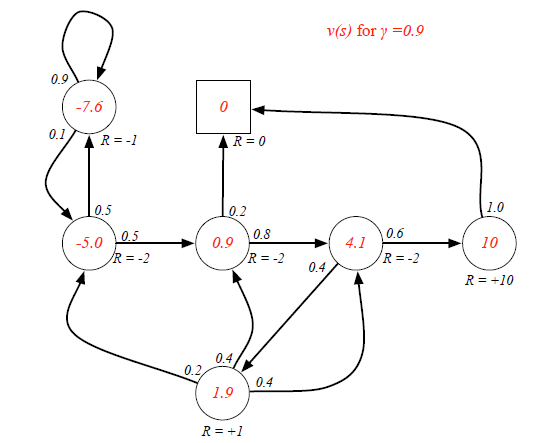
Ex. If the agent is at Class3 state, it has 0.6 and 0.4 probabilities to transite to Pass and Pub respectively. Because there are loops inside the graph, it's difficult to directly derive expected return from value function. (Forget the red labeled value, they are result...)
Bellman Equation helps to solve this complexity:
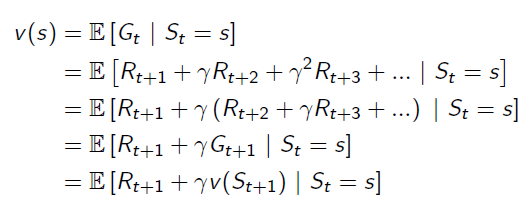
It breaks the value function into two parts: Immediate Reward and Future Reward: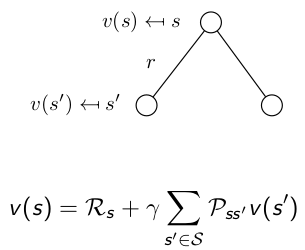 The future reward is discounted by γ, and it has probabilities on different states, so actually the future reward is an expectation.
The future reward is discounted by γ, and it has probabilities on different states, so actually the future reward is an expectation.
Now we can use Bellman Equation to solve value function: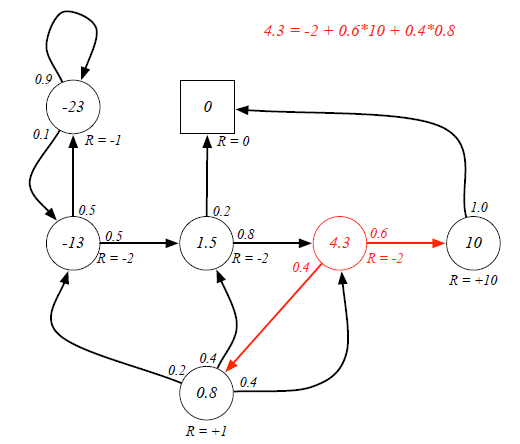
Markov Decision Process: MRP with Actions
Keywords: Action
Markov Decision Process adds more complexity onto MRP, it is defined by a tuple(S,A,P,R,γ), in which:
S is state space, and γ is discount factor, they are same as MRP.
A is a finite set of Actions, which is new. Then because of the existense of Action, Transition Matrix and Reward Function are all conditional on both State and Action.
P is State Transition Matrix: it is conditional on state and action at time t, which means different actions would result in different distribution of state at time t+1.
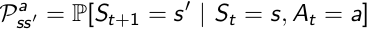
R is Reward Function conditional upon state and action: also, different actions lead to different reward, despite of the same state s.
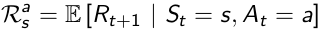
A graph(from Wikipedia) helps understanding the role of actions:
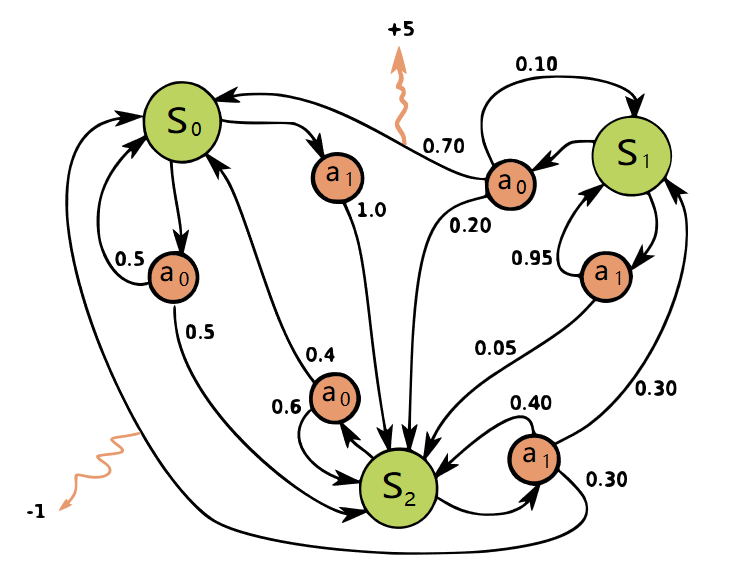
So by now, we have already had the model of the environment: all states, all possible actions and transition matrix conditional on state and actions.
Step-by-step from Markov Process to Markov Decision Process的更多相关文章
- Step by step Process of creating APD
Step by step Process of creating APD: Business Scenario: Here we are going to create an APD on top o ...
- Step by Step Process of Migrating non-CDBs and PDBs Using ASM for File Storage (Doc ID 1576755.1)
Step by Step Process of Migrating non-CDBs and PDBs Using ASM for File Storage (Doc ID 1576755.1) AP ...
- Tomcat Clustering - A Step By Step Guide --转载
Tomcat Clustering - A Step By Step Guide Apache Tomcat is a great performer on its own, but if you'r ...
- [ZZ] Understanding 3D rendering step by step with 3DMark11 - BeHardware >> Graphics cards
http://www.behardware.com/art/lire/845/ --> Understanding 3D rendering step by step with 3DMark11 ...
- e2e 自动化集成测试 架构 实例 WebStorm Node.js Mocha WebDriverIO Selenium Step by step (二) 图片验证码的识别
上一篇文章讲了“e2e 自动化集成测试 架构 京东 商品搜索 实例 WebStorm Node.js Mocha WebDriverIO Selenium Step by step 一 京东 商品搜索 ...
- Code Understanding Step by Step - We Need a Task
Code understanding is a task we are always doing, though we are not even aware that we're doing it ...
- enode框架step by step之saga的思想与实现
enode框架step by step之saga的思想与实现 enode框架系列step by step文章系列索引: 分享一个基于DDD以及事件驱动架构(EDA)的应用开发框架enode enode ...
- 课程五(Sequence Models),第一 周(Recurrent Neural Networks) —— 1.Programming assignments:Building a recurrent neural network - step by step
Building your Recurrent Neural Network - Step by Step Welcome to Course 5's first assignment! In thi ...
- 精通initramfs构建step by step
(一)hello world 一.initramfs是什么 在2.6版本的linux内核中,都包含一个压缩过的cpio格式 的打包文件.当内核启动时,会从这个打包文件中导出文件到内核的rootfs ...
随机推荐
- PTA第二题
#include<string.h> #include<stdio.h> #include<malloc.h> ]; ][]={"ling",& ...
- Java7/8 中的 HashMap 和 ConcurrentHashMap 全解析 (转)
阅读前提:本文分析的是源码,所以至少读者要熟悉它们的接口使用,同时,对于并发,读者至少要知道 CAS.ReentrantLock.UNSAFE 操作这几个基本的知识,文中不会对这些知识进行介绍.Jav ...
- P2731 骑马修栅栏 (欧拉路径)
[题目描述] John是一个与其他农民一样懒的人.他讨厌骑马,因此从来不两次经过一个栅栏.你必须编一个程序,读入栅栏网络的描述,并计算出一条修栅栏的路径,使每个栅栏都恰好被经过一次.John能从任何一 ...
- Python pass是空语句用法
在条件判断,还是函数中,有时候不需要输出任何东西,也不能留空,python提供空的语句,下面讲述pass空语句的用法 1,关键词 pass 2,用法 for letter in 'Python': i ...
- SSH简单概念
Spring:轻量级控制反转(IoC)和面向切面(AOP)的容器框架,让对象与对象之间的关系通过配置文件来管理,减低耦合度 IoC:凡是在容器中配置过的对象才会有Spring提供的服务和功能 AOP: ...
- JVM 运行时数据区域划分
目录 前言 什么是JVM JRE/JDK/JVM是什么关系 JVM执行程序的过程 JVM的生命周期 JVM垃圾回收 JVM的内存区域划分 一.运行时数据区包括哪几部分? 二.运行时数据区的每部分到底存 ...
- linux设定 runlevel 3
runlevel 查看当前系统运行级别 vi /etc/inittab //运行级别配置文件
- 【转】SPI FLASH与NOR FLASH的区别 详解SPI FLASH与NOR FLASH的不一样
转自:http://m.elecfans.com/article/778203.html 本文主要是关于SPI FLASH与NOR FLASH的相关介绍,并着重对SPI FLASH与NOR FLASH ...
- 快速排序的python实现
def quick_sort(array, left, right): if left < right: base_index = division(array, left, right) qu ...
- BZOJ2588 树上静态第k大
题意翻译 给你一棵有n个结点的树,节点编号为1~n. 每个节点都有一个权值. 要求执行以下操作: U V K:求从节点u到节点v的第k小权值. 输入输出格式 输入格式 第一行有两个整数n和m(n,m≤ ...