Temporal-Difference Learning for Prediction
In Monte Carlo Learning, we've got the estimation of value function:
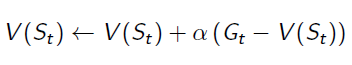
Gt is the episode return from time t, which can be calculated by:
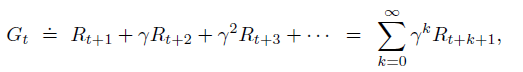
Please recall, Gt can be only calculated at the end of a given episode. This reveals a disadvantage of Monte Carlo Learning: have to wait until the end of episodes.
TD(0) algorithm replace Gt of the equation to the immediate reward and estimated value function of the next state:
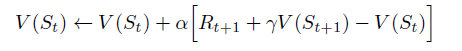
The algorithm updates the Estimated State-Value Function at time t+1, because everything in the equation is determined. This means we will wait until the agent reaching the next state, so that the agent can get the immediate reward Rt+1 and know which state the system will transition to at time t+1.
The equations below are State-Value Function for Dynamic Programming, in which the whole environment is known. Compare to these equations:
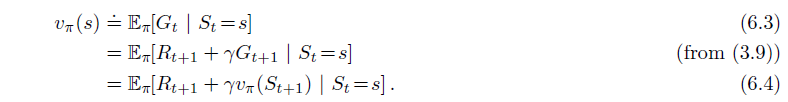
TD algorithm is quite like 6.4 Bellman Equation, but it does not take expectation. Instead, it uses the knowledge till now to estimate how much reward I am going to get from this state. The whole algorithm can be demonstrated as:

TD Target, TD Error
Bias/ Viriance trade-off
Bootstraping
Temporal-Difference Learning for Prediction的更多相关文章
- 【PPT】 Least squares temporal difference learning
最小二次方时序差分学习 原文地址: https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd= ...
- PP: Multi-Horizon Time Series Forecasting with Temporal Attention Learning
Problem: multi-horizon probabilistic forecasting tasks; Propose an end-to-end framework for multi-ho ...
- [Reinforcement Learning] Model-Free Prediction
上篇文章介绍了 Model-based 的通用方法--动态规划,本文内容介绍 Model-Free 情况下 Prediction 问题,即 "Estimate the value funct ...
- [Machine Learning] 机器学习常见算法分类汇总
声明:本篇博文根据http://www.ctocio.com/hotnews/15919.html整理,原作者张萌,尊重原创. 机器学习无疑是当前数据分析领域的一个热点内容.很多人在平时的工作中都或多 ...
- (转) Deep Learning Research Review Week 2: Reinforcement Learning
Deep Learning Research Review Week 2: Reinforcement Learning 转载自: https://adeshpande3.github.io/ad ...
- Awesome Reinforcement Learning
Awesome Reinforcement Learning A curated list of resources dedicated to reinforcement learning. We h ...
- Machine Learning 学习笔记1 - 基本概念以及各分类
What is machine learning? 并没有广泛认可的定义来准确定义机器学习.以下定义均为译文,若以后有时间,将补充原英文...... 定义1.来自Arthur Samuel(上世纪50 ...
- Distributional Reinforcement Learning with Quantile Regression
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! arXiv:1710.10044v1 [cs.AI] 27 Oct 2017 In AAAI Conference on Artifici ...
- 3. Distributional Reinforcement Learning with Quantile Regression
C51算法理论上用Wasserstein度量衡量两个累积分布函数间的距离证明了价值分布的可行性,但在实际算法中用KL散度对离散支持的概率进行拟合,不能作用于累积分布函数,不能保证Bellman更新收敛 ...
随机推荐
- verilog版插值
开发环境:IDE:LIBERO 9.0(ACTEL公司的)芯片:AFS600 (BGA256),是混合系列的FPGA仿真软件:modelsim atcel 6.5d综合软件:synplify pr ...
- 复试笔试复习 & bd面试总结
计算机网络: 1.OSI模型中提供端到端服务的是传输层 2.波特率的含义是每秒钟信号变化的次数 3.非屏蔽双绞线中5类网线的数据速率为100Mbps,连接器是RJ-45 4.虚电路在数据链路层实现,电 ...
- MySQL新增用户及赋予权限
创建用户 USE mysql; #创建用户需要操作 mysql 表 # 语法格式为 [@'host'] host 为 'localhost' 表示本地登录用户,host 为 IP地址或 IP 地址区间 ...
- [每日一讲] Python系列:Python概述
Python 序章 概述 Python 是弱类型动态解释型的面向对象高级语言,其具备面向对象的三大特点:封装.继承.多态.Python 代码运行时,其有一个编译过程,通过编译器生成 .pyc 字节码 ...
- UITableView和MJReFresh结合使用问题记录
1. 代码主动调用下拉刷新, [self.tableView.mj_header beginRefreshing]; 调用会走: [MJRefreshNormalHeader headerWithRe ...
- Java——容器(Collection)
Collection是一个接口,定义了一系列的方法. [常见方法]
- ZeroMQ的进阶
上一篇博文我们对ZeroMQ的经典模式做了写Demo让他跑起来了,但实际开发中我们可能面临一些远比上述复杂的场景.这时候我们需要进一步的对经典模式进行扩展,所幸ZeroMQ已经为我们做好了准备工作. ...
- [洛谷2257]YY的GCD 题解
整理题目转化为数学语言 题目要我们求: \[\sum_{i=1}^n\sum_{i=1}^m[gcd(i,j)=p]\] 其中 \[p\in\text{质数集合}\] 这样表示显然不是很好,所以我们需 ...
- 为什么阿里巴巴要禁用Executors创建线程池?
作者:何甜甜在吗 juejin.im/post/5dc41c165188257bad4d9e69 看阿里巴巴开发手册并发编程这块有一条:线程池不允许使用Executors去创建,而是通过ThreadP ...
- Ubuntu安装过程中的问题
1.win10系统安装32bit ubuntu,使用VM安装ubuntu 的iso文件,刚启动不停按F2,进入BIOS,boot设置为 CD-ROM drive 2.安装界面都没有出现,电脑老是重启, ...